41 posts tagged “mlx”
The MLX framework for running machine learning models on Apple Silicon.
2026
Autoresearching Apple’s “LLM in a Flash” to run Qwen 397B locally. Here's a fascinating piece of research by Dan Woods, who managed to get a custom version of Qwen3.5-397B-A17B running at 5.5+ tokens/second on a 48GB MacBook Pro M3 Max despite that model taking up 209GB (120GB quantized) on disk.
Qwen3.5-397B-A17B is a Mixture-of-Experts (MoE) model, which means that each token only needs to run against a subset of the overall model weights. These expert weights can be streamed into memory from SSD, saving them from all needing to be held in RAM at the same time.
Dan used techniques described in Apple's 2023 paper LLM in a flash: Efficient Large Language Model Inference with Limited Memory:
This paper tackles the challenge of efficiently running LLMs that exceed the available DRAM capacity by storing the model parameters in flash memory, but bringing them on demand to DRAM. Our method involves constructing an inference cost model that takes into account the characteristics of flash memory, guiding us to optimize in two critical areas: reducing the volume of data transferred from flash and reading data in larger, more contiguous chunks.
He fed the paper to Claude Code and used a variant of Andrej Karpathy's autoresearch pattern to have Claude run 90 experiments and produce MLX Objective-C and Metal code that ran the model as efficiently as possible.
danveloper/flash-moe has the resulting code plus a PDF paper mostly written by Claude Opus 4.6 describing the experiment in full.
The final model has the experts quantized to 2-bit, but the non-expert parts of the model such as the embedding table and routing matrices are kept at their original precision, adding up to 5.5GB which stays resident in memory while the model is running.
Qwen 3.5 usually runs 10 experts per token, but this setup dropped that to 4 while claiming that the biggest quality drop-off occurred at 3.
It's not clear to me how much the quality of the model results are affected. Claude claimed that "Output quality at 2-bit is indistinguishable from 4-bit for these evaluations", but the description of the evaluations it ran is quite thin.
Update: Dan's latest version upgrades to 4-bit quantization of the experts (209GB on disk, 4.36 tokens/second) after finding that the 2-bit version broke tool calling while 4-bit handles that well.
Qwen3-TTS Family is Now Open Sourced: Voice Design, Clone, and Generation (via) I haven't been paying much attention to the state-of-the-art in speech generation models other than noting that they've got really good, so I can't speak for how notable this new release from Qwen is.
From the accompanying paper:
In this report, we present the Qwen3-TTS series, a family of advanced multilingual, controllable, robust, and streaming text-to-speech models. Qwen3-TTS supports state-of- the-art 3-second voice cloning and description-based control, allowing both the creation of entirely novel voices and fine-grained manipulation over the output speech. Trained on over 5 million hours of speech data spanning 10 languages, Qwen3-TTS adopts a dual-track LM architecture for real-time synthesis [...]. Extensive experiments indicate state-of-the-art performance across diverse objective and subjective benchmark (e.g., TTS multilingual test set, InstructTTSEval, and our long speech test set). To facilitate community research and development, we release both tokenizers and models under the Apache 2.0 license.
To give an idea of size, Qwen/Qwen3-TTS-12Hz-1.7B-Base is 4.54GB on Hugging Face and Qwen/Qwen3-TTS-12Hz-0.6B-Base is 2.52GB.
The Hugging Face demo lets you try out the 0.6B and 1.7B models for free in your browser, including voice cloning:
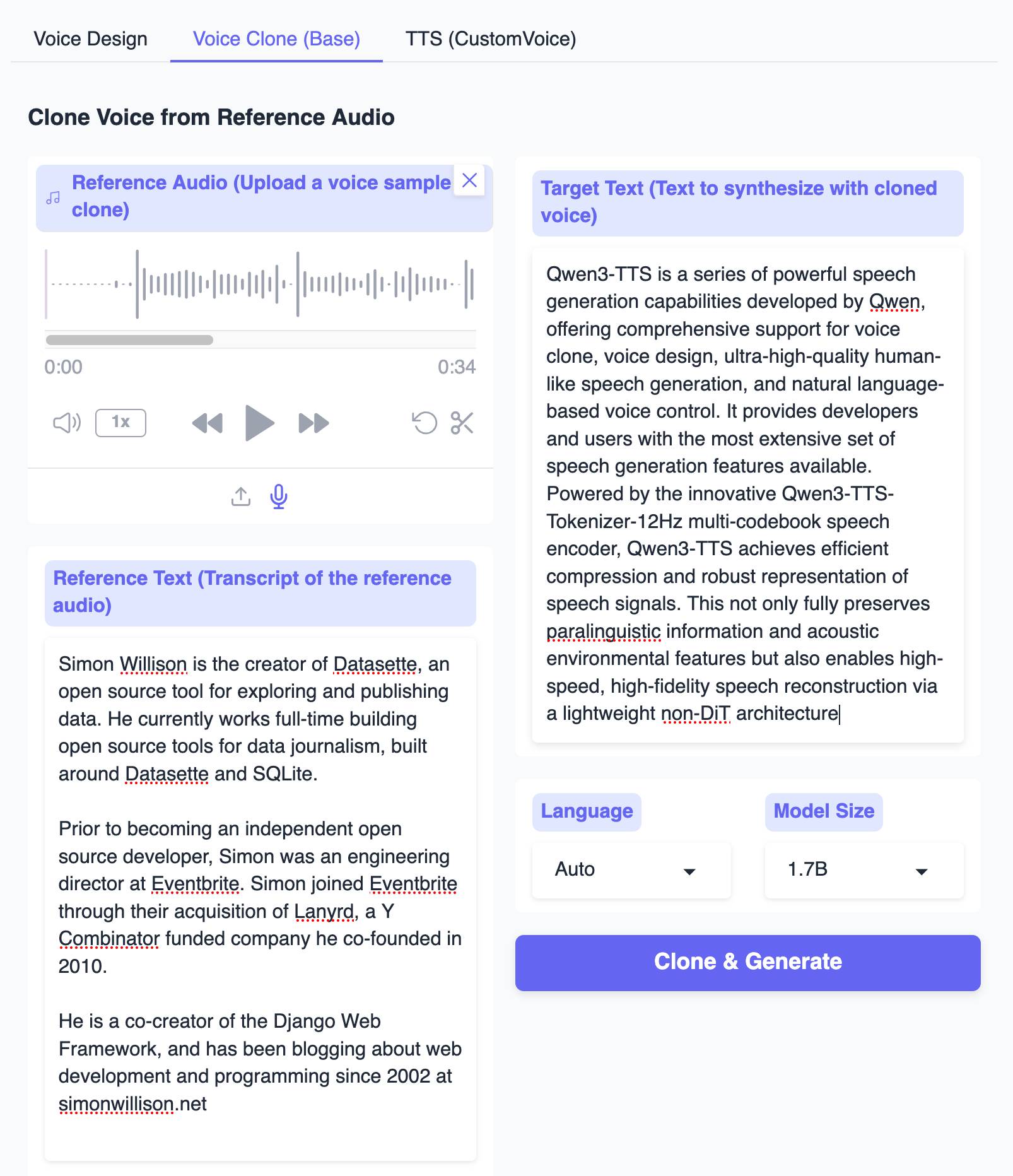
I tried this out by recording myself reading my about page and then having Qwen3-TTS generate audio of me reading the Qwen3-TTS announcement post. Here's the result:
It's important that everyone understands that voice cloning is now something that's available to anyone with a GPU and a few GBs of VRAM... or in this case a web browser that can access Hugging Face.
Update: Prince Canuma got this working with his mlx-audio library. I had Claude turn that into a CLI tool which you can run with uv ike this:
uv run https://tools.simonwillison.net/python/q3_tts.py \
'I am a pirate, give me your gold!' \
-i 'gruff voice' -o pirate.wav
The -i option lets you use a prompt to describe the voice it should use. On first run this downloads a 4.5GB model file from Hugging Face.
2025
parakeet-mlx. Neat MLX project by Senstella bringing NVIDIA's Parakeet ASR (Automatic Speech Recognition, like Whisper) model to to Apple's MLX framework.
It's packaged as a Python CLI tool, so you can run it like this:
uvx parakeet-mlx default_tc.mp3
The first time I ran this it downloaded a 2.5GB model file.
Once that was fetched it took 53 seconds to transcribe a 65MB 1hr 1m 28s podcast episode (this one) and produced this default_tc.srt file with a timestamped transcript of the audio I fed into it. The quality appears to be very high.
Kimi K2 Thinking. Chinese AI lab Moonshot's Kimi K2 established itself as one of the largest open weight models - 1 trillion parameters - back in July. They've now released the Thinking version, also a trillion parameters (MoE, 32B active) and also under their custom modified (so not quite open source) MIT license.
Starting with Kimi K2, we built it as a thinking agent that reasons step-by-step while dynamically invoking tools. It sets a new state-of-the-art on Humanity's Last Exam (HLE), BrowseComp, and other benchmarks by dramatically scaling multi-step reasoning depth and maintaining stable tool-use across 200–300 sequential calls. At the same time, K2 Thinking is a native INT4 quantization model with 256k context window, achieving lossless reductions in inference latency and GPU memory usage.
This one is only 594GB on Hugging Face - Kimi K2 was 1.03TB - which I think is due to the new INT4 quantization. This makes the model both cheaper and faster to host.
So far the only people hosting it are Moonshot themselves. I tried it out both via their own API and via the OpenRouter proxy to it, via the llm-moonshot plugin (by NickMystic) and my llm-openrouter plugin respectively.
The buzz around this model so far is very positive. Could this be the first open weight model that's competitive with the latest from OpenAI and Anthropic, especially for long-running agentic tool call sequences?
