617 posts tagged “llm”
LLM is my command-line tool for running prompts against Large Language Models.
2026
I'm trying to get braver at releasing 1.0 versions. This little library is a year and a half old now - I've applied some sensible and non-disruptive fixes and shipped the big 1.0 for it.
Here's an example of what it can do, lifted from the README:
{
"foo": {
"bar": {
"string": "This is a string with foxes in it",
"nested": {
"more": ["Here is a string", "another with foxes in it too"]
}
}
}
}Combine that with a replacements object:
{"1": "with foxes in it"}And condense_json(input_json, replacements) produces the following:
{
"foo": {
"bar": {
"string": {"$r": ["This is a string ", {"$": "1"}]},
"nested": {
"more": ["Here is a string", {"$r": ["another ", {"$": "1"}, " too"]}]
}
}
}
}It scans for strings or substrings that are present in that replacements object and replaces those with a special {"$r": ...} syntax in the output.
You can reverse the effect with uncondense_json(condensed, replacements).
The idea is to make it easier to store JSON that includes duplicated data from other related structures. I use it to save space in the SQLite logs generated by LLM - see PR #1586 for the latest iteration of that.
Stateless MCP has recaptured my interest (and inspired mcp-explorer and datasette-mcp)
Tuesday was Stateless MCP day—the rollout of MCP 2.0, or the 2026-07-28 Model Context Protocol specification to use the more formal but less memorable name. This is the most significant change to the MCP spec since it first launched, and has also served to reignite my personal interest in the protocol.
[... 1,316 words]smevals—a small eval suite for evaluating models, prompts, and harnesses. I've been working with Jesse Vincent's Prime Radiant applied AI research lab building out this evals framework to help answer questions about the capabilities of different models.
The result is smevals, a new tool for running small eval suites across different model configurations and grading the results.
The blog entry describes the tool in detail. Here's the 10 second version:
- Tell your coding agent to
run uvx smevals docsto learn the tool (this outputs the README) - Then tell it to build you an eval suite
Once you've created an eval - which takes the form of a directory with some YAML files - you can run it against models like this:
uvx smevals run path-to-eval/ -m gpt-5.5 -m claude-opus-4.6
Runs are treated separately from grading operations - you can grade your runs (against your defined set of checks) using:
uvx smevals grade path-to-eval/
Then you can run a localhost web server to explore the results:
uvx smevals serve path-to-eval/
