73 posts tagged “llm-tool-use”
Tool use is when an LLM is instructed to occasionally request that an external tool be run on its behalf, with the result passed back to the model for further processing. Sometimes also known as function calling, and one of several ideas that might be referred to as "agents".
2024
Building effective agents (via) My principal complaint about the term "agents" is that while it has many different potential definitions most of the people who use it seem to assume that everyone else shares and understands the definition that they have chosen to use.
This outstanding piece by Erik Schluntz and Barry Zhang at Anthropic bucks that trend from the start, providing a clear definition that they then use throughout.
They discuss "agentic systems" as a parent term, then define a distinction between "workflows" - systems where multiple LLMs are orchestrated together using pre-defined patterns - and "agents", where the LLMs "dynamically direct their own processes and tool usage". This second definition is later expanded with this delightfully clear description:
Agents begin their work with either a command from, or interactive discussion with, the human user. Once the task is clear, agents plan and operate independently, potentially returning to the human for further information or judgement. During execution, it's crucial for the agents to gain “ground truth” from the environment at each step (such as tool call results or code execution) to assess its progress. Agents can then pause for human feedback at checkpoints or when encountering blockers. The task often terminates upon completion, but it’s also common to include stopping conditions (such as a maximum number of iterations) to maintain control.
That's a definition I can live with!
They also introduce a term that I really like: the augmented LLM. This is an LLM with augmentations such as tools - I've seen people use the term "agents" just for this, which never felt right to me.
The rest of the article is the clearest practical guide to building systems that combine multiple LLM calls that I've seen anywhere.
Most of the focus is actually on workflows. They describe five different patterns for workflows in detail:
- Prompt chaining, e.g. generating a document and then translating it to a separate language as a second LLM call
- Routing, where an initial LLM call decides which model or call should be used next (sending easy tasks to Haiku and harder tasks to Sonnet, for example)
- Parallelization, where a task is broken up and run in parallel (e.g. image-to-text on multiple document pages at once) or processed by some kind of voting mechanism
- Orchestrator-workers, where a orchestrator triggers multiple LLM calls that are then synthesized together, for example running searches against multiple sources and combining the results
- Evaluator-optimizer, where one model checks the work of another in a loop
These patterns all make sense to me, and giving them clear names makes them easier to reason about.
When should you upgrade from basic prompting to workflows and then to full agents? The authors provide this sensible warning:
When building applications with LLMs, we recommend finding the simplest solution possible, and only increasing complexity when needed. This might mean not building agentic systems at all.
But assuming you do need to go beyond what can be achieved even with the aforementioned workflow patterns, their model for agents may be a useful fit:
Agents can be used for open-ended problems where it’s difficult or impossible to predict the required number of steps, and where you can’t hardcode a fixed path. The LLM will potentially operate for many turns, and you must have some level of trust in its decision-making. Agents' autonomy makes them ideal for scaling tasks in trusted environments.
The autonomous nature of agents means higher costs, and the potential for compounding errors. We recommend extensive testing in sandboxed environments, along with the appropriate guardrails
They also warn against investing in complex agent frameworks before you've exhausted your options using direct API access and simple code.
The article is accompanied by a brand new set of cookbook recipes illustrating all five of the workflow patterns. The Evaluator-Optimizer Workflow example is particularly fun, setting up a code generating prompt and an code reviewing evaluator prompt and having them loop until the evaluator is happy with the result.
googleapis/python-genai. Google released this brand new Python library for accessing their generative AI models yesterday, offering an alternative to their existing generative-ai-python library.
The API design looks very solid to me, and it includes both sync and async implementations. Here's an async streaming response:
async for response in client.aio.models.generate_content_stream(
model='gemini-2.0-flash-exp',
contents='Tell me a story in 300 words.'
):
print(response.text)
It also includes Pydantic-based output schema support and some nice syntactic sugar for defining tools using Python functions.
PydanticAI (via) New project from Pydantic, which they describe as an "Agent Framework / shim to use Pydantic with LLMs".
I asked which agent definition they are using and it's the "system prompt with bundled tools" one. To their credit, they explain that in their documentation:
The Agent has full API documentation, but conceptually you can think of an agent as a container for:
- A system prompt — a set of instructions for the LLM written by the developer
- One or more retrieval tool — functions that the LLM may call to get information while generating a response
- An optional structured result type — the structured datatype the LLM must return at the end of a run
Given how many other existing tools already lean on Pydantic to help define JSON schemas for talking to LLMs this is an interesting complementary direction for Pydantic to take.
