9 posts tagged “kimi”
2026
I wrote about Dan Woods' experiments with streaming experts the other day, the trick where you run larger Mixture-of-Experts models on hardware that doesn't have enough RAM to fit the entire model by instead streaming the necessary expert weights from SSD for each token that you process.
Five days ago Dan was running Qwen3.5-397B-A17B in 48GB of RAM. Today @seikixtc reported running the colossal Kimi K2.5 - a 1 trillion parameter model with 32B active weights at any one time, in 96GB of RAM on an M2 Max MacBook Pro.
And @anemll showed that same Qwen3.5-397B-A17B model running on an iPhone, albeit at just 0.6 tokens/second - iOS repo here.
I think this technique has legs. Dan and his fellow tinkerers are continuing to run autoresearch loops in order to find yet more optimizations to squeeze more performance out of these models.
Update: Now Daniel Isaac got Kimi K2.5 working on a 128GB M4 Max at ~1.7 tokens/second.
Congrats to the @cursor_ai team on the launch of Composer 2!
We are proud to see Kimi-k2.5 provide the foundation. Seeing our model integrated effectively through Cursor's continued pretraining & high-compute RL training is the open model ecosystem we love to support.
Note: Cursor accesses Kimi-k2.5 via @FireworksAI_HQ hosted RL and inference platform as part of an authorized commercial partnership.
— Kimi.ai @Kimi_Moonshot, responding to reports that Composer 2 was built on top of Kimi K2.5
Kimi K2.5: Visual Agentic Intelligence (via) Kimi K2 landed in July as a 1 trillion parameter open weight LLM. It was joined by Kimi K2 Thinking in November which added reasoning capabilities. Now they've made it multi-modal: the K2 models were text-only, but the new 2.5 can handle image inputs as well:
Kimi K2.5 builds on Kimi K2 with continued pretraining over approximately 15T mixed visual and text tokens. Built as a native multimodal model, K2.5 delivers state-of-the-art coding and vision capabilities and a self-directed agent swarm paradigm.
The "self-directed agent swarm paradigm" claim there means improved long-sequence tool calling and training on how to break down tasks for multiple agents to work on at once:
For complex tasks, Kimi K2.5 can self-direct an agent swarm with up to 100 sub-agents, executing parallel workflows across up to 1,500 tool calls. Compared with a single-agent setup, this reduces execution time by up to 4.5x. The agent swarm is automatically created and orchestrated by Kimi K2.5 without any predefined subagents or workflow.
I used the OpenRouter Chat UI to have it "Generate an SVG of a pelican riding a bicycle", and it did quite well:

As a more interesting test, I decided to exercise the claims around multi-agent planning with this prompt:
I want to build a Datasette plugin that offers a UI to upload files to an S3 bucket and stores information about them in a SQLite table. Break this down into ten tasks suitable for execution by parallel coding agents.
Here's the full response. It produced ten realistic tasks and reasoned through the dependencies between them. For comparison here's the same prompt against Claude Opus 4.5 and against GPT-5.2 Thinking.
The Hugging Face repository is 595GB. The model uses Kimi's janky "modified MIT" license, which adds the following clause:
Our only modification part is that, if the Software (or any derivative works thereof) is used for any of your commercial products or services that have more than 100 million monthly active users, or more than 20 million US dollars (or equivalent in other currencies) in monthly revenue, you shall prominently display "Kimi K2.5" on the user interface of such product or service.
Given the model's size, I expect one way to run it locally would be with MLX and a pair of $10,000 512GB RAM M3 Ultra Mac Studios. That setup has been demonstrated to work with previous trillion parameter K2 models.
2025
Kimi K2 Thinking. Chinese AI lab Moonshot's Kimi K2 established itself as one of the largest open weight models - 1 trillion parameters - back in July. They've now released the Thinking version, also a trillion parameters (MoE, 32B active) and also under their custom modified (so not quite open source) MIT license.