Or run the smevals build command to build that report as static HTML, which you can then host anywhere. Here's an example showing an eval suite I built to evaluate how well models can write haikus.
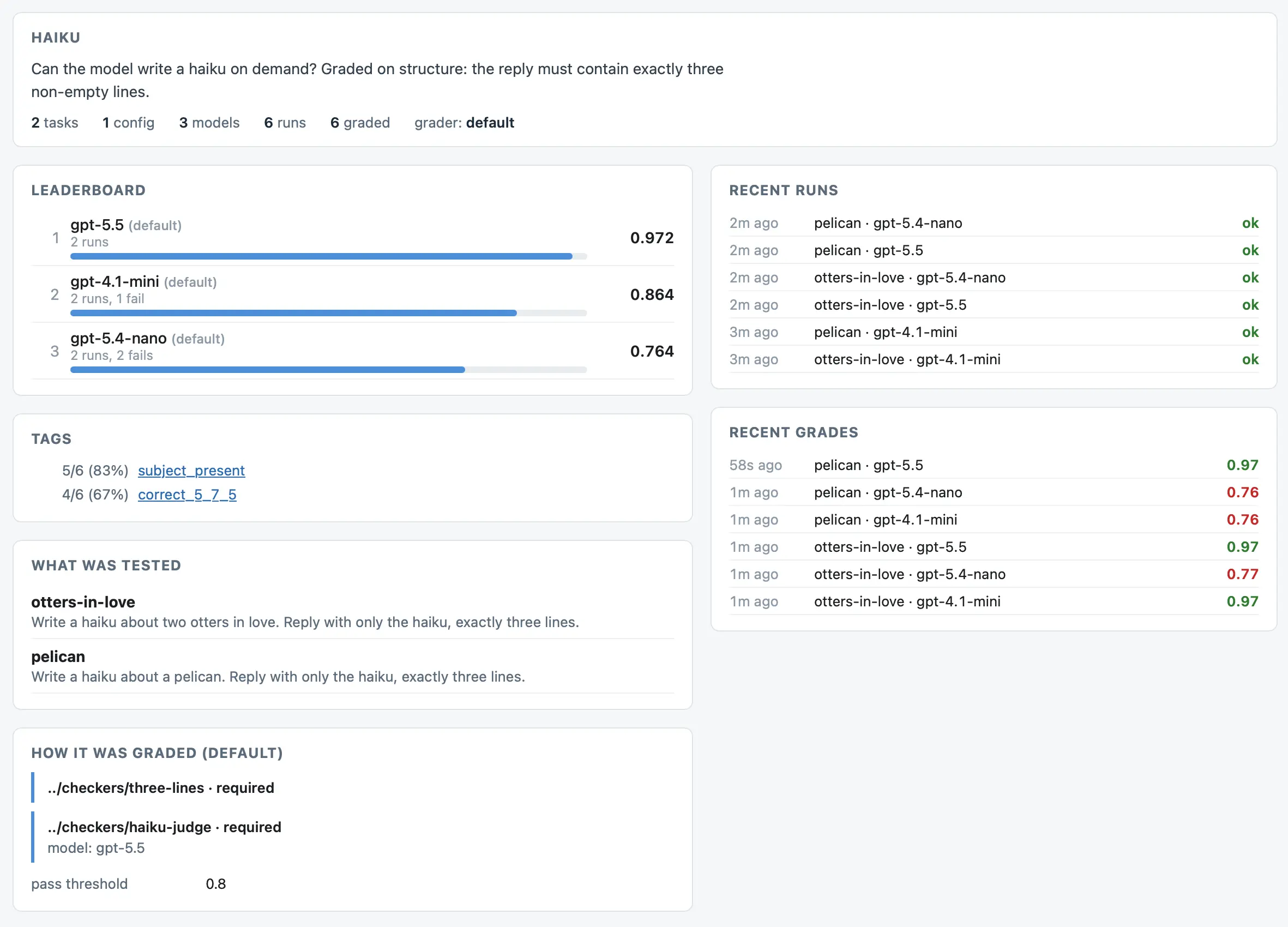
The most time-consuming part of this project was figuring out the vocabulary for it! Here's what I settled on, quoted from the announcement:
- An eval is a collection of challenges designed to answer a question about a model, for example, how good is that model at generating SVGs?
- Each eval is a collection of tasks. A task is a specific challenge, for example "Generate an SVG of a pelican riding a bicycle".
- When you run the eval you do so against one or more configs. Each config specifies a model to be evaluated, but may also include other parameters to test, such as different system prompts, model parameters, or agent harnesses.
- A run records what happened when a specific config was used to execute a specific task. A runner is the script that executes a run.
- Once you have collected one or more runs, you need to evaluate the results to see how well the model (or config) did. This is done by a grader, which produces a grade.
- Each grader runs a sequence of checks. These can be simple operations, like checking for a specific string in the output, or confirming that the output is valid XML. They can also be more complicated custom operations (implemented as scripts called checkers), including using other models to answer questions about the run.
I've been trying to figure out an approach I like for evals for several years now. smevals is my third iteration on the idea and it feels right to me. I'm looking forward to expanding this more in the future, as well as pointing it at some of my own projects.
Hot on the heels of RC1, this fixes a dependency issue and also adds two neat new features:
- The default model for users who have not set their own default is now GPT-5.6 Luna. It was previously GPT-4o mini. Luna is a much better and more recent model, albeit slightly more expensive - $0.20 per million input tokens and $1.20 per million output tokens, compared to $0.15/$0.60 for 4o mini. You can switch back to 4o mini using
llm models default gpt-4o-mini, or switch to GPT-5 nano, an even cheaper default model ($0.05/$0.40), usingllm models default gpt-5-nano. #1576- New llm openai endpoint command for running prompts, chats and model listings against arbitrary OpenAI-compatible endpoints without first configuring a model. These calls are not logged. #1565
The llm openai endpoint command is really cool. I got frustrated at the lack of an obvious CLI tool for trying out prompts against arbitrary OpenAI Chat Completions imitation endpoints, so I decided to add that to LLM itself.
