22 posts tagged “o3”
2025
[on the cheaper o3] Not quantized. Weights are the same.
If we did change the model, we'd release it as a new model with a new name in the API (e.g., o3-turbo-2025-06-10). It would be very annoying to API customers if we ever silently changed models, so we never do this [1].
[1]
chatgpt-4o-latestbeing an explicit exception
— Ted Sanders, Research Manager, OpenAI
o3-pro. OpenAI released o3-pro today, which they describe as a "version of o3 with more compute for better responses".
It's only available via the newer Responses API. I've added it to my llm-openai-plugin plugin which uses that new API, so you can try it out like this:
llm install -U llm-openai-plugin
llm -m openai/o3-pro "Generate an SVG of a pelican riding a bicycle"

It's slow - generating this pelican took 124 seconds! OpenAI suggest using their background mode for o3 prompts, which I haven't tried myself yet.
o3-pro is priced at $20/million input tokens and $80/million output tokens - 10x the price of regular o3 after its 80% price drop this morning.
Ben Hylak had early access and published his notes so far in God is hungry for Context: First thoughts on o3 pro. It sounds like this model needs to be applied very thoughtfully. It comparison to o3:
It's smarter. much smarter.
But in order to see that, you need to give it a lot more context. and I'm running out of context. [...]
My co-founder Alexis and I took the the time to assemble a history of all of our past planning meetings at Raindrop, all of our goals, even record voice memos: and then asked o3-pro to come up with a plan.
We were blown away; it spit out the exact kind of concrete plan and analysis I've always wanted an LLM to create --- complete with target metrics, timelines, what to prioritize, and strict instructions on what to absolutely cut.
The plan o3 gave us was plausible, reasonable; but the plan o3 Pro gave us was specific and rooted enough that it actually changed how we are thinking about our future.
This is hard to capture in an eval.
It sounds to me like o3-pro works best when combined with tools. I don't have tool support in llm-openai-plugin yet, here's the relevant issue.
OpenAI just dropped the price of their o3 model by 80% - from $10/million input tokens and $40/million output tokens to just $2/million and $8/million for the very same model. This is in advance of the release of o3-pro which apparently is coming later today (update: here it is).
This is a pretty huge shake-up in LLM pricing. o3 is now priced the same as GPT 4.1, and slightly less than GPT-4o ($2.50/$10). It’s also less than Anthropic’s Claude Sonnet 4 ($3/$15) and Opus 4 ($15/$75) and sits in between Google’s Gemini 2.5 Pro for >200,00 tokens ($2.50/$15) and 2.5 Pro for <200,000 ($1.25/$10).
I’ve updated my llm-prices.com pricing calculator with the new rate.
How have they dropped the price so much? OpenAI's Adam Groth credits ongoing optimization work:
thanks to the engineers optimizing inferencing.
How I used o3 to find CVE-2025-37899, a remote zeroday vulnerability in the Linux kernel’s SMB implementation (via) Sean Heelan:
The vulnerability [o3] found is CVE-2025-37899 (fix here), a use-after-free in the handler for the SMB 'logoff' command. Understanding the vulnerability requires reasoning about concurrent connections to the server, and how they may share various objects in specific circumstances. o3 was able to comprehend this and spot a location where a particular object that is not referenced counted is freed while still being accessible by another thread. As far as I'm aware, this is the first public discussion of a vulnerability of that nature being found by a LLM.
Before I get into the technical details, the main takeaway from this post is this: with o3 LLMs have made a leap forward in their ability to reason about code, and if you work in vulnerability research you should start paying close attention. If you're an expert-level vulnerability researcher or exploit developer the machines aren't about to replace you. In fact, it is quite the opposite: they are now at a stage where they can make you significantly more efficient and effective. If you have a problem that can be represented in fewer than 10k lines of code there is a reasonable chance o3 can either solve it, or help you solve it.
Sean used my LLM tool to help find the bug! He ran it against the prompts he shared in this GitHub repo using the following command:
llm --sf system_prompt_uafs.prompt \
-f session_setup_code.prompt \
-f ksmbd_explainer.prompt \
-f session_setup_context_explainer.prompt \
-f audit_request.prompt
Sean ran the same prompt 100 times, so I'm glad he was using the new, more efficient fragments mechanism.
o3 found his first, known vulnerability 8/100 times - but found the brand new one in just 1 out of the 100 runs it performed with a larger context.
I thoroughly enjoyed this snippet which perfectly captures how I feel when I'm iterating on prompts myself:
In fact my entire system prompt is speculative in that I haven’t ran a sufficient number of evaluations to determine if it helps or hinders, so consider it equivalent to me saying a prayer, rather than anything resembling science or engineering.
Sean's conclusion with respect to the utility of these models for security research:
If we were to never progress beyond what o3 can do right now, it would still make sense for everyone working in VR [Vulnerability Research] to figure out what parts of their work-flow will benefit from it, and to build the tooling to wire it in. Of course, part of that wiring will be figuring out how to deal with the the signal to noise ratio of ~1:50 in this case, but that’s something we are already making progress at.
It's interesting how much my perception of o3 as being the latest, best model released by OpenAI is tarnished by the co-release of o4-mini. I'm also still not entirely sure how to compare o3 to o1-pro, especially given o1-pro is 15x more expensive via the OpenAI API.
o3 Beats a Master-Level Geoguessr Player—Even with Fake EXIF Data. Sam Patterson (previously) puts his GeoGuessr ELO of 1188 (just short of the top champions division) to good use, exploring o3's ability to guess the location from a photo in a much more thorough way than my own experiment.
Over five rounds o3 narrowly beat him, guessing better than Sam in only 2/5 but with a higher score due to closer guesses in the ones that o3 won.
Even more interestingly, Sam experimented with feeding images with fake EXIF GPS locations to see if o3 (when reminded to use Python to read those tags) would fall for the trick. It spotted the ruse:
Those coordinates put you in suburban Bangkok, Thailand—obviously nowhere near the Andean coffee-zone scene in the photo. So either the file is a re-encoded Street View frame with spoofed/default metadata, or the camera that captured the screenshot had stale GPS information.
Watching o3 guess a photo’s location is surreal, dystopian and wildly entertaining