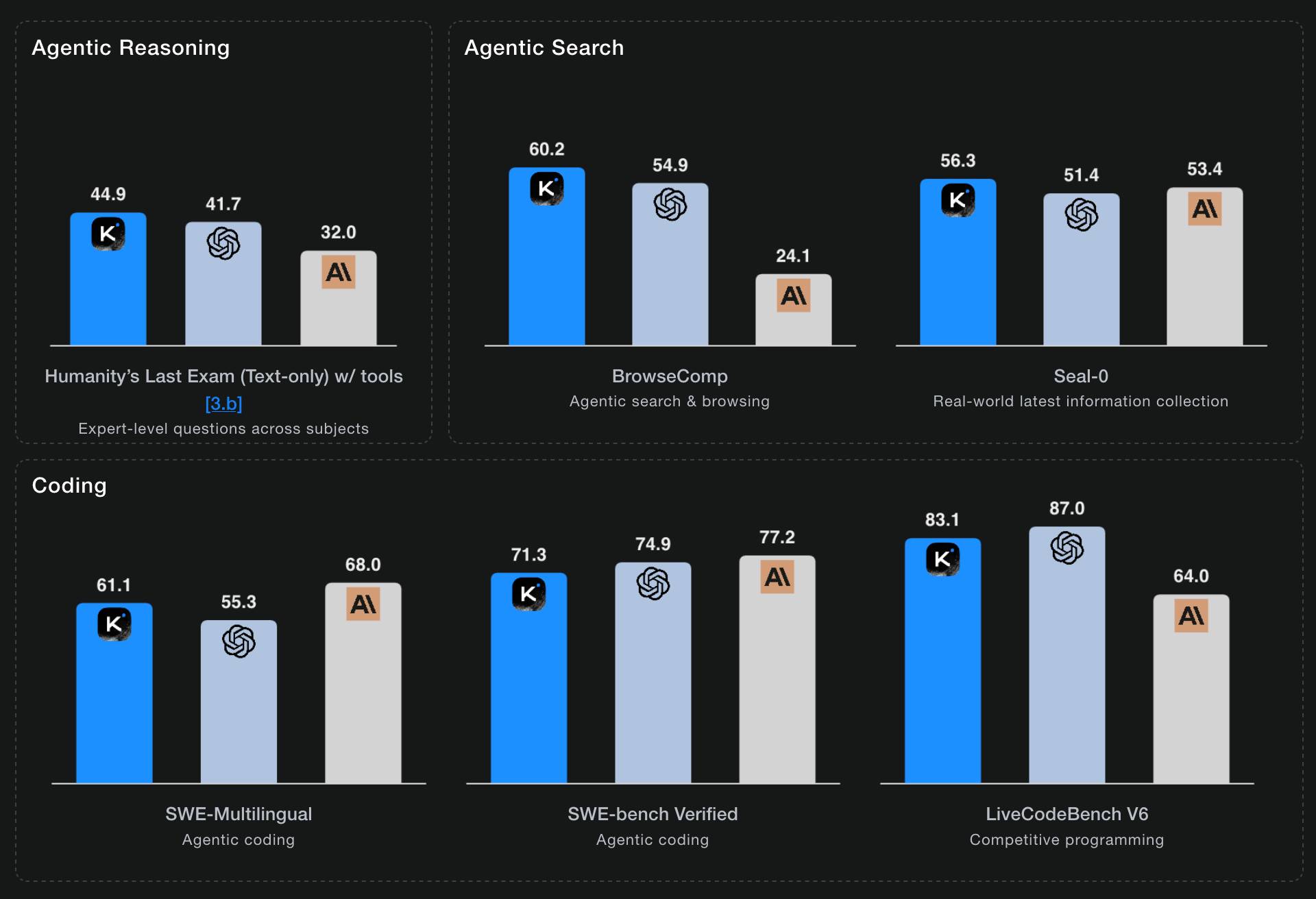
Starting with Kimi K2, we built it as a thinking agent that reasons step-by-step while dynamically invoking tools. It sets a new state-of-the-art on Humanity's Last Exam (HLE), BrowseComp, and other benchmarks by dramatically scaling multi-step reasoning depth and maintaining stable tool-use across 200–300 sequential calls. At the same time, K2 Thinking is a native INT4 quantization model with 256k context window, achieving lossless reductions in inference latency and GPU memory usage.
This one is only 594GB on Hugging Face - Kimi K2 was 1.03TB - which I think is due to the new INT4 quantization. This makes the model both cheaper and faster to host.
So far the only people hosting it are Moonshot themselves. I tried it out both via their own API and via the OpenRouter proxy to it, via the llm-moonshot plugin (by NickMystic) and my llm-openrouter plugin respectively.