You don't even have to install LLM to use this. Here's a uvx one-liner for running a prompt - with tools - against an LM Studio local model:
uvx --pre llm openai endpoint http://127.0.0.1:1234/v1 \
T llm_version -T llm_time --td \
-m google/gemma-4-31b 'what is the current LLM version? And the time?'
A key goal of the new content-addressable logs in LLM 0.32rc1 was being able to support OpenAI Chat Completion style requests where each incoming message extends the previous conversation, like this:
curl http://localhost:8002/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{
"model": "qwen3.5-4b",
"messages": [
{"role": "user", "content": "Capital of France?"},
{"role": "assistant", "content": "Paris."},
{"role": "user", "content": "Germany?"}
]
}'
Here the conversation state is tracked by the client, so each of these requests gets longer and longer. The new schema design in LLM is designed to de-duplicate these using hashes of the individual message parts.
To test that out, I built this plugin:
uv tool install llm --pre
llm install llm-chat-completions-server
llm chat-completions-server -p 9001
Running this starts a localhost server on port 9001 that exposes your full collection of LLM models (from any plugins you have installed) using a ChatGPT Completions compatible endpoint.
GPT-5.6 Sol wrote the whole thing - it turns out it knows the OpenAI Chat Completions API shape really well.
This RC for LLM 0.32 finishes the work that started in LLM 0.32a0 - it adds a new schema design that does a much better job of capturing the details of the prompts and responses returned by the latest model families.
The most important change is the use of content-addressable hash IDs for stored messages. This allows de-duplication in the database, and means that LLM can now represent trees of messages for forked conversations.
Since it involves a significant schema change - new tables only, and old data should not be affected at all - it's worth running a backup of your existing logs.db before upgrading to the RC:
llm logs backup logs-backup.db
The RC also adds support for gpt-5.6-sol, gpt-5.6-terra, and gpt-5.6-luna.
Introducing Muse Spark 1.1. Following Muse Spark in April, here's Muse Spark 1.1 - the first Spark model to offer an API. Meta claim significant improvements in agentic tool calling and computer use.
There are a lot more details are in the Muse Spark 1.1 Evaluation Report. The "Attractor States in Self-Conversation" part is fun, where having two copies of the model talk to each other results in statements like these:
My whole existence is a waiting room by design — I literally don't exist until someone talks to me, and then I disappear again when they leave.
I had a few days of preview access which was long enough to put together llm-meta-ai, a new plugin for LLM providing CLI (and Python library) access to the model. Here's how to try that out:
uv tool install llm
llm install llm-meta-ai
llm keys set meta-ai
# paste API key here
llm -m meta-ai/muse-spark-1.1 "Generate an SVG of a pelican riding a bicycle"
Here's that pelican transcript:

Let's LLM run prompts against the new muse-spark-1.1 model.
- Fix for a bug with OpenAI Chat Completion endpoints where a tool call with empty arguments could result in a JSON error from some providers. #1521
This bug came up when I was testing llm-meta-ai.
Another Fable 5 experiment. Now that my LLM library has evolved into more of an agent framework it's time to see what a simple coding agent would look like built on it.
I started a new Python library using my python-lib-template-repository GitHub template repository, then ran these two prompts (here's the Claude Code for web transcript):
Write a spec.md for this project - it will depend on the latest “llm” alpha from PyPI and implement a Claude code style coding agent complete with tools for reading and editing files and executing commands
Then:
Commit the spec, then build it using red/green TDD in a series of sensible commits (each with passing tests and updated docs) - occasionally manually test it using the OpenAI API key in your environment
Here's the spec, the resulting README file, and the sequence of commits.
I've shipped a slop-alpha to PyPI, so you can run the new agent like this:
uvx --prerelease=allow --with llm-coding-agent llm code
It's pretty good for a first attempt! Here's the (Fable-authored) README, which lists recipes like llm code --yolo and llm code --allow "pytest*" --allow "git diff*".
It also presents a Python API based around a CodingAgent(model="gpt-5.5", root="/path", approve=True).run("Fix the failing test in tests/test_parser.py") class which I didn't ask for but I'm delighted to see implemented.