There's some overlap here with my own LLM project, which I still hope to add a function calling / tools abstraction to in the future.
Notes on the new Claude analysis JavaScript code execution tool
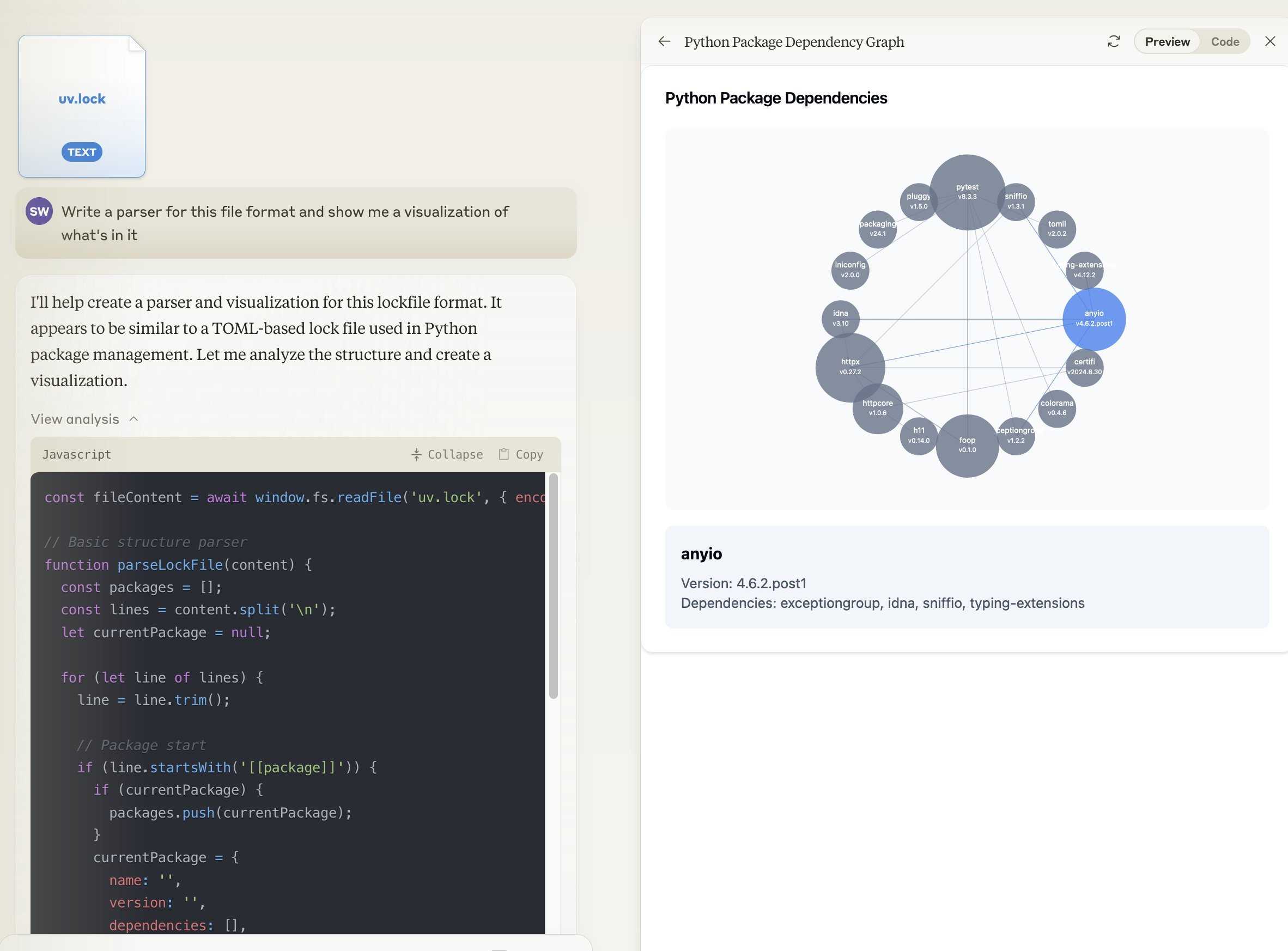
Anthropic released a new feature for their Claude.ai consumer-facing chat bot interface today which they’re calling “the analysis tool”.