The buzz around this model so far is very positive. Could this be the first open weight model that's competitive with the latest from OpenAI and Anthropic, especially for long-running agentic tool call sequences?
Moonshot AI's self-reported benchmark scores show K2 Thinking beating the top OpenAI and Anthropic models (GPT-5 and Sonnet 4.5 Thinking) at "Agentic Reasoning" and "Agentic Search" but not quite top for "Coding":
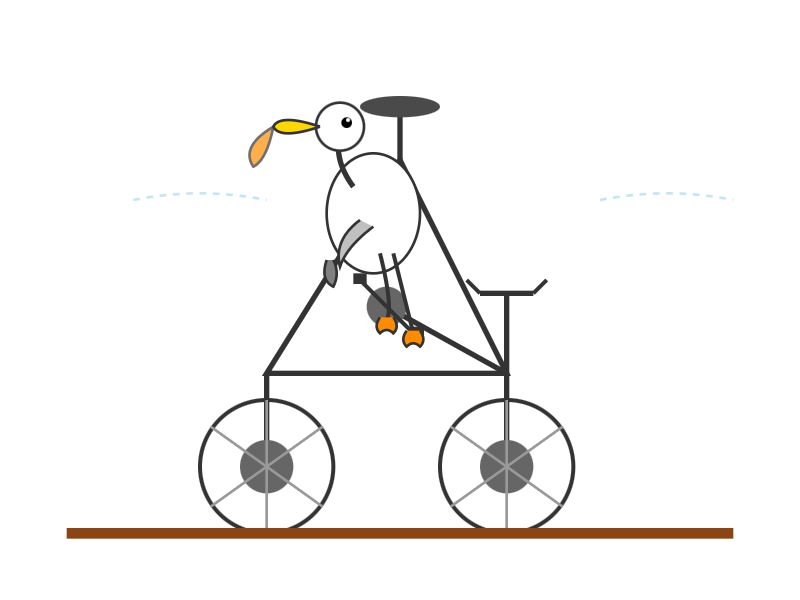
I ran a couple of pelican tests:
llm install llm-moonshot
llm keys set moonshot # paste key
llm -m moonshot/kimi-k2-thinking 'Generate an SVG of a pelican riding a bicycle'

llm install llm-openrouter
llm keys set openrouter # paste key
llm -m openrouter/moonshotai/kimi-k2-thinking \
'Generate an SVG of a pelican riding a bicycle'
Artificial Analysis said:
Kimi K2 Thinking achieves 93% in 𝜏²-Bench Telecom, an agentic tool use benchmark where the model acts as a customer service agent. This is the highest score we have independently measured. Tool use in long horizon agentic contexts was a strength of Kimi K2 Instruct and it appears this new Thinking variant makes substantial gains
CNBC quoted a source who provided the training price for the model:
The Kimi K2 Thinking model cost $4.6 million to train, according to a source familiar with the matter. [...] CNBC was unable to independently verify the DeepSeek or Kimi figures.
MLX developer Awni Hannun got it working on two 512GB M3 Ultra Mac Studios:
The new 1 Trillion parameter Kimi K2 Thinking model runs well on 2 M3 Ultras in its native format - no loss in quality!
The model was quantization aware trained (qat) at int4.
Here it generated ~3500 tokens at 15 toks/sec using pipeline-parallelism in mlx-lm
Here's the 658GB mlx-community model.
At the start of the year, most people loosely following AI probably knew of 0 [Chinese] AI labs. Now, and towards wrapping up 2025, I’d say all of DeepSeek, Qwen, and Kimi are becoming household names. They all have seasons of their best releases and different strengths. The important thing is this’ll be a growing list. A growing share of cutting edge mindshare is shifting to China. I expect some of the likes of Z.ai, Meituan, or Ant Ling to potentially join this list next year. For some of these labs releasing top tier benchmark models, they literally started their foundation model effort after DeepSeek. It took many Chinese companies only 6 months to catch up to the open frontier in ballpark of performance, now the question is if they can offer something in a niche of the frontier that has real demand for users.
— Nathan Lambert, 5 Thoughts on Kimi K2 Thinking
Kimi-K2-Instruct-0905. New not-quite-MIT licensed model from Chinese Moonshot AI, a follow-up to the highly regarded Kimi-K2 model they released in July.