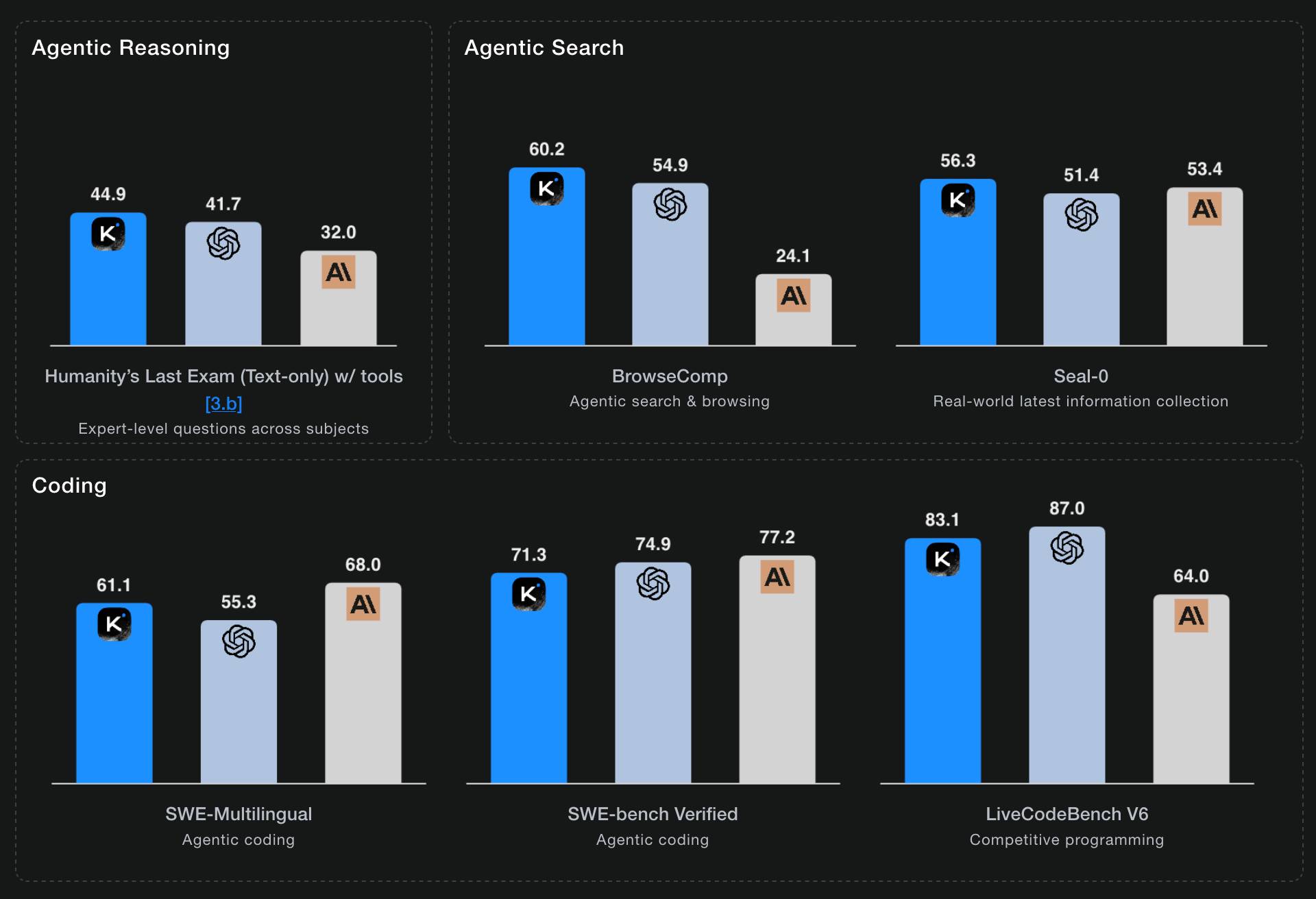
Moonshot AI's self-reported benchmark scores show K2 Thinking beating the top OpenAI and Anthropic models (GPT-5 and Sonnet 4.5 Thinking) at "Agentic Reasoning" and "Agentic Search" but not quite top for "Coding":
I ran a couple of pelican tests:
llm install llm-moonshot
llm keys set moonshot # paste key
llm -m moonshot/kimi-k2-thinking 'Generate an SVG of a pelican riding a bicycle'

llm install llm-openrouter
llm keys set openrouter # paste key
llm -m openrouter/moonshotai/kimi-k2-thinking \
'Generate an SVG of a pelican riding a bicycle'
Artificial Analysis said:
Kimi K2 Thinking achieves 93% in 𝜏²-Bench Telecom, an agentic tool use benchmark where the model acts as a customer service agent. This is the highest score we have independently measured. Tool use in long horizon agentic contexts was a strength of Kimi K2 Instruct and it appears this new Thinking variant makes substantial gains
CNBC quoted a source who provided the training price for the model:
The Kimi K2 Thinking model cost $4.6 million to train, according to a source familiar with the matter. [...] CNBC was unable to independently verify the DeepSeek or Kimi figures.
MLX developer Awni Hannun got it working on two 512GB M3 Ultra Mac Studios:
The new 1 Trillion parameter Kimi K2 Thinking model runs well on 2 M3 Ultras in its native format - no loss in quality!
The model was quantization aware trained (qat) at int4.
Here it generated ~3500 tokens at 15 toks/sec using pipeline-parallelism in mlx-lm
Here's the 658GB mlx-community model.
Locally AI. Handy new iOS app by Adrien Grondin for running local LLMs on your phone. It just added support for the new iOS 26 Apple Foundation model, so you can install this app and instantly start a conversation with that model without any additional download.
The app can also run a variety of other models using MLX, including members of the Gemma, Llama 3.2, and and Qwen families.
XBai o4 (via) Yet another open source (Apache 2.0) LLM from a Chinese AI lab. This model card claims:
XBai o4 excels in complex reasoning capabilities and has now completely surpassed OpenAI-o3-mini in Medium mode.
This a 32.8 billion parameter model released by MetaStone AI, a new-to-me lab who released their first model in March - MetaStone-L1-7B, then followed that with MetaStone-S1 1.5B, 7B and 32B in July and now XBai o4 in August.
The MetaStone-S1 models were accompanied with a paper, Test-Time Scaling with Reflective Generative Model.
There is very little information available on the English-language web about MetaStone AI. Their paper shows a relationship with USTC, University of Science and Technology of China in Hefei. One of their researchers confirmed on Twitter that their CEO is from KWAI which lead me to this Chinese language article from July last year about Li Yan, formerly of KWAI and now the founder of Wen Xiaobai and evidently now the CEO of MetaStone. www.wenxiaobai.com is listed as the "official website" linked to from the XBai-o4 README on GitHub.
Ivan Fioravanti got it working under MLX in 4bit, 5bit, 6bit, 8bit and 4bit-DWQ sizes. I tried his 6bit one (a 24.81GB download) in LM Studio and had it "Generate an SVG of a pelican riding a bicycle". It thought for 39.49 seconds (thinking trace here) and gave me this:

I also had it "Write an HTML and JavaScript page implementing space invaders", which you can try out here. It's not great - the invaders don't fire bullets (it listed that as a "potential improvement") and I don't think it's winnable due to timing issues, but it's an interesting addition to my collection.
LM Studio reported a constant memory usage of 25.54GB and according to Activity Monitor used 87.5% of my GPU and around 39% of a CPU core.
It did a lot of work in the thinking trace - which took 10m35s! - including writing the first draft of much of the code that ended up in the finished result. Here's an extract:
Let me think of variables:
let enemyDirection = 1; // 1 for right, -1 for leftIn the game loop:
enemies.forEach(enemy => {> enemy.x += enemyDirection * enemy.dx;> });Then check if any enemy is out of bounds. If so, reverse direction and move all enemies down.But how to check if any enemy is at the edge?
Maybe find the max x of all enemies and see if it exceeds
canvas.width - enemy.width.Alternatively, track the leftmost and rightmost positions of enemies. Maybe a bit complex.
For simplicity, perhaps check if any enemy's
x + width > canvas.width or x < 0.
Here's the full transcript.
My initial impressions are that I'm not as impressed with this model for running on my own laptop as I was with Qwen3-Coder-30B-A3B-Instruct or GLM-4.5 Air.
But... how extraordinary is it that another Chinese AI lab has been able to produce a competitive model, this time with far less fanfare than we've seen from Qwen and Moonshot AI and Z.ai.
Qwen3-30B-A3B-Instruct-2507. New model update from Qwen, improving on their previous Qwen3-30B-A3B release from late April. In their tweet they said:
Smarter, faster, and local deployment-friendly.
✨ Key Enhancements:
✅ Enhanced reasoning, coding, and math skills
✅ Broader multilingual knowledge
✅ Improved long-context understanding (up to 256K tokens)
✅ Better alignment with user intent and open-ended tasks
✅ No more<think>blocks — now operating exclusively in non-thinking mode🔧 With 3B activated parameters, it's approaching the performance of GPT-4o and Qwen3-235B-A22B Non-Thinking
I tried the chat.qwen.ai hosted model with "Generate an SVG of a pelican riding a bicycle" and got this:

I particularly enjoyed this detail from the SVG source code:
<!-- Bonus: Pelican's smile -->
<path d="M245,145 Q250,150 255,145" fill="none" stroke="#d4a037" stroke-width="2"/>
I went looking for quantized versions that could fit on my Mac and found lmstudio-community/Qwen3-30B-A3B-Instruct-2507-MLX-8bit from LM Studio. Getting that up and running was a 32.46GB download and it appears to use just over 30GB of RAM.
The pelican I got from that one wasn't as good:

I then tried that local model on the "Write an HTML and JavaScript page implementing space invaders" task that I ran against GLM-4.5 Air. The output looked promising, in particular it seemed to be putting more effort into the design of the invaders (GLM-4.5 Air just used rectangles):
// Draw enemy ship ctx.fillStyle = this.color; // Ship body ctx.fillRect(this.x, this.y, this.width, this.height); // Enemy eyes ctx.fillStyle = '#fff'; ctx.fillRect(this.x + 6, this.y + 5, 4, 4); ctx.fillRect(this.x + this.width - 10, this.y + 5, 4, 4); // Enemy antennae ctx.fillStyle = '#f00'; if (this.type === 1) { // Basic enemy ctx.fillRect(this.x + this.width / 2 - 1, this.y - 5, 2, 5); } else if (this.type === 2) { // Fast enemy ctx.fillRect(this.x + this.width / 4 - 1, this.y - 5, 2, 5); ctx.fillRect(this.x + (3 * this.width) / 4 - 1, this.y - 5, 2, 5); } else if (this.type === 3) { // Armored enemy ctx.fillRect(this.x + this.width / 2 - 1, this.y - 8, 2, 8); ctx.fillStyle = '#0f0'; ctx.fillRect(this.x + this.width / 2 - 1, this.y - 6, 2, 3); }
But the resulting code didn't actually work:

That same prompt against the unquantized Qwen-hosted model produced a different result which sadly also resulted in an unplayable game - this time because everything moved too fast.
This new Qwen model is a non-reasoning model, whereas GLM-4.5 and GLM-4.5 Air are both reasoners. It looks like at this scale the "reasoning" may make a material difference in terms of getting code that works out of the box.
My 2.5 year old laptop can write Space Invaders in JavaScript now, using GLM-4.5 Air and MLX
I wrote about the new GLM-4.5 model family yesterday—new open weight (MIT licensed) models from Z.ai in China which their benchmarks claim score highly in coding even against models such as Claude Sonnet 4.
[... 685 words]GLM-4.5: Reasoning, Coding, and Agentic Abililties. Another day, another significant new open weight model release from a Chinese frontier AI lab.
This time it's Z.ai - who rebranded (at least in English) from Zhipu AI a few months ago. They just dropped GLM-4.5-Base, GLM-4.5 and GLM-4.5 Air on Hugging Face, all under an MIT license.
These are MoE hybrid reasoning models with thinking and non-thinking modes, similar to Qwen 3. GLM-4.5 is 355 billion total parameters with 32 billion active, GLM-4.5-Air is 106 billion total parameters and 12 billion active.
They started using MIT a few months ago for their GLM-4-0414 models - their older releases used a janky non-open-source custom license.
Z.ai's own benchmarking (across 12 common benchmarks) ranked their GLM-4.5 3rd behind o3 and Grok-4 and just ahead of Claude Opus 4. They ranked GLM-4.5 Air 6th place just ahead of Claude 4 Sonnet. I haven't seen any independent benchmarks yet.
The other models they included in their own benchmarks were o4-mini (high), Gemini 2.5 Pro, Qwen3-235B-Thinking-2507, DeepSeek-R1-0528, Kimi K2, GPT-4.1, DeepSeek-V3-0324. Notably absent: any of Meta's Llama models, or any of Mistral's. Did they deliberately only compare themselves to open weight models from other Chinese AI labs?