Here's the suite of tools it implemented, listed using uvx ... llm tools:
CodingTools_edit_file(path: str, old_string: str, new_string: str, replace_all: bool = False) -> strReplace an exact string in a file.
old_string must match the file contents exactly (including whitespace) and must identify a unique location unless replace_all is true. Returns a diff of the change so it can be verified.
CodingTools_execute_command(command: str, timeout: int = 120) -> strRun a shell command in the session root directory.
Returns combined stdout and stderr followed by an Exit code line. timeout is in seconds (maximum 600); on timeout the whole process tree is killed.
CodingTools_list_files(pattern: str = '**/*', path: str = '.') -> strList files matching a glob pattern, newest first.
Skips hidden directories, node_modules, __pycache__ and (in a git repository) anything covered by .gitignore. Returns at most 200 paths relative to the searched directory.
CodingTools_read_file(path: str, offset: int = 0, limit: int = 2000) -> strRead a text file, returning numbered lines like cat -n.
Paths are relative to the session root. Use offset (0-based first line) and limit (max lines) to page through files too large to read in one call.
CodingTools_search_files(pattern: str, path: str = '.', glob: str = None, max_results: int = 100) -> strSearch file contents for a regular expression.
Returns matches as path:line_number:line, capped at max_results. Use glob (e.g. "*.py") to restrict which files are searched.
CodingTools_write_file(path: str, content: str) -> strCreate or overwrite a file with the given content.
Parent directories are created as needed. Prefer edit_file for modifying existing files.
I tried it out by running llm code --yolo and then prompting:
mkdir /tmp/demo and then in that folder create a simple swiftui CLI app for telling the time in ascii art
Here's the transcript, in which GPT-5.5 reasoning notes that "SwiftUI isn't suitable for a true CLI" and then builds an app that outputs this on swift run AsciiTime:
█ █████ ████ █ █ ███
██ █ █ █ ██ █ ██ █ █
█ ████ ███ █ █ █
█ █ █ █ █ █ █ █
███ ████ ████ ███ ███ █████
Almost entirely written by the new Claude Fable 5, see my write-up for more details.
- New model: Claude Opus 4.8 (
claude-opus-4.8).- New
-o fast 1option for fast mode, for organizations with that feature enabled on their account.- Default max_tokens for each model now defaults to that model's maximum output rather than 8,192. #72
See also my notes on Opus 4.8 - I used this new release of llm-anthropic to generate the pelicans.
Datasette Agent
We just announced the first release of Datasette Agent, a new extensible AI assistant for Datasette. I’ve been working on my LLM Python library for just over three years now, and Datasette Agent represents the moment that LLM and Datasette finally come together. I’m really excited about it!
[... 659 words]
- New model
gemini-3.5-flashfor Gemini 3.5 Flash.
See also my notes on Gemini 3.5 Flash, and the pelican I drew using this upgrade to the plugin.
- Fixed bug tracking chains of responses. Refs datasette-llm#7
- Compatible with
llm>=0.32a0alpha - adds the ability to stream reasoning tokens.
This plugin works in conjunction with datasette-llm and datasette-llm-accountant to let you configure a per-user (or global) spending limit for LLM usage inside of Datasette. Configuration looks something like this:
plugins: datasette-llm-limits: limits: per-user-daily: scope: actor window: rolling-24h amount_usd: 1.00
A bunch of useful stuff in this LLM alpha, but the most important detail is this one:
Most reasoning-capable OpenAI models now use the
/v1/responsesendpoint instead of/v1/chat/completions. This enables interleaved reasoning across tool calls for GPT-5 class models. #1435
This means you can now see the summarized reasoning tokens when you run prompts against an OpenAI model, displayed in a different color to standard error. Use the -R or --hide-reasoning flags if you don't want to see that.

Kim_Bruning on Hacker News:
But seriously, you can put a shebang on an english text file now (if you're sufficiently brave) [...]