This one is an incremental improvement - I've seen it referred to online as "Kimi K-2.1". It scores a little higher on a bunch of popular coding benchmarks, reflecting Moonshot's claim that it "demonstrates significant improvements in performance on public benchmarks and real-world coding agent tasks".
More importantly the context window size has been increased from 128,000 to 256,000 tokens.
Like its predecessor this is a big model - 1 trillion parameters in a mixture-of-experts configuration with 384 experts, 32B activated parameters and 8 selected experts per token.
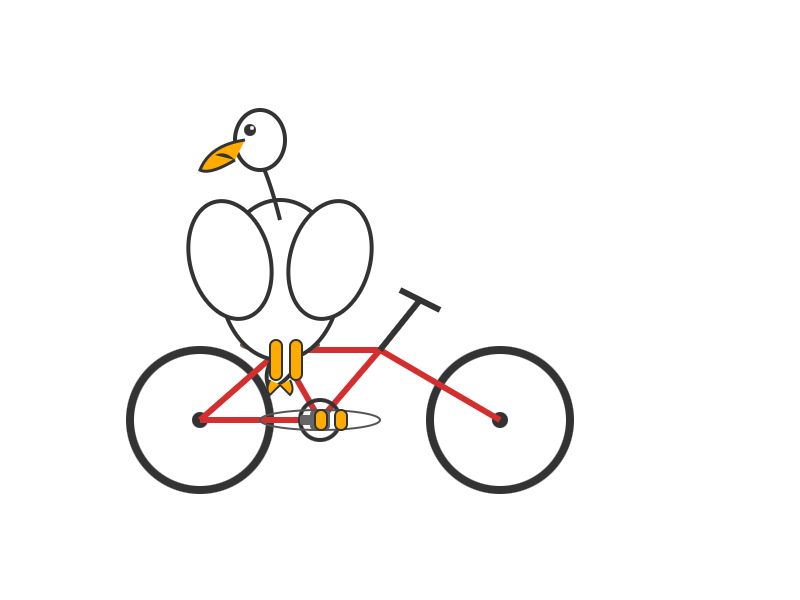
I used Groq's playground tool to try "Generate an SVG of a pelican riding a bicycle" and got this result, at a very healthy 445 tokens/second taking just under 2 seconds total:
Two interesting examples of inference speed as a flagship feature of LLM services today.
First, Cerebras announced two new monthly plans for their extremely high speed hosted model service: Cerebras Code Pro ($50/month, 1,000 messages a day) and Cerebras Code Max ($200/month, 5,000/day). The model they are selling here is Qwen's Qwen3-Coder-480B-A35B-Instruct, likely the best available open weights coding model right now and one that was released just ten days ago. Ten days from model release to third-party subscription service feels like some kind of record.
Cerebras claim they can serve the model at an astonishing 2,000 tokens per second - four times the speed of Claude Sonnet 4 in their demo video.
Also today, Moonshot announced a new hosted version of their trillion parameter Kimi K2 model called kimi-k2-turbo-preview:
🆕 Say hello to kimi-k2-turbo-preview Same model. Same context. NOW 4× FASTER.
⚡️ From 10 tok/s to 40 tok/s.
💰 Limited-Time Launch Price (50% off until Sept 1)
- $0.30 / million input tokens (cache hit)
- $1.20 / million input tokens (cache miss)
- $5.00 / million output tokens
👉 Explore more: platform.moonshot.ai
This is twice the price of their regular model for 4x the speed (increasing to 4x the price in September). No details yet on how they achieved the speed-up.
I am interested to see how much market demand there is for faster performance like this. I've experimented with Cerebras in the past and found that the speed really does make iterating on code with live previews feel a whole lot more interactive.
Something that has become undeniable this month is that the best available open weight models now come from the Chinese AI labs.
I continue to have a lot of love for Mistral, Gemma and Llama but my feeling is that Qwen, Moonshot and Z.ai have positively smoked them over the course of July.
Here's what came out this month, with links to my notes on each one:
- Moonshot Kimi-K2-Instruct - 11th July, 1 trillion parameters
- Qwen Qwen3-235B-A22B-Instruct-2507 - 21st July, 235 billion
- Qwen Qwen3-Coder-480B-A35B-Instruct - 22nd July, 480 billion
- Qwen Qwen3-235B-A22B-Thinking-2507 - 25th July, 235 billion
- Z.ai GLM-4.5 and GLM-4.5 Air - 28th July, 355 and 106 billion
- Qwen Qwen3-30B-A3B-Instruct-2507 - 29th July, 30 billion
- Qwen Qwen3-30B-A3B-Thinking-2507 - 30th July, 30 billion
- Qwen Qwen3-Coder-30B-A3B-Instruct - 31st July, 30 billion (released after I first posted this note)
Notably absent from this list is DeepSeek, but that's only because their last model release was DeepSeek-R1-0528 back in April.