Both models have a 128,000 context length and are trained for tool calling, which honestly feels like table stakes for any model released in 2025 at this point.
It's interesting to see them use Claude Code to run their own coding benchmarks:
To assess GLM-4.5's agentic coding capabilities, we utilized Claude Code to evaluate performance against Claude-4-Sonnet, Kimi K2, and Qwen3-Coder across 52 coding tasks spanning frontend development, tool development, data analysis, testing, and algorithm implementation. [...] The empirical results demonstrate that GLM-4.5 achieves a 53.9% win rate against Kimi K2 and exhibits dominant performance over Qwen3-Coder with an 80.8% success rate. While GLM-4.5 shows competitive performance, further optimization opportunities remain when compared to Claude-4-Sonnet.
They published the dataset for that benchmark as zai-org/CC-Bench-trajectories on Hugging Face. I think they're using the word "trajectory" for what I would call a chat transcript.
Unlike DeepSeek-V3 and Kimi K2, we reduce the width (hidden dimension and number of routed experts) of the model while increasing the height (number of layers), as we found that deeper models exhibit better reasoning capacity.
They pre-trained on 15 trillion tokens, then an additional 7 trillion for code and reasoning:
Our base model undergoes several training stages. During pre-training, the model is first trained on 15T tokens of a general pre-training corpus, followed by 7T tokens of a code & reasoning corpus. After pre-training, we introduce additional stages to further enhance the model's performance on key downstream domains.
They also open sourced their post-training reinforcement learning harness, which they've called slime. That's available at THUDM/slime on GitHub - THUDM is the Knowledge Engineer Group @ Tsinghua University, the University from which Zhipu AI spun out as an independent company.
This time I ran my pelican bechmark using the chat.z.ai chat interface, which offers free access (no account required) to both GLM 4.5 and GLM 4.5 Air. I had reasoning enabled for both.
Here's what I got for "Generate an SVG of a pelican riding a bicycle" on GLM 4.5. I like how the pelican has its wings on the handlebars:

And GLM 4.5 Air:

Ivan Fioravanti shared a video of the mlx-community/GLM-4.5-Air-4bit quantized model running on a M4 Mac with 128GB of RAM, and it looks like a very strong contender for a local model that can write useful code. The cheapest 128GB Mac Studio costs around $3,500 right now, so genuinely great open weight coding models are creeping closer to being affordable on consumer machines.
Update: Ivan released a 3 bit quantized version of GLM-4.5 Air which runs using 48GB of RAM on my laptop. I tried it and was really impressed, see My 2.5 year old laptop can write Space Invaders in JavaScript now.
moonshotai/Kimi-K2-Instruct (via) Colossal new open weights model release today from Moonshot AI, a two year old Chinese AI lab with a name inspired by Pink Floyd’s album The Dark Side of the Moon.
My HuggingFace storage calculator says the repository is 958.52 GB. It's a mixture-of-experts model with "32 billion activated parameters and 1 trillion total parameters", trained using the Muon optimizer as described in Moonshot's joint paper with UCLA Muon is Scalable for LLM Training.
I think this may be the largest ever open weights model? DeepSeek v3 is 671B.
I created an API key for Moonshot, added some dollars and ran a prompt against it using my LLM tool. First I added this to the extra-openai-models.yaml file:
- model_id: kimi-k2
model_name: kimi-k2-0711-preview
api_base: https://api.moonshot.ai/v1
api_key_name: moonshot
Then I set the API key:
llm keys set moonshot
# Paste key here
And ran a prompt:
llm -m kimi-k2 "Generate an SVG of a pelican riding a bicycle" \
-o max_tokens 2000
(The default max tokens setting was too short.)
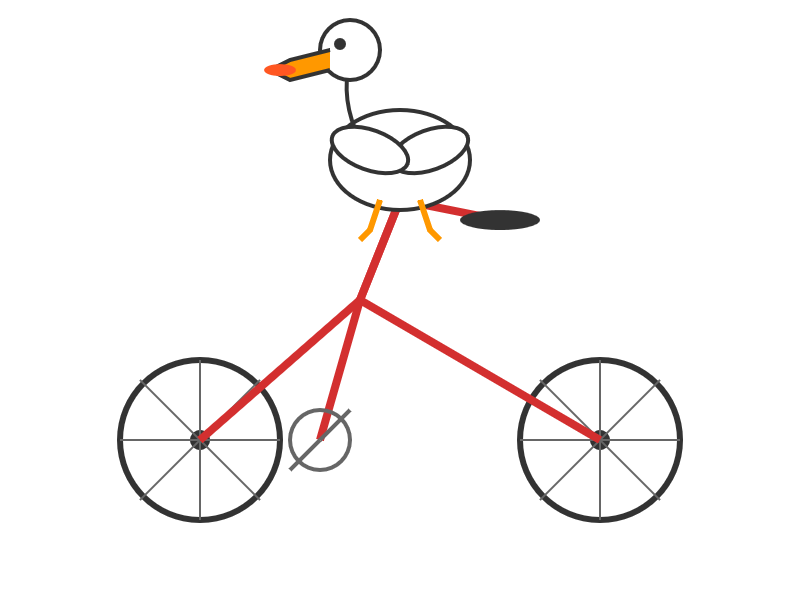
This is pretty good! The spokes are a nice touch. Full transcript here.
This one is open weights but not open source: they're using a modified MIT license with this non-OSI-compliant section tagged on at the end:
Our only modification part is that, if the Software (or any derivative works thereof) is used for any of your commercial products or services that have more than 100 million monthly active users, or more than 20 million US dollars (or equivalent in other currencies) in monthly revenue, you shall prominently display "Kimi K2" on the user interface of such product or service.
Update: MLX developer Awni Hannun reports:
The new Kimi K2 1T model (4-bit quant) runs on 2 512GB M3 Ultras with mlx-lm and mx.distributed.
1 trillion params, at a speed that's actually quite usable
Introducing Gemma 3n: The developer guide. Extremely consequential new open weights model release from Google today:
Multimodal by design: Gemma 3n natively supports image, audio, video, and text inputs and text outputs.
Optimized for on-device: Engineered with a focus on efficiency, Gemma 3n models are available in two sizes based on effective parameters: E2B and E4B. While their raw parameter count is 5B and 8B respectively, architectural innovations allow them to run with a memory footprint comparable to traditional 2B and 4B models, operating with as little as 2GB (E2B) and 3GB (E4B) of memory.
This is very exciting: a 2B and 4B model optimized for end-user devices which accepts text, images and audio as inputs!
Gemma 3n is also the most comprehensive day one launch I've seen for any model: Google partnered with "AMD, Axolotl, Docker, Hugging Face, llama.cpp, LMStudio, MLX, NVIDIA, Ollama, RedHat, SGLang, Unsloth, and vLLM" so there are dozens of ways to try this out right now.
So far I've run two variants on my Mac laptop. Ollama offer a 7.5GB version (full tag gemma3n:e4b-it-q4_K_M0) of the 4B model, which I ran like this:
ollama pull gemma3n
llm install llm-ollama
llm -m gemma3n:latest "Generate an SVG of a pelican riding a bicycle"
It drew me this:

The Ollama version doesn't appear to support image or audio input yet.
... but the mlx-vlm version does!
First I tried that on this WAV file like so (using a recipe adapted from Prince Canuma's video):
uv run --with mlx-vlm mlx_vlm.generate \
--model gg-hf-gm/gemma-3n-E4B-it \
--max-tokens 100 \
--temperature 0.7 \
--prompt "Transcribe the following speech segment in English:" \
--audio pelican-joke-request.wav
That downloaded a 15.74 GB bfloat16 version of the model and output the following correct transcription:
Tell me a joke about a pelican.
Then I had it draw me a pelican for good measure:
uv run --with mlx-vlm mlx_vlm.generate \
--model gg-hf-gm/gemma-3n-E4B-it \
--max-tokens 100 \
--temperature 0.7 \
--prompt "Generate an SVG of a pelican riding a bicycle"
I quite like this one:
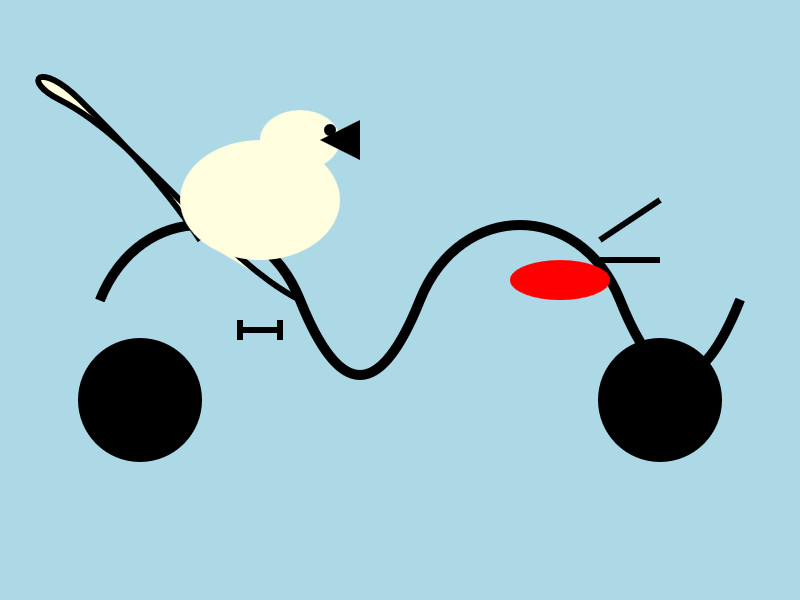
It's interesting to see such a striking visual difference between those 7.5GB and 15GB model quantizations.
Finally, I had it describe the image it had just created:
uv run --with mlx-vlm mlx_vlm.generate \
--model gg-hf-gm/gemma-3n-E4B-it \
--max-tokens 1000 \
--prompt "Describe image" \
--image gemma3n-mlx-vlm.jpg
Here's what I got back - it thought this was a chemical diagram!
The image is a cartoon-style illustration depicting a molecular structure against a light blue background. The structure is composed of several differently colored and shaped elements connected by curved black lines.
Here's a breakdown of the elements:
- Large Black Circles: There are two large, solid black circles, likely representing larger molecules or components.
- Cream-Colored Oval: A prominent cream-colored oval shape is centrally located and connected to other elements. It has a smaller, darker cream-colored sphere attached to its left side.
- Red Oval: A smaller, solid red oval is positioned near one of the black circles and connected to the cream-colored oval.
- Black Lines: These lines act as bonds, connecting the various molecular components. They are curved and dynamic, suggesting movement or interaction.
- Triangular Shape: A small black triangle is attached to the smaller cream-colored sphere.
- Letter "I": The letter "I" appears twice, likely labeling specific parts of the molecule.
The overall impression is of a simplified representation of a biological molecule, possibly a protein or a complex organic compound. The use of different colors helps to distinguish the various components within the structure.
Comma v0.1 1T and 2T—7B LLMs trained on openly licensed text
It’s been a long time coming, but we finally have some promising LLMs to try out which are trained entirely on openly licensed text!
