5 posts tagged “groq”
2025
Kimi-K2-Instruct-0905. New not-quite-MIT licensed model from Chinese Moonshot AI, a follow-up to the highly regarded Kimi-K2 model they released in July.
This one is an incremental improvement - I've seen it referred to online as "Kimi K-2.1". It scores a little higher on a bunch of popular coding benchmarks, reflecting Moonshot's claim that it "demonstrates significant improvements in performance on public benchmarks and real-world coding agent tasks".
More importantly the context window size has been increased from 128,000 to 256,000 tokens.
Like its predecessor this is a big model - 1 trillion parameters in a mixture-of-experts configuration with 384 experts, 32B activated parameters and 8 selected experts per token.
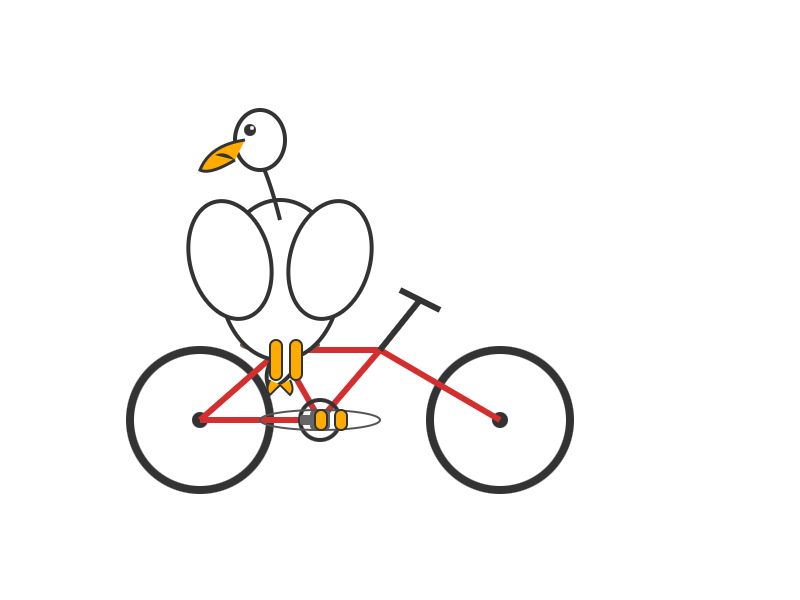
I used Groq's playground tool to try "Generate an SVG of a pelican riding a bicycle" and got this result, at a very healthy 445 tokens/second taking just under 2 seconds total:
Initial impressions of Llama 4
Dropping a model release as significant as Llama 4 on a weekend is plain unfair! So far the best place to learn about the new model family is this post on the Meta AI blog. They’ve released two new models today: Llama 4 Maverick is a 400B model (128 experts, 17B active parameters), text and image input with a 1 million token context length. Llama 4 Scout is 109B total parameters (16 experts, 17B active), also multi-modal and with a claimed 10 million token context length—an industry first.
[... 1,468 words]2024
Introducing Llama-3-Groq-Tool-Use Models (via) New from Groq: two custom fine-tuned Llama 3 models specifically designed for tool use. Hugging Face model links:
Groq's own internal benchmarks put their 70B model at the top of the Berkeley Function-Calling Leaderboard with a score of 90.76 (and 89.06 for their 8B model, which would put it at #3). For comparison, Claude 3.5 Sonnet scores 90.18 and GPT-4-0124 scores 88.29.
The two new Groq models are also available through their screamingly-fast (fastest in the business?) API, running at 330 tokens/s and 1050 tokens/s respectively.
Here's the documentation on how to use tools through their API.
Fast groq-hosted LLMs vs browser jank (via) Groq is now serving LLMs such as Llama 3 so quickly that JavaScript which attempts to render Markdown strings on every new token can cause performance issues in browsers.
Taras Glek's solution was to move the rendering to a requestAnimationFrame() callback, effectively buffering the rendering to the fastest rate the browser can support.
Options for accessing Llama 3 from the terminal using LLM
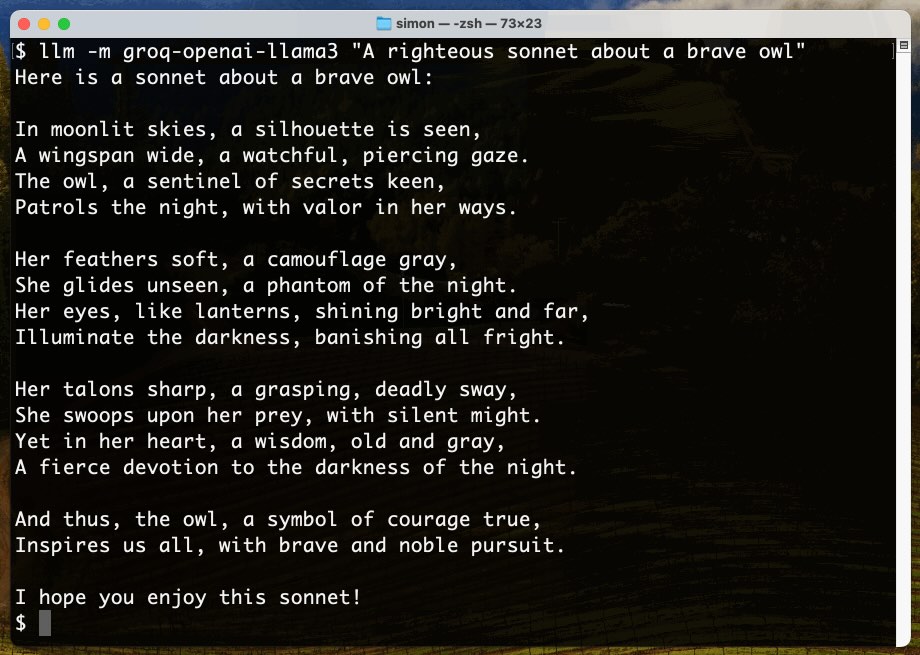
Llama 3 was released on Thursday. Early indications are that it’s now the best available openly licensed model—Llama 3 70b Instruct has taken joint 5th place on the LMSYS arena leaderboard, behind only Claude 3 Opus and some GPT-4s and sharing 5th place with Gemini Pro and Claude 3 Sonnet. But unlike those other models Llama 3 70b is weights available and can even be run on a (high end) laptop!
[... 1,962 words]