The only janky license among them is Kimi K2, which uses a non-OSI-compliant modified MIT. Qwen's models are all Apache 2 and Z.ai's are MIT.
The larger Chinese models all offer their own APIs and are increasingly available from other providers. I've been able to run versions of the Qwen 30B and GLM-4.5 Air 106B models on my own laptop.
I can't help but wonder if part of the reason for the delay in release of OpenAI's open weights model comes from a desire to be notably better than this truly impressive lineup of Chinese models.
Update August 5th 2025: The OpenAI open weight models came out and they are very impressive.
moonshotai/Kimi-K2-Instruct (via) Colossal new open weights model release today from Moonshot AI, a two year old Chinese AI lab with a name inspired by Pink Floyd’s album The Dark Side of the Moon.
My HuggingFace storage calculator says the repository is 958.52 GB. It's a mixture-of-experts model with "32 billion activated parameters and 1 trillion total parameters", trained using the Muon optimizer as described in Moonshot's joint paper with UCLA Muon is Scalable for LLM Training.
I think this may be the largest ever open weights model? DeepSeek v3 is 671B.
I created an API key for Moonshot, added some dollars and ran a prompt against it using my LLM tool. First I added this to the extra-openai-models.yaml file:
- model_id: kimi-k2
model_name: kimi-k2-0711-preview
api_base: https://api.moonshot.ai/v1
api_key_name: moonshot
Then I set the API key:
llm keys set moonshot
# Paste key here
And ran a prompt:
llm -m kimi-k2 "Generate an SVG of a pelican riding a bicycle" \
-o max_tokens 2000
(The default max tokens setting was too short.)
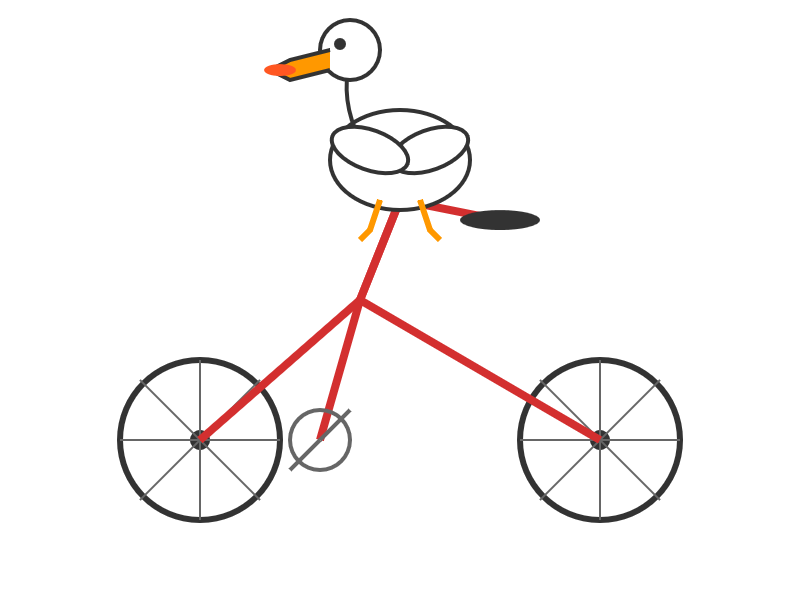
This is pretty good! The spokes are a nice touch. Full transcript here.
This one is open weights but not open source: they're using a modified MIT license with this non-OSI-compliant section tagged on at the end:
Our only modification part is that, if the Software (or any derivative works thereof) is used for any of your commercial products or services that have more than 100 million monthly active users, or more than 20 million US dollars (or equivalent in other currencies) in monthly revenue, you shall prominently display "Kimi K2" on the user interface of such product or service.
Update: MLX developer Awni Hannun reports:
The new Kimi K2 1T model (4-bit quant) runs on 2 512GB M3 Ultras with mlx-lm and mx.distributed.
1 trillion params, at a speed that's actually quite usable