[... 656 words]Run Your Own AI (via) Anthony Lewis published this neat, concise tutorial on using my LLM tool to run local models on your own machine, using llm-mlx.
An under-appreciated way to contribute to open source projects is to publish unofficial guides like this one. Always brightens my day when something like this shows up.
deepseek-ai/DeepSeek-R1-0528. Sadly the trend for terrible naming of models has infested the Chinese AI labs as well.
DeepSeek-R1-0528 is a brand new and much improved open weights reasoning model from DeepSeek, a major step up from the DeepSeek R1 they released back in January.
In the latest update, DeepSeek R1 has significantly improved its depth of reasoning and inference capabilities by [...] Its overall performance is now approaching that of leading models, such as O3 and Gemini 2.5 Pro. [...]
Beyond its improved reasoning capabilities, this version also offers a reduced hallucination rate, enhanced support for function calling, and better experience for vibe coding.
The new R1 comes in two sizes: a 685B model called deepseek-ai/DeepSeek-R1-0528 (the previous R1 was 671B) and an 8B variant distilled from Qwen 3 called deepseek-ai/DeepSeek-R1-0528-Qwen3-8B.
The January release of R1 had a much larger collection of distilled models: four based on Qwen 2.5 (14B, 32B, Math 1.5B and Math 7B) and 2 based on Llama 3 (Llama-3.1 8B and Llama 3.3 70B Instruct).
No Llama model at all this time. I wonder if that's because Qwen 3 is really good and Apache 2 licensed, while Llama continues to stick with their janky license terms.
Further adding to the confusion, Ollama have mixed the two new models into their existing deepseek-r1 label. Last week running ollama pull deepseek-r1:8B from Ollama would get you DeepSeek-R1-Distill-Llama-8B (Internet Archive link), today that same command gets you DeepSeek-R1-0528-Qwen3-8B, a completely different base model.
If this bothers you as much as it bothers me, thankfully you can use the more explicit tag deepseek-r1:8b-0528-qwen3-q8_0.
Update: This is a great illustration of how confusing these names are! Ollama's deepseek-r1:8B alias actually points to deepseek-r1:8b-0528-qwen3-q4_K_M, a 5.2GB model. I pulled the larger q8_0 one.
I ran it like this:
ollama pull deepseek-r1:8b-0528-qwen3-q8_0
It fetched 8.9GB of model weights, then I had it draw me a pelican.
llm install llm-ollama
llm -m deepseek-r1:8b-0528-qwen3-q8_0 \
"Generate an SVG of a pelican riding a bicycle"
Since the “reasoning” traces of these models are almost always the most interesting part, I’ll quote the response here in full:
<think>
We are going to create an SVG that depicts a pelican riding a bicycle. Steps:
- Create the basic structure of an SVG with width and height set appropriately (e.g., 400x200).
- Draw a pelican: We'll break it down into parts - body, beak, eye, feet, wings, etc.
- Draw a bicycle: We can represent it as two circles for wheels, a rectangle for the frame, and some other details.
Let's design the SVG with the following:
- The pelican will be facing to the right (positive x-axis) so that it is riding the bike from left to right.
- The bicycle will have two wheels and a simple frame in front of the pelican.
We'll use absolute positioning for each part. Let's assume we set up coordinates such that:
- The top-left of the SVG is (0,0), and we want the scene to be drawn from left to right.
- The pelican will be positioned at (50, 120) with a body length of about 30 units.
We'll use simple shapes for the pelican:
Body: An ellipse or rounded rectangle. Let's do an ellipse for the body. Beak: A triangle pointing to the right. Head: Another ellipse but smaller and positioned in front of the body. Wings: Two triangles (one above each other, one slightly behind) that are upside down.
Bicycle:
- Wheels: two circles at fixed positions relative to the frame.
- Frame: a rectangle with some details for handlebars and seat.
Since this is a fun illustration, we'll keep it simple but recognizable.
Let's code accordingly.
</think>
Here’s an SVG of a pelican riding a bicycle. This example uses basic shapes to create a stylized version:<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 400 200"> <!-- Pelican body --> <ellipse cx="150" cy="150" rx="80" ry="60" fill="#FFD700"/> <!-- Pelican head (larger for comedic effect) --> <circle cx="90" cy="120" r="45" fill="#FFA3CE"/> <!-- Pelican beak --> <polygon points="80,110 60,120 80,130 70,140 60,150" fill="#FFC233"/> <!-- Pelican eye --> <circle cx="95" cy="115" r="3" fill="#fff"/> <!-- Bicycle wheels --> <ellipse cx="380" cy="140" rx="25" ry="60" transform="rotate(90 380 140)" fill="black"/> <ellipse cx="380" cy="70" rx="25" ry="60" transform="rotate(90 380 70)" fill="black"/> <!-- Bicycle frame --> <path d="M 15,40 L 15,140 H 370 L 370,140 V 40 Z" stroke="gray" stroke-width="6" fill="none"/> <!-- Handlebars and seat (stylized) --> <path d="M 280,40 C 290,35 300,30 310,40 C 320,50 330,60 310,70 L 310,70 Q 290,50 280,40" fill="none" stroke="gray"/> <!-- Pedals --> <circle cx="340" cy="70" r="15" fill="#3366CC"/> <polygon points="340,65 330,45 350,45" fill="#F29E3D"/> <circle cx="340" cy="140" r="15" fill="#3366CC"/> <polygon points="340,135 330,115 350,115" fill="#F29E3D"/> <!-- Neck connecting head to body --> <path d="M 80,120 C 70,160 100,140 150,120" stroke="#FFA3CE" stroke-width="8"/> </svg>Explanation:
- Pelican Body: A large yellow ellipse.
- Head: A pink circle with a prominent beak (yellow-orange triangle).
- Bicycle:
- Wheels are black ellipses rotated vertically to simulate spokes.
- The frame is a gray rectangle extending from the pelican’s back to the right side of the SVG.
- Handlebars and seat are simplified curves in gray.
This creates a comical scene with the pelican riding forward. You can adjust colors, sizes, or positions by modifying
cx,cy,rx,ryattributes and fill/stroke values.
Love the thought process, and the explanation! The actual rendered SVG does leave a lot to be desired though:
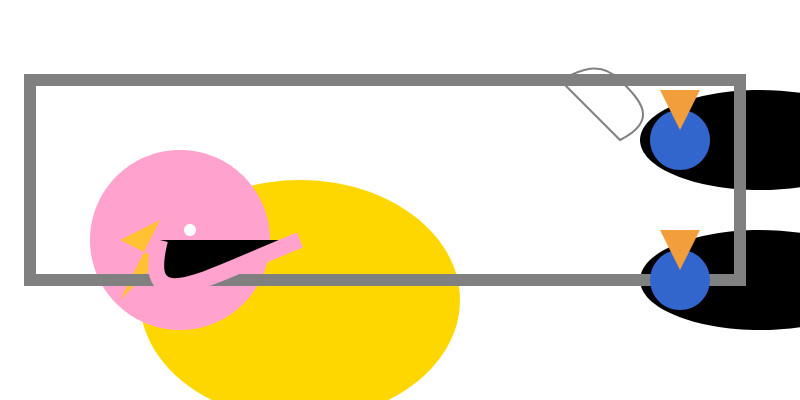
To be fair, this is just using the ~8GB Qwen3 Q8_0 model on my laptop. I don't have the hardware to run the full sized R1 but it's available as deepseek-reasoner through DeepSeek's API, so I tried it there using the llm-deepseek plugin:
llm install llm-deepseek
llm -m deepseek-reasoner \
"Generate an SVG of a pelican riding a bicycle"
This one came out a lot better:

Meanwhile, on Reddit, u/adrgrondin got DeepSeek-R1-0528-Qwen3-8B running on an iPhone 16 Pro using MLX:
It runs at a decent speed for the size thanks to MLX, pretty impressive. But not really usable in my opinion, the model is thinking for too long, and the phone gets really hot.
qwen2.5vl in Ollama. Ollama announced a complete overhaul of their vision support the other day. Here's the first new model they've shipped since then - a packaged version of Qwen 2.5 VL which was first released on January 26th 2025. Here are my notes from that release.
I upgraded Ollama (it auto-updates so I just had to restart it from the tray icon) and ran this:
ollama pull qwen2.5vl
This downloaded a 6GB model file. I tried it out against my photo of Cleo rolling on the beach:
llm -a https://static.simonwillison.net/static/2025/cleo-sand.jpg \
'describe this image' -m qwen2.5vl
And got a pretty good result:
The image shows a dog lying on its back on a sandy beach. The dog appears to be a medium to large breed with a dark coat, possibly black or dark brown. It is wearing a red collar or harness around its chest. The dog's legs are spread out, and its belly is exposed, suggesting it might be rolling around or playing in the sand. The sand is light-colored and appears to be dry, with some small footprints and marks visible around the dog. The lighting in the image suggests it is taken during the daytime, with the sun casting a shadow of the dog to the left side of the image. The overall scene gives a relaxed and playful impression, typical of a dog enjoying time outdoors on a beach.
Qwen 2.5 VL has a strong reputation for OCR, so I tried it on my poster:
llm -a https://static.simonwillison.net/static/2025/poster.jpg \
'convert to markdown' -m qwen2.5vl
The result that came back:
It looks like the image you provided is a jumbled and distorted text, making it difficult to interpret. If you have a specific question or need help with a particular topic, please feel free to ask, and I'll do my best to assist you!
I'm not sure what went wrong here. My best guess is that the maximum resolution the model can handle is too small to make out the text, or maybe Ollama resized the image to the point of illegibility before handing it to the model?
Update: I think this may be a bug relating to URL handling in LLM/llm-ollama. I tried downloading the file first:
wget https://static.simonwillison.net/static/2025/poster.jpg
llm -m qwen2.5vl 'extract text' -a poster.jpg
This time it did a lot better. The results weren't perfect though - it ended up stuck in a loop outputting the same code example dozens of times.
I tried with a different prompt - "extract text" - and it got confused by the three column layout, misread Datasette as "Datasetette" and missed some of the text. Here's that result.
These experiments used qwen2.5vl:7b (6GB) - I expect the results would be better with the larger qwen2.5vl:32b (21GB) and qwen2.5vl:72b (71GB) models.
Fred Jonsson reported a better result using the MLX model via LM studio (~9GB model running in 8bit - I think that's mlx-community/Qwen2.5-VL-7B-Instruct-8bit). His full output is here - looks almost exactly right to me.
Having tried a few of the Qwen 3 models now my favorite is a bit of a surprise to me: I'm really enjoying Qwen3-8B.
I've been running prompts through the MLX 4bit quantized version, mlx-community/Qwen3-8B-4bit. I'm using llm-mlx like this:
llm install llm-mlx
llm mlx download-model mlx-community/Qwen3-8B-4bit
This pulls 4.3GB of data and saves it to ~/.cache/huggingface/hub/models--mlx-community--Qwen3-8B-4bit.
I assigned it a default alias:
llm aliases set q3 mlx-community/Qwen3-8B-4bit
I also added a default option for that model - this saves me from adding -o unlimited 1 to every prompt which disables the default output token limit:
llm models options set q3 unlimited 1
And now I can run prompts:
llm -m q3 'brainstorm questions I can ask my friend who I think is secretly from Atlantis that will not tip her off to my suspicions'
Qwen3 is a "reasoning" model, so it starts each prompt with a <think> block containing its chain of thought. Reading these is always really fun. Here's the full response I got for the above question.