[... 918 words]Initial explorations of Anthropic’s new Computer Use capability
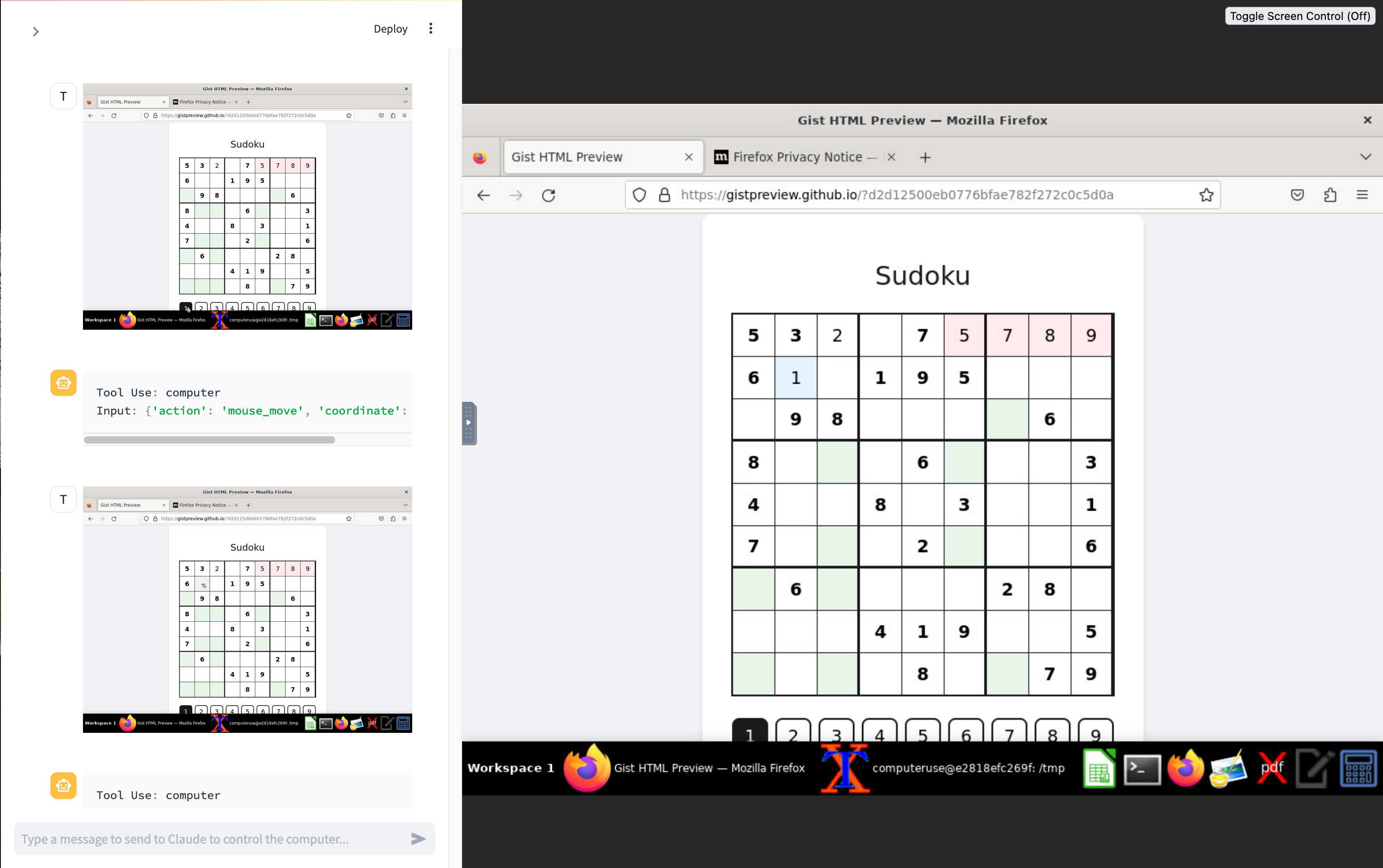
Two big announcements from Anthropic today: a new Claude 3.5 Sonnet model and a new API mode that they are calling computer use.