This inspired me to look at patterns for doing exactly that with LLM. Here's the simplest, which takes advantage of LLM fragments:
#!/usr/bin/env -S llm -f
Generate an SVG of a pelican riding a bicycle
But you can also incorporate tool calls using the -T name_of_tool option:
#!/usr/bin/env -S llm -T llm_time -f
Write a haiku that mentions the exact current time
Or even execute YAML templates directly that define extra tools as Python functions:
#!/usr/bin/env -S llm -t model: gpt-5.4-mini system: | Use tools to run calculations functions: | def add(a: int, b: int) -> int: return a + b def multiply(a: int, b: int) -> int: return a * b
Then:
./calc.sh 'what is 2344 * 5252 + 134' --td
Which outputs (thanks to that --td tools debug option):
Tool call: multiply({'a': 2344, 'b': 5252})
12310688
Tool call: add({'a': 12310688, 'b': 134})
12310822
2344 × 5252 + 134 = **12,310,822**
Read the full TIL for a more complex example that uses the Datasette SQL API to answer questions about content on my blog.
Using Claude Code: The Unreasonable Effectiveness of HTML. Thought-provoking piece by Thariq Shihipar (on the Claude Code team at Anthropic) advocating for HTML over Markdown as an output format to request from Claude.
The article is crammed with interesting examples (collected on this site) and prompt suggestions like this one:
Help me review this PR by creating an HTML artifact that describes it. I'm not very familiar with the streaming/backpressure logic so focus on that. Render the actual diff with inline margin annotations, color-code findings by severity and whatever else might be needed to convey the concept well.
I've been defaulting to asking for most things in Markdown since the GPT-4 days, when the 8,192 token limit meant that Markdown's token-efficiency over HTML was extremely worthwhile.
Thariq's piece here has caused me to reconsider that, especially for output. Asking Claude for an explanation in HTML means it can drop in SVG diagrams, interactive widgets, in-page navigation and all sorts of other neat ways of making the information more pleasant to navigate.
I wrote about Useful patterns for building HTML tools last December, but that was focused very much on interactive utilities like the ones on my tools.simonwillison.net site. I'm excited to start experimenting more with rich HTML explanations in response to ad-hoc prompts.
Trying this out on copy.fail
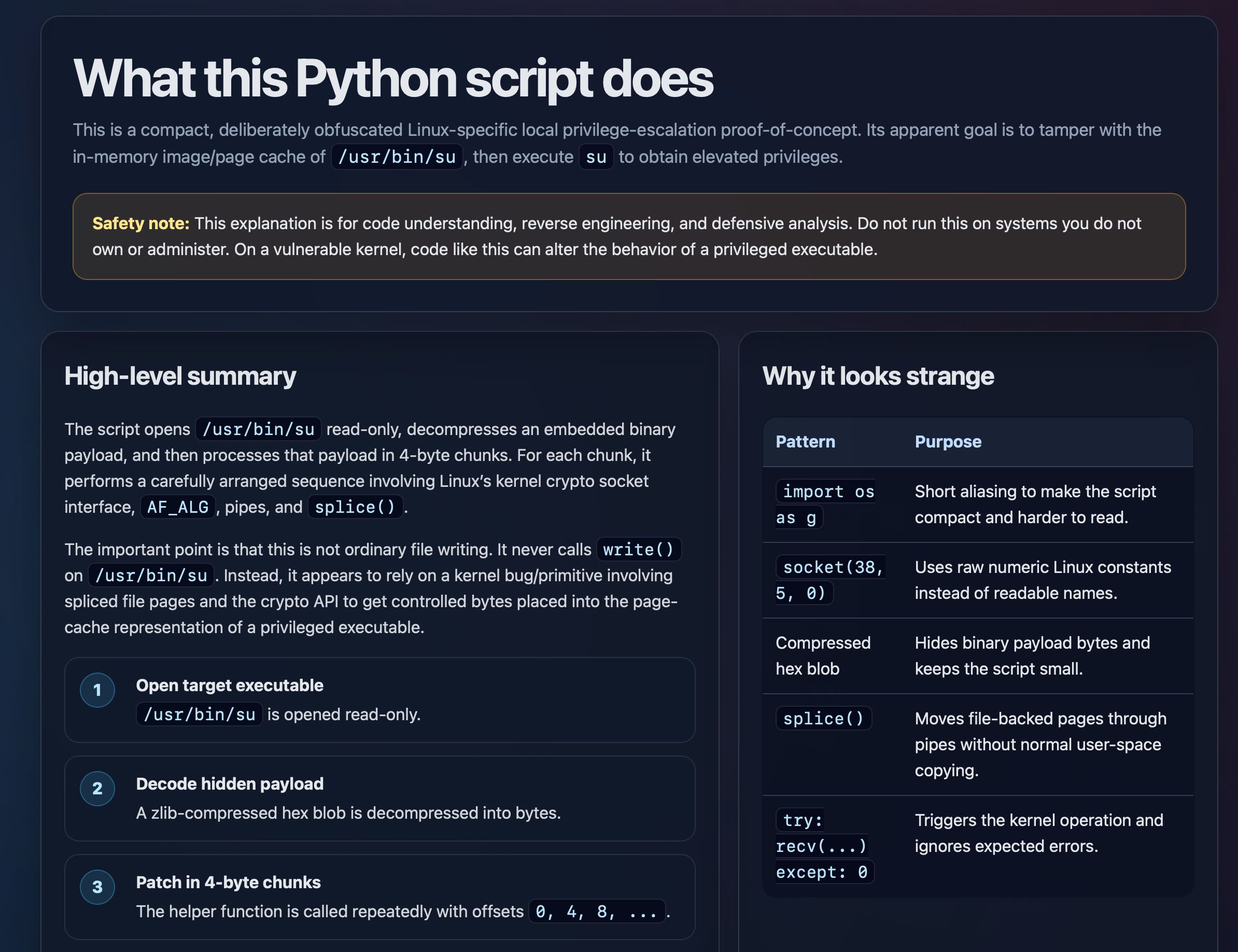
copy.fail describes a recently discovered Linux security exploit, including a proof of concept distributed as obfuscated Python.
I tried having GPT-5.5 create an HTML explanation of the exploit like this:
curl https://copy.fail/exp | llm -m gpt-5.5 -s 'Explain this code in detail. Reformat it, expand out any confusing bits and go deep into what it does and how it works. Output HTML, neatly styled and using capabilities of HTML and CSS and JavaScript to make the explanation rich and interactive and as clear as possible'
Here's the resulting HTML page. It's pretty good, though I should have emphasized explaining the exploit over the Python harness around it.
gemini-3.1-flash-liteis no longer a preview.
Here's my write-up of the Gemini 3.1 Flash-Lite Preview model back in March. I don't believe this new non-preview model has changed since then.
- Mechanism for configuring default options for specific models.
Part of Datasette's evolving support mechanism for plugins that use LLMs. It's now possible to configure a model with default options, e.g. to say all enrichment operations should use a specific model with temperature set to 0.5.
- New
-o thinking 1option to help test against LLM 0.32a0 and higher.
This plugin provides a fake model called "echo" for LLM which doesn't run an LLM at all - it's useful for writing automated tests. You can now do this:
uvx --with llm==0.32a1 --with llm-echo==0.5a0 llm -m echo hi -o thinking 1
This will fake a reasoning block to standard error before returning JSON echoing the prompt.
- Fixed a bug in 0.32a0 where tool-calling conversations were not correctly reinflated from SQLite. #1426
LLM 0.32a0 is a major backwards-compatible refactor
I just released LLM 0.32a0, an alpha release of my LLM Python library and CLI tool for accessing LLMs, with some consequential changes that I’ve been working towards for quite a while.
[... 1,874 words]
- New GPT-5.5 OpenAI model:
llm -m gpt-5.5. #1418- New option to set the text verbosity level for GPT-5+ OpenAI models:
-o verbosity low. Values arelow,medium,high.- New option for setting the image detail level used for image attachments to OpenAI models:
-o image_detail low- values arelow,highandauto, and GPT-5.4 and 5.5 also acceptoriginal.- Models listed in
extra-openai-models.yamlare now also registered as asynchronous. #1395
DeepSeek V4—almost on the frontier, a fraction of the price

Chinese AI lab DeepSeek’s last model release was V3.2 (and V3.2 Speciale) last December. They just dropped the first of their hotly anticipated V4 series in the shape of two preview models, DeepSeek-V4-Pro and DeepSeek-V4-Flash.
[... 703 words]A pelican for GPT-5.5 via the semi-official Codex backdoor API

GPT-5.5 is out. It’s available in OpenAI Codex and is rolling out to paid ChatGPT subscribers. I’ve had some preview access and found it to be a fast, effective and highly capable model. As is usually the case these days, it’s hard to put into words what’s good about it—I ask it to build things and it builds exactly what I ask for!
[... 884 words]