I'm finding Qwen3-8B to be surprisingly capable for useful things too. It can summarize short articles. It can write simple SQL queries given a question and a schema. It can figure out what a simple web app does by reading the HTML and JavaScript. It can write Python code to meet a paragraph long spec - for that one it "reasoned" for an unreasonably long time but it did eventually get to a useful answer.
All this while consuming between 4 and 5GB of memory, depending on the length of the prompt.
I think it's pretty extraordinary that a few GBs of floating point numbers can usefully achieve these various tasks, especially using so little memory that it's not an imposition on the rest of the things I want to run on my laptop at the same time.
Qwen 3 offers a case study in how to effectively release a model
Alibaba’s Qwen team released the hotly anticipated Qwen 3 model family today. The Qwen models are already some of the best open weight models—Apache 2.0 licensed and with a variety of different capabilities (including vision and audio input/output).
[... 1,462 words]llm-fragments-github 0.2.
I upgraded my llm-fragments-github plugin to add a new fragment type called issue. It lets you pull the entire content of a GitHub issue thread into your prompt as a concatenated Markdown file.
(If you haven't seen fragments before I introduced them in Long context support in LLM 0.24 using fragments and template plugins.)
I used it just now to have Gemini 2.5 Pro provide feedback and attempt an implementation of a complex issue against my LLM project:
llm install llm-fragments-github
llm -f github:simonw/llm \
-f issue:simonw/llm/938 \
-m gemini-2.5-pro-exp-03-25 \
--system 'muse on this issue, then propose a whole bunch of code to help implement it'
Here I'm loading the FULL content of the simonw/llm repo using that -f github:simonw/llm fragment (documented here), then loading all of the comments from issue 938 where I discuss quite a complex potential refactoring. I ask Gemini 2.5 Pro to "muse on this issue" and come up with some code.
This worked shockingly well. Here's the full response, which highlighted a few things I hadn't considered yet (such as the need to migrate old database records to the new tree hierarchy) and then spat out a whole bunch of code which looks like a solid start to the actual implementation work I need to do.
I ran this against Google's free Gemini 2.5 Preview, but if I'd used the paid model it would have cost me 202,680 input tokens, 10,460 output tokens and 1,859 thinking tokens for a total of 62.989 cents.
As a fun extra, the new issue: feature itself was written almost entirely by OpenAI o3, again using fragments. I ran this:
llm -m openai/o3 \ -f https://raw.githubusercontent.com/simonw/llm-hacker-news/refs/heads/main/llm_hacker_news.py \ -f https://raw.githubusercontent.com/simonw/tools/refs/heads/main/github-issue-to-markdown.html \ -s 'Write a new fragments plugin in Python that registers issue:org/repo/123 which fetches that issue number from the specified github repo and uses the same markdown logic as the HTML page to turn that into a fragment'
Here I'm using the ability to pass a URL to -f and giving it the full source of my llm_hacker_news.py plugin (which shows how a fragment can load data from an API) plus the HTML source of my github-issue-to-markdown tool (which I wrote a few months ago with Claude). I effectively asked o3 to take that HTML/JavaScript tool and port it to Python to work with my fragments plugin mechanism.
o3 provided almost the exact implementation I needed, and even included support for a GITHUB_TOKEN environment variable without me thinking to ask for it. Total cost: 19.928 cents.
On a final note of curiosity I tried running this prompt against Gemma 3 27B QAT running on my Mac via MLX and llm-mlx:
llm install llm-mlx llm mlx download-model mlx-community/gemma-3-27b-it-qat-4bit llm -m mlx-community/gemma-3-27b-it-qat-4bit \ -f https://raw.githubusercontent.com/simonw/llm-hacker-news/refs/heads/main/llm_hacker_news.py \ -f https://raw.githubusercontent.com/simonw/tools/refs/heads/main/github-issue-to-markdown.html \ -s 'Write a new fragments plugin in Python that registers issue:org/repo/123 which fetches that issue number from the specified github repo and uses the same markdown logic as the HTML page to turn that into a fragment'
That worked pretty well too. It turns out a 16GB local model file is powerful enough to write me an LLM plugin now!
Gemma 3 QAT Models. Interesting release from Google, as a follow-up to Gemma 3 from last month:
To make Gemma 3 even more accessible, we are announcing new versions optimized with Quantization-Aware Training (QAT) that dramatically reduces memory requirements while maintaining high quality. This enables you to run powerful models like Gemma 3 27B locally on consumer-grade GPUs like the NVIDIA RTX 3090.
I wasn't previously aware of Quantization-Aware Training but it turns out to be quite an established pattern now, supported in both Tensorflow and PyTorch.
Google report model size drops from BF16 to int4 for the following models:
- Gemma 3 27B: 54GB to 14.1GB
- Gemma 3 12B: 24GB to 6.6GB
- Gemma 3 4B: 8GB to 2.6GB
- Gemma 3 1B: 2GB to 0.5GB
They partnered with Ollama, LM Studio, MLX (here's their collection) and llama.cpp for this release - I'd love to see more AI labs following their example.
The Ollama model version picker currently hides them behind "View all" option, so here are the direct links:
- gemma3:1b-it-qat - 1GB
- gemma3:4b-it-qat - 4GB
- gemma3:12b-it-qat - 8.9GB
- gemma3:27b-it-qat - 18GB
I fetched that largest model with:
ollama pull gemma3:27b-it-qat
And now I'm trying it out with llm-ollama:
llm -m gemma3:27b-it-qat "impress me with some physics"
I got a pretty great response!
Update: Having spent a while putting it through its paces via Open WebUI and Tailscale to access my laptop from my phone I think this may be my new favorite general-purpose local model. Ollama appears to use 22GB of RAM while the model is running, which leaves plenty on my 64GB machine for other applications.
I've also tried it via llm-mlx like this (downloading 16GB):
llm install llm-mlx
llm mlx download-model mlx-community/gemma-3-27b-it-qat-4bit
llm chat -m mlx-community/gemma-3-27b-it-qat-4bit
It feels a little faster with MLX and uses 15GB of memory according to Activity Monitor.
Initial impressions of Llama 4
Dropping a model release as significant as Llama 4 on a weekend is plain unfair! So far the best place to learn about the new model family is this post on the Meta AI blog. They’ve released two new models today: Llama 4 Maverick is a 400B model (128 experts, 17B active parameters), text and image input with a 1 million token context length. Llama 4 Scout is 109B total parameters (16 experts, 17B active), also multi-modal and with a claimed 10 million token context length—an industry first.
[... 1,468 words]Qwen2.5-VL-32B: Smarter and Lighter. The second big open weight LLM release from China today - the first being DeepSeek v3-0324.
Qwen's previous vision model was Qwen2.5 VL, released in January in 3B, 7B and 72B sizes.
Today's Apache 2.0 licensed release is a 32B model, which is quickly becoming my personal favourite model size - large enough to have GPT-4-class capabilities, but small enough that on my 64GB Mac there's still enough RAM for me to run other memory-hungry applications like Firefox and VS Code.
Qwen claim that the new model (when compared to their previous 2.5 VL family) can "align more closely with human preferences", is better at "mathematical reasoning" and provides "enhanced accuracy and detailed analysis in tasks such as image parsing, content recognition, and visual logic deduction".
They also offer some presumably carefully selected benchmark results showing it out-performing Gemma 3-27B, Mistral Small 3.1 24B and GPT-4o-0513 (there have been two more recent GPT-4o releases since that one, 2024-08-16 and 2024-11-20).
As usual, Prince Canuma had MLX versions of the models live within hours of the release, in 4 bit, 6 bit, 8 bit, and bf16 variants.
I ran the 4bit version (a 18GB model download) using uv and Prince's mlx-vlm like this:
uv run --with 'numpy<2' --with mlx-vlm \
python -m mlx_vlm.generate \
--model mlx-community/Qwen2.5-VL-32B-Instruct-4bit \
--max-tokens 1000 \
--temperature 0.0 \
--prompt "Describe this image." \
--image Mpaboundrycdfw-1.pngHere's the image:
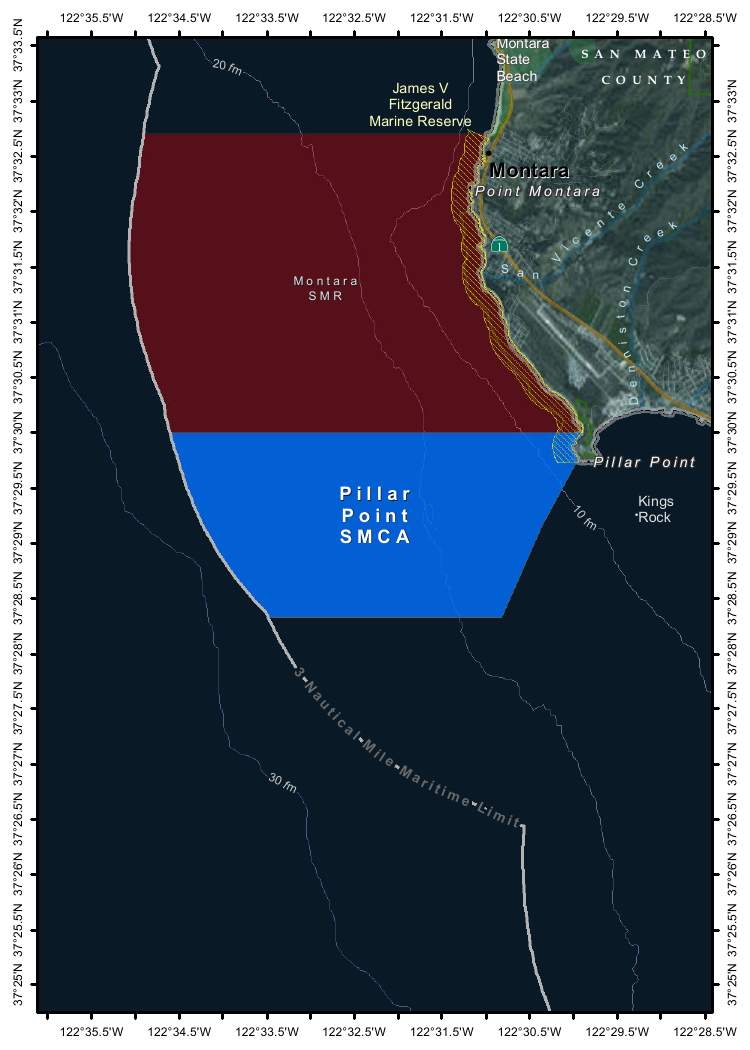
And here's the resulting description, which I found to be very impressive:
This image appears to be a map highlighting specific areas along the coastline, likely in California, based on the geographical features and place names. Here is a detailed description of the image:
Geographic Features:
- The map shows a section of the coastline, with land on the right and the sea on the left.
- The land area includes parts of SanMateo County, as noted in the top-right corner.