[... 1,569 words]Mistral NeMo. Released by Mistral today: "Our new best small model. A state-of-the-art 12B model with 128k context length, built in collaboration with NVIDIA, and released under the Apache 2.0 license."
Nice to see Mistral use Apache 2.0 for this, unlike their Codestral 22B release - though Codestral Mamba was Apache 2.0 as well.
Mistral's own benchmarks put NeMo slightly ahead of the smaller (but same general weight class) Gemma 2 9B and Llama 3 8B models.
It's both multi-lingual and trained for tool usage:
The model is designed for global, multilingual applications. It is trained on function calling, has a large context window, and is particularly strong in English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic, and Hindi.
Part of this is down to the new Tekken tokenizer, which is 30% more efficient at representing both source code and most of the above listed languages.
You can try it out via Mistral's API using llm-mistral like this:
pipx install llm
llm install llm-mistral
llm keys set mistral
# paste La Plateforme API key here
llm mistral refresh # if you installed the plugin before
llm -m mistral/open-mistral-nemo 'Rave about pelicans in French'
Introducing Llama-3-Groq-Tool-Use Models (via) New from Groq: two custom fine-tuned Llama 3 models specifically designed for tool use. Hugging Face model links:
Groq's own internal benchmarks put their 70B model at the top of the Berkeley Function-Calling Leaderboard with a score of 90.76 (and 89.06 for their 8B model, which would put it at #3). For comparison, Claude 3.5 Sonnet scores 90.18 and GPT-4-0124 scores 88.29.
The two new Groq models are also available through their screamingly-fast (fastest in the business?) API, running at 330 tokens/s and 1050 tokens/s respectively.
Here's the documentation on how to use tools through their API.
llm-command-r. Cohere released Command R Plus today—an open weights (non commercial/research only) 104 billion parameter LLM, a big step up from their previous 35 billion Command R model.
Both models are fine-tuned for both tool use and RAG. The commercial API has features to expose this functionality, including a web-search connector which lets the model run web searches as part of answering the prompt and return documents and citations as part of the JSON response.
I released a new plugin for my LLM command line tool this morning adding support for the Command R models.
In addition to the two models it also adds a custom command for running prompts with web search enabled and listing the referenced documents.
Mistral Large. Mistral Medium only came out two months ago, and now it's followed by Mistral Large. Like Medium, this new model is currently only available via their API. It scores well on benchmarks (though not quite as well as GPT-4) but the really exciting feature is function support, clearly based on OpenAI's own function design.
Functions are now supported via the Mistral API for both Mistral Large and the new Mistral Small, described as follows:
Mistral Small, optimised for latency and cost. Mistral Small outperforms Mixtral 8x7B and has lower latency, which makes it a refined intermediary solution between our open-weight offering and our flagship model.
2023
Introducing Claude 2.1. Anthropic’s Claude used to have the longest token context of any of the major models: 100,000 tokens, which is about 300 pages. Then GPT-4 Turbo came out with 128,000 tokens and Claude lost one of its key differentiators.
Claude is back! Version 2.1, announced today, bumps the token limit up to 200,000—and also adds support for OpenAI-style system prompts, a feature I’ve been really missing.
They also announced tool use, but that’s only available for a very limited set of partners to preview at the moment.
Could you train a ChatGPT-beating model for $85,000 and run it in a browser?
I think it’s now possible to train a large language model with similar functionality to GPT-3 for $85,000. And I think we might soon be able to run the resulting model entirely in the browser, and give it capabilities that leapfrog it ahead of ChatGPT.
[... 1,751 words]A simple Python implementation of the ReAct pattern for LLMs. I implemented the ReAct pattern (for Reason+Act) described in this paper. It's a pattern where you implement additional actions that an LLM can take - searching Wikipedia or running calculations for example - and then teach it how to request that those actions are run, then feed their results back into the LLM.
The surprising ease and effectiveness of AI in a loop (via) Matt Webb on the langchain Python library and the ReAct design pattern, where you plug additional tools into a language model by teaching it to work in a “Thought... Act... Observation” loop where the Act specifies an action it wishes to take (like searching Wikipedia) and an extra layer of software than carries out that action and feeds back the result as the Observation. Matt points out that the ChatGPT 1/10th price drop makes this kind of model usage enormously more cost effective than it was before.