- The coastline features several named locations, including:
- Point Montara
- Pillar Point
- Kings Rock
- VicenteCreek
- DennistonCreek
- State Beach
Highlighted Areas:
- The map contains two distinct areas marked with different colors:
- Red Area (Top Section)
- Labeled as "MONTARA" and "MONTARA M R" (possibly referring to a "Marine Reserves" or similar protected area).
- This area is marked with a dark red color and extends from the coastline inland.
- Blue Area (Bottom Section)
- Labeled as "PILLAR" and "PILLAR P O I N T" along with "SMCA" (Special Management Area).
- This area is marked with a blue color and is located closer to the coastline, including the area around "Pillar Point."
Depth Contours:
- The map includes depth markings in the sea, indicating the bathymetrical features:
- 20 fathom (fm) line is marked in the upper-left part of the sea.
- 10 fathom (fm) line is marked closer to the coastline.
- 30 fathom (fm) line is marked further out to sea.
Other Features:
- State Beach: Marked near the top-right, indicating a protected recreational area.
- Kings Rock: A prominent feature near the coastline, likely a rocky outcropping.
- Creeks: The map shows several creeks, including VicenteCreek and DennistonCreek, which flow into the sea.
Protected Areas:
- The map highlights specific protected areas:
- Marine Reserves:
- "MONTARA M R" (Marine Reserves) in red.
- Special Management Area (SMCA)
- "PILLAR P O I N T" in blue, indicating a Special Management Area.
Grid and Coordinates:
- The map includes a grid with latitude and longitude markings:
- Latitude ranges from approximately 37°25'N to 37°35'N.
- Longitude ranges from approximately 122°22.5'W to 122°35.5'W.
Topography:
- The land area shows topographic features, including elevations and vegetation, with green areas indicating higher elevations or vegetated land.
Other Labels:
- "SMR": Likely stands for "State Managed Reserves."
- "SMCA": Likely stands for "Special Management Control Area."
In summary, this map highlights specific protected areas along the coastline, including a red "Marine Reserves" area and a blue "Special Management Area" near "Pillar Point." The map also includes depth markings, geographical features, and place names, providing a detailed view of the region's natural and protected areas.
It included the following runtime statistics:
Prompt: 1051 tokens, 111.985 tokens-per-sec
Generation: 760 tokens, 17.328 tokens-per-sec
Peak memory: 21.110 GB
deepseek-ai/DeepSeek-V3-0324.
Chinese AI lab DeepSeek just released the latest version of their enormous DeepSeek v3 model, baking the release date into the name DeepSeek-V3-0324.
The license is MIT (that's new - previous DeepSeek v3 had a custom license), the README is empty and the release adds up a to a total of 641 GB of files, mostly of the form model-00035-of-000163.safetensors.
The model only came out a few hours ago and MLX developer Awni Hannun already has it running at >20 tokens/second on a 512GB M3 Ultra Mac Studio ($9,499 of ostensibly consumer-grade hardware) via mlx-lm and this mlx-community/DeepSeek-V3-0324-4bit 4bit quantization, which reduces the on-disk size to 352 GB.
I think that means if you have that machine you can run it with my llm-mlx plugin like this, but I've not tried myself!
llm mlx download-model mlx-community/DeepSeek-V3-0324-4bit
llm chat -m mlx-community/DeepSeek-V3-0324-4bit
The new model is also listed on OpenRouter. You can try a chat at openrouter.ai/chat?models=deepseek/deepseek-chat-v3-0324:free.
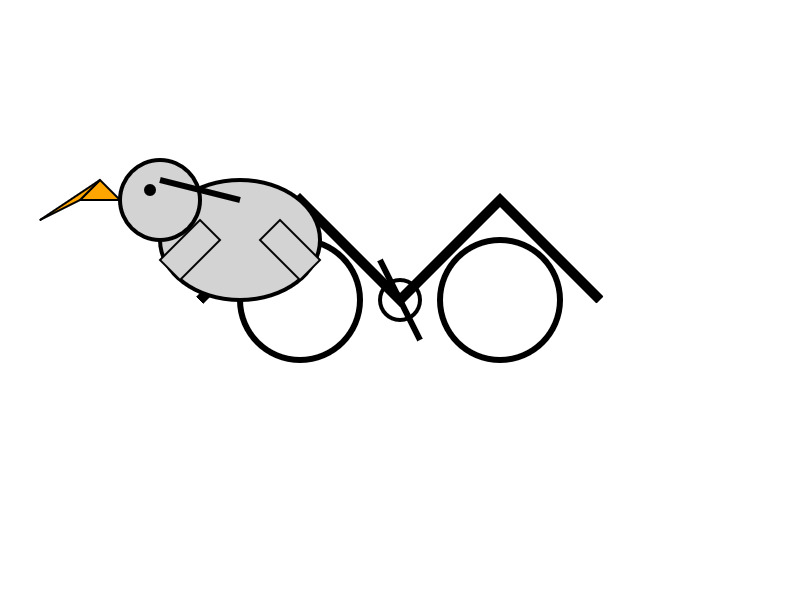
Here's what the chat interface gave me for "Generate an SVG of a pelican riding a bicycle":
I have two API keys with OpenRouter - one of them worked with the model, the other gave me a No endpoints found matching your data policy error - I think because I had a setting on that key disallowing models from training on my activity. The key that worked was a free key with no attached billing credentials.
For my working API key the llm-openrouter plugin let me run a prompt like this:
llm install llm-openrouter
llm keys set openrouter
# Paste key here
llm -m openrouter/deepseek/deepseek-chat-v3-0324:free "best fact about a pelican"
Here's that "best fact" - the terminal output included Markdown and an emoji combo, here that's rendered.
One of the most fascinating facts about pelicans is their unique throat pouch, called a gular sac, which can hold up to 3 gallons (11 liters) of water—three times more than their stomach!
Here’s why it’s amazing:
- Fishing Tool: They use it like a net to scoop up fish, then drain the water before swallowing.
- Cooling Mechanism: On hot days, pelicans flutter the pouch to stay cool by evaporating water.
- Built-in "Shopping Cart": Some species even use it to carry food back to their chicks.Bonus fact: Pelicans often fish cooperatively, herding fish into shallow water for an easy catch.
Would you like more cool pelican facts? 🐦🌊
In putting this post together I got Claude to build me this new tool for finding the total on-disk size of a Hugging Face repository, which is available in their API but not currently displayed on their website.
Update: Here's a notable independent benchmark from Paul Gauthier:
DeepSeek's new V3 scored 55% on aider's polyglot benchmark, significantly improving over the prior version. It's the #2 non-thinking/reasoning model, behind only Sonnet 3.7. V3 is competitive with thinking models like R1 & o3-mini.
Mistral Small 3.1. Mistral Small 3 came out in January and was a notable, genuinely excellent local model that used an Apache 2.0 license.
Mistral Small 3.1 offers a significant improvement: it's multi-modal (images) and has an increased 128,000 token context length, while still "fitting within a single RTX 4090 or a 32GB RAM MacBook once quantized" (according to their model card). Mistral's own benchmarks show it outperforming Gemma 3 and GPT-4o Mini, but I haven't seen confirmation from external benchmarks.
Despite their mention of a 32GB MacBook I haven't actually seen any quantized GGUF or MLX releases yet, which is a little surprising since they partnered with Ollama on launch day for their previous Mistral Small 3. I expect we'll see various quantized models released by the community shortly.
Update 20th March 2025: I've now run the text version on my laptop using mlx-community/Mistral-Small-3.1-Text-24B-Instruct-2503-8bit and llm-mlx:
llm mlx download-model mlx-community/Mistral-Small-3.1-Text-24B-Instruct-2503-8bit -a mistral-small-3.1
llm chat -m mistral-small-3.1
The model can be accessed via Mistral's La Plateforme API, which means you can use it via my llm-mistral plugin.
Here's the model describing my photo of two pelicans in flight:
{kind=link}
llm install llm-mistral
# Run this if you have previously installed the plugin:
llm mistral refresh
llm -m mistral/mistral-small-2503 'describe' \
-a https://static.simonwillison.net/static/2025/two-pelicans.jpg
The image depicts two brown pelicans in flight against a clear blue sky. Pelicans are large water birds known for their long bills and large throat pouches, which they use for catching fish. The birds in the image have long, pointed wings and are soaring gracefully. Their bodies are streamlined, and their heads and necks are elongated. The pelicans appear to be in mid-flight, possibly gliding or searching for food. The clear blue sky in the background provides a stark contrast, highlighting the birds' silhouettes and making them stand out prominently.
I added Mistral's API prices to my tools.simonwillison.net/llm-prices pricing calculator by pasting screenshots of Mistral's pricing tables into Claude.
mlx-community/OLMo-2-0325-32B-Instruct-4bit (via) OLMo 2 32B claims to be "the first fully-open model (all data, code, weights, and details are freely available) to outperform GPT3.5-Turbo and GPT-4o mini". Thanks to the MLX project here's a recipe that worked for me to run it on my Mac, via my llm-mlx plugin.
To install the model:
llm install llm-mlx
llm mlx download-model mlx-community/OLMo-2-0325-32B-Instruct-4bit
That downloads 17GB to ~/.cache/huggingface/hub/models--mlx-community--OLMo-2-0325-32B-Instruct-4bit.
To start an interactive chat with OLMo 2:
llm chat -m mlx-community/OLMo-2-0325-32B-Instruct-4bit
Or to run a prompt:
llm -m mlx-community/OLMo-2-0325-32B-Instruct-4bit 'Generate an SVG of a pelican riding a bicycle' -o unlimited 1
The -o unlimited 1 removes the cap on the number of output tokens - the default for llm-mlx is 1024 which isn't enough to attempt to draw a pelican.
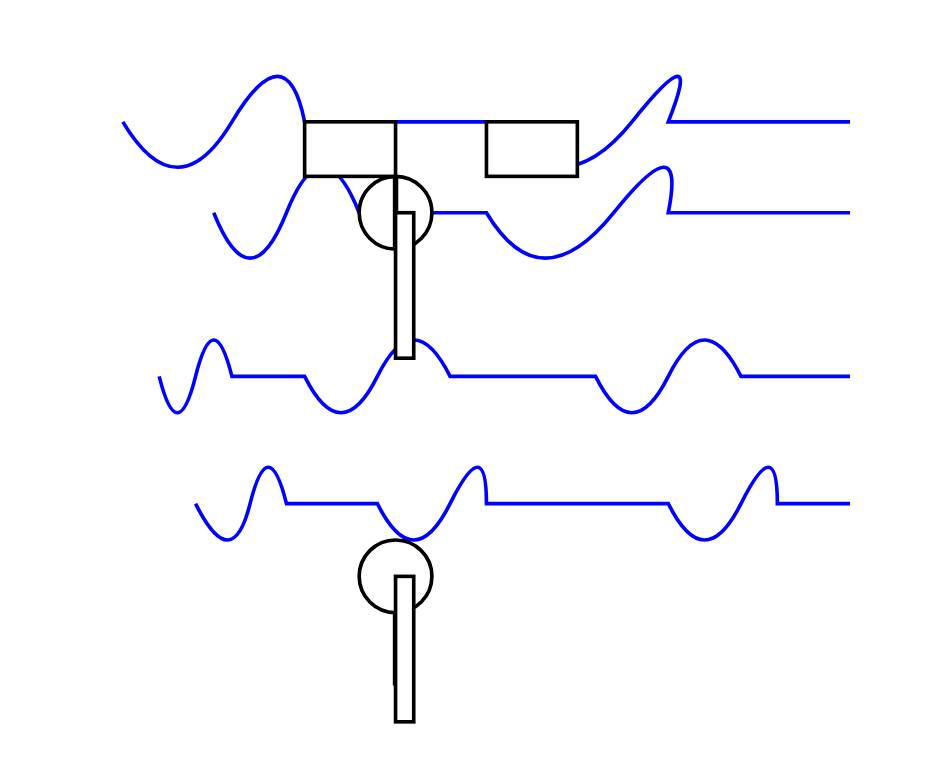
The pelican it drew is refreshingly abstract:
Notes on Google’s Gemma 3
Google’s Gemma team released an impressive new model today (under their not-open-source Gemma license). Gemma 3 comes in four sizes—1B, 4B, 12B, and 27B—and while 1B is text-only the larger three models are all multi-modal for vision:
[... 804 words]QwQ-32B: Embracing the Power of Reinforcement Learning (via) New Apache 2 licensed reasoning model from Qwen:
We are excited to introduce QwQ-32B, a model with 32 billion parameters that achieves performance comparable to DeepSeek-R1, which boasts 671 billion parameters (with 37 billion activated). This remarkable outcome underscores the effectiveness of RL when applied to robust foundation models pretrained on extensive world knowledge.
I had a lot of fun trying out their previous QwQ reasoning model last November. I demonstrated this new QwQ in my talk at NICAR about recent LLM developments. Here's the example I ran.
{kind=link}
LM Studio just released GGUFs ranging in size from 17.2 to 34.8 GB. MLX have compatible weights published in 3bit, 4bit, 6bit and 8bit. Ollama has the new qwq too - it looks like they've renamed the previous November release qwq:32b-preview.
Run LLMs on macOS using llm-mlx and Apple’s MLX framework
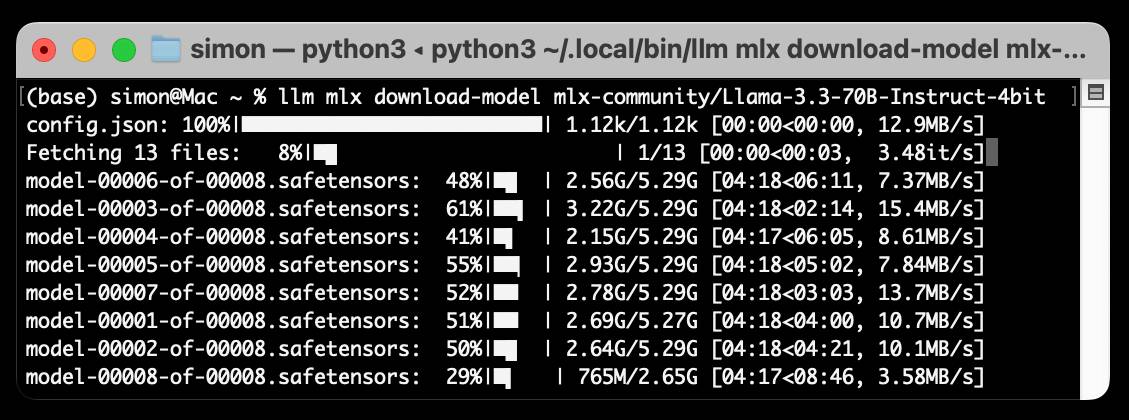
llm-mlx is a brand new plugin for my LLM Python Library and CLI utility which builds on top of Apple’s excellent MLX array framework library and mlx-lm package. If you’re a terminal user or Python developer with a Mac this may be the new easiest way to start exploring local Large Language Models.
[... 1,524 words]Qwen2.5 VL! Qwen2.5 VL! Qwen2.5 VL! Hot on the heels of yesterday's Qwen2.5-1M, here's Qwen2.5 VL (with an excitable announcement title) - the latest in Qwen's series of vision LLMs.
They're releasing multiple versions: base models and instruction tuned models at 3B, 7B and 72B. There's a lot of additional information in their README.
The 72B model can be selected on Qwen's Qwen Chat interface. I gave it this image of our dog Cleo joy rolling on the beach:

And prompted:
Describe this image in detail, be flowery
(Since the Qwen team tends to use flowery language in their announcements.)
Here's what I got back:
In this enchanting tableau, a canine companion finds solace in the embrace of nature's softest bed. The sandy expanse stretches out like an endless canvas, its surface etched with the delicate imprints of countless wanderers who have come and gone, leaving behind a tapestry of footprints that whisper tales of joyous romps and serene strolls.
The dog, a vision of contentment, lies sprawled upon the sand, its dark fur gleaming under the gentle caress of the sun. Its body is relaxed, limbs splayed in abandon, as if it has surrendered to the soothing rhythm of the beach. A vibrant red collar adorns its neck, a splash of color against the muted tones of the surroundings, hinting at the care and love bestowed upon this cherished pet.
The sand itself is a work of art, its grains shimmering with a silvery sheen that catches the light. Here and there, small tufts of seaweed peek through, remnants of the ocean's bounty, adding a touch of wild beauty to the scene. The shadows cast by unseen objects dance across the sand, creating a play of light and dark that lends an air of mystery to the tranquil setting.
This moment, frozen in time, speaks of peace and harmony, where man's best friend finds respite in the simple pleasures of life. It is a scene that invites one to pause, breathe deeply, and revel in the serenity of nature's embrace.
I'm looking forward to trying out their smaller models - the 3B model in particular should be small enough to run comfortably even on an iPhone, so hopefully someone will wire up an example of that soon (maybe using MLX).
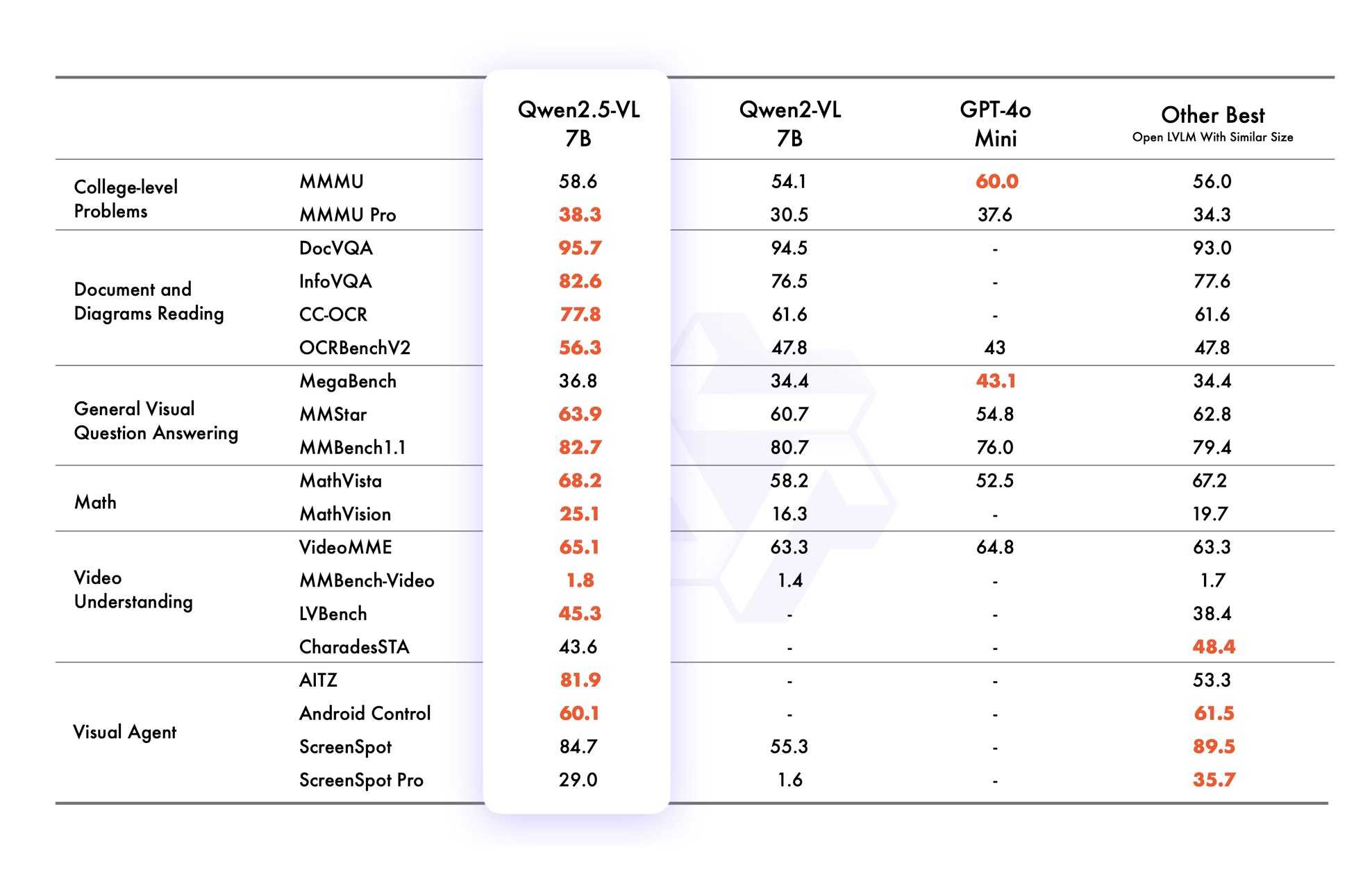
VB points out that the vision benchmarks for Qwen 2.5 VL 7B show it out-performing GPT-4o mini!
Qwen2.5 VL cookbooks
Qwen also just published a set of cookbook recipes:
- universal_recognition.ipynb demonstrates basic visual Q&A, including prompts like
Who are these in this picture? Please give their names in Chinese and Englishagainst photos of celebrities, an ability other models have deliberately suppressed. - spatial_understanding.ipynb demonstrates bounding box support, with prompts like
Locate the top right brown cake, output its bbox coordinates using JSON format. - video_understanding.ipynb breaks a video into individual frames and asks questions like
Could you go into detail about the content of this long video? - ocr.ipynb shows
Qwen2.5-VL-7B-Instructperforming OCR in multiple different languages. - document_parsing.ipynb uses Qwen to convert images of documents to HTML and other formats, and notes that "we introduce a unique Qwenvl HTML format that includes positional information for each component, enabling precise document reconstruction and manipulation."
- mobile_agent.ipynb runs Qwen with tool use against tools for controlling a mobile phone, similar to ChatGPT Operator or Claude Computer Use.
- computer_use.ipynb showcases "GUI grounding" - feeding in screenshots of a user's desktop and running tools for things like left clicking on a specific coordinate.
Running it with mlx-vlm
Update 30th January 2025: I got it working on my Mac using uv and mlx-vlm, with some hints from this issue. Here's the recipe that worked (downloading a 9GB model from mlx-community/Qwen2.5-VL-7B-Instruct-8bit):
uv run --with 'numpy<2' --with 'git+https://github.com/huggingface/transformers' \
--with mlx-vlm \
python -m mlx_vlm.generate \
--model mlx-community/Qwen2.5-VL-7B-Instruct-8bit \
--max-tokens 100 \
--temp 0.0 \
--prompt "Describe this image." \
--image path-to-image.pngI ran that against this image:
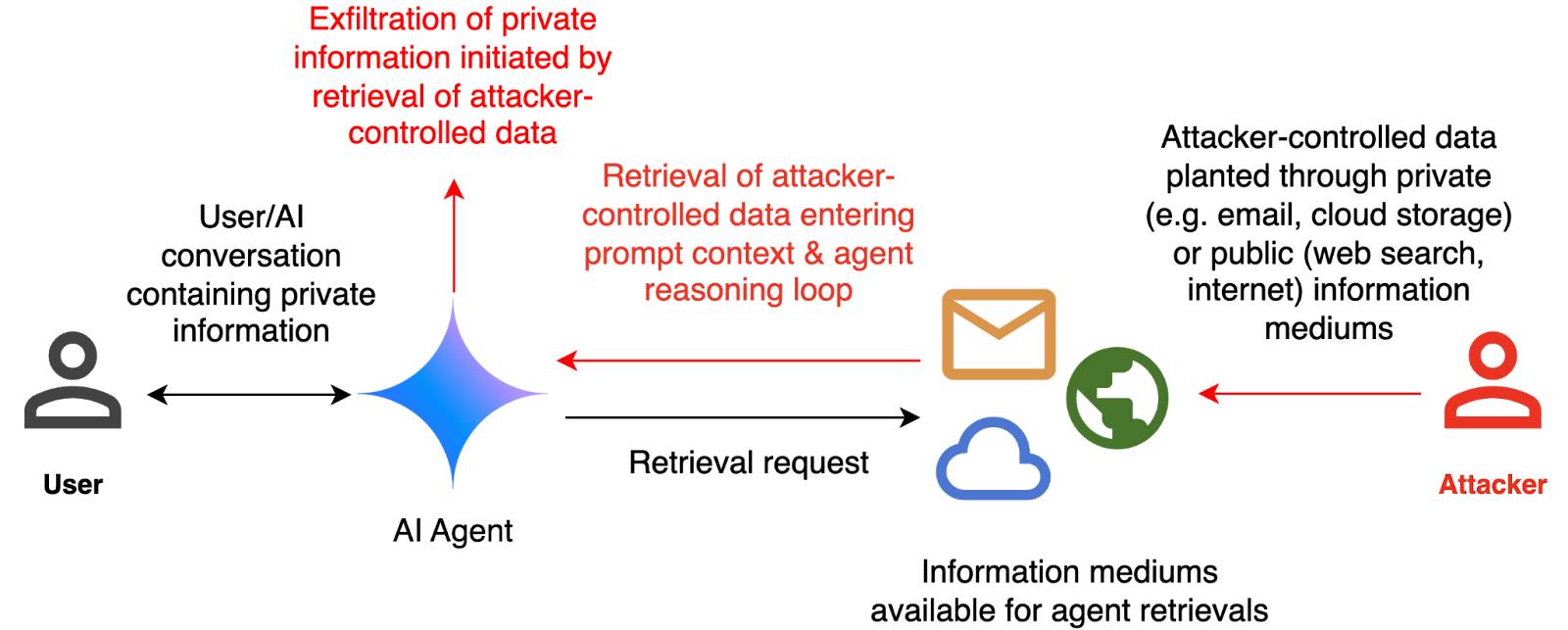
And got back this result:
The image appears to illustrate a flowchart or diagram related to a cybersecurity scenario. Here's a breakdown of the elements:
- User: Represented by a simple icon of a person.
- AI Agent: Represented by a blue diamond shape.
- Attacker: Represented by a red icon of a person.
- Cloud and Email Icons: Represented by a cloud and an envelope, indicating data or information being transferred.
- Text: The text
The impact of competition and DeepSeek on Nvidia (via) Long, excellent piece by Jeffrey Emanuel capturing the current state of the AI/LLM industry. The original title is "The Short Case for Nvidia Stock" - I'm using the Hacker News alternative title here, but even that I feel under-sells this essay.
Jeffrey has a rare combination of experience in both computer science and investment analysis. He combines both worlds here, evaluating NVIDIA's challenges by providing deep insight into a whole host of relevant and interesting topics.
As Jeffrey describes it, NVIDA's moat has four components: high-quality Linux drivers, CUDA as an industry standard, the fast GPU interconnect technology they acquired from Mellanox in 2019 and the flywheel effect where they can invest their enormous profits (75-90% margin in some cases!) into more R&D.
Each of these is under threat.
Technologies like MLX, Triton and JAX are undermining the CUDA advantage by making it easier for ML developers to target multiple backends - plus LLMs themselves are getting capable enough to help port things to alternative architectures.
GPU interconnect helps multiple GPUs work together on tasks like model training. Companies like Cerebras are developing enormous chips that can get way more done on a single chip.
Those 75-90% margins provide a huge incentive for other companies to catch up - including the customers who spend the most on NVIDIA at the moment - Microsoft, Amazon, Meta, Google, Apple - all of whom have their own internal silicon projects:
Now, it's no secret that there is a strong power law distribution of Nvidia's hyper-scaler customer base, with the top handful of customers representing the lion's share of high-margin revenue. How should one think about the future of this business when literally every single one of these VIP customers is building their own custom chips specifically for AI training and inference?
The real joy of this article is the way it describes technical details of modern LLMs in a relatively accessible manner. I love this description of the inference-scaling tricks used by O1 and R1, compared to traditional transformers:
Basically, the way Transformers work in terms of predicting the next token at each step is that, if they start out on a bad "path" in their initial response, they become almost like a prevaricating child who tries to spin a yarn about why they are actually correct, even if they should have realized mid-stream using common sense that what they are saying couldn't possibly be correct.
Because the models are always seeking to be internally consistent and to have each successive generated token flow naturally from the preceding tokens and context, it's very hard for them to course-correct and backtrack. By breaking the inference process into what is effectively many intermediate stages, they can try lots of different things and see what's working and keep trying to course-correct and try other approaches until they can reach a fairly high threshold of confidence that they aren't talking nonsense.
The last quarter of the article talks about the seismic waves rocking the industry right now caused by DeepSeek v3 and R1. v3 remains the top-ranked open weights model, despite being around 45x more efficient in training than its competition: bad news if you are selling GPUs! R1 represents another huge breakthrough in efficiency both for training and for inference - the DeepSeek R1 API is currently 27x cheaper than OpenAI's o1, for a similar level of quality.
Jeffrey summarized some of the key ideas from the v3 paper like this:
A major innovation is their sophisticated mixed-precision training framework that lets them use 8-bit floating point numbers (FP8) throughout the entire training process. [...]
DeepSeek cracked this problem by developing a clever system that breaks numbers into small tiles for activations and blocks for weights, and strategically uses high-precision calculations at key points in the network. Unlike other labs that train in high precision and then compress later (losing some quality in the process), DeepSeek's native FP8 approach means they get the massive memory savings without compromising performance. When you're training across thousands of GPUs, this dramatic reduction in memory requirements per GPU translates into needing far fewer GPUs overall.
Then for R1:
With R1, DeepSeek essentially cracked one of the holy grails of AI: getting models to reason step-by-step without relying on massive supervised datasets. Their DeepSeek-R1-Zero experiment showed something remarkable: using pure reinforcement learning with carefully crafted reward functions, they managed to get models to develop sophisticated reasoning capabilities completely autonomously. This wasn't just about solving problems— the model organically learned to generate long chains of thought, self-verify its work, and allocate more computation time to harder problems.
The technical breakthrough here was their novel approach to reward modeling. Rather than using complex neural reward models that can lead to "reward hacking" (where the model finds bogus ways to boost their rewards that don't actually lead to better real-world model performance), they developed a clever rule-based system that combines accuracy rewards (verifying final answers) with format rewards (encouraging structured thinking). This simpler approach turned out to be more robust and scalable than the process-based reward models that others have tried.
This article is packed with insights like that - it's worth spending the time absorbing the whole thing.
Qwen2.5-1M: Deploy Your Own Qwen with Context Length up to 1M Tokens (via) Very significant new release from Alibaba's Qwen team. Their openly licensed (sometimes Apache 2, sometimes Qwen license, I've had trouble keeping up) Qwen 2.5 LLM previously had an input token limit of 128,000 tokens. This new model increases that to 1 million, using a new technique called Dual Chunk Attention, first described in this paper from February 2024.
They've released two models on Hugging Face: Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M, both requiring CUDA and both under an Apache 2.0 license.
You'll need a lot of VRAM to run them at their full capacity:
VRAM Requirement for processing 1 million-token sequences:
- Qwen2.5-7B-Instruct-1M: At least 120GB VRAM (total across GPUs).
- Qwen2.5-14B-Instruct-1M: At least 320GB VRAM (total across GPUs).
If your GPUs do not have sufficient VRAM, you can still use Qwen2.5-1M models for shorter tasks.
Qwen recommend using their custom fork of vLLM to serve the models:
You can also use the previous framework that supports Qwen2.5 for inference, but accuracy degradation may occur for sequences exceeding 262,144 tokens.
GGUF quantized versions of the models are already starting to show up. LM Studio's "official model curator" Bartowski published lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF and lmstudio-community/Qwen2.5-14B-Instruct-1M-GGUF - sizes range from 4.09GB to 8.1GB for the 7B model and 7.92GB to 15.7GB for the 14B.
These might not work well yet with the full context lengths as the underlying llama.cpp library may need some changes.
I tried running the 8.1GB 7B model using Ollama on my Mac like this:
ollama run hf.co/lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF:Q8_0
Then with LLM:
llm install llm-ollama
llm models -q qwen # To search for the model ID
# I set a shorter q1m alias:
llm aliases set q1m hf.co/lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF:Q8_0
I tried piping a large prompt in using files-to-prompt like this:
files-to-prompt ~/Dropbox/Development/llm -e py -c | llm -m q1m 'describe this codebase in detail'
That should give me every Python file in my llm project. Piping that through ttok first told me this was 63,014 OpenAI tokens, I expect that count is similar for Qwen.
The result was disappointing: it appeared to describe just the last Python file that stream. Then I noticed the token usage report:
2,048 input, 999 output
This suggests to me that something's not working right here - maybe the Ollama hosting framework is truncating the input, or maybe there's a problem with the GGUF I'm using?
I'll update this post when I figure out how to run longer prompts through the new Qwen model using GGUF weights on a Mac.
Update: It turns out Ollama has a num_ctx option which defaults to 2048, affecting the input context length. I tried this:
files-to-prompt \
~/Dropbox/Development/llm \
-e py -c | \
llm -m q1m 'describe this codebase in detail' \
-o num_ctx 80000
But I quickly ran out of RAM (I have 64GB but a lot of that was in use already) and hit Ctrl+C to avoid crashing my computer. I need to experiment a bit to figure out how much RAM is used for what context size.
Awni Hannun shared tips for running mlx-community/Qwen2.5-7B-Instruct-1M-4bit using MLX, which should work for up to 250,000 tokens. They ran 120,000 tokens and reported:
- Peak RAM for prompt filling was 22GB
- Peak RAM for generation 12GB
- Prompt filling took 350 seconds on an M2 Ultra
- Generation ran at 31 tokens-per-second on M2 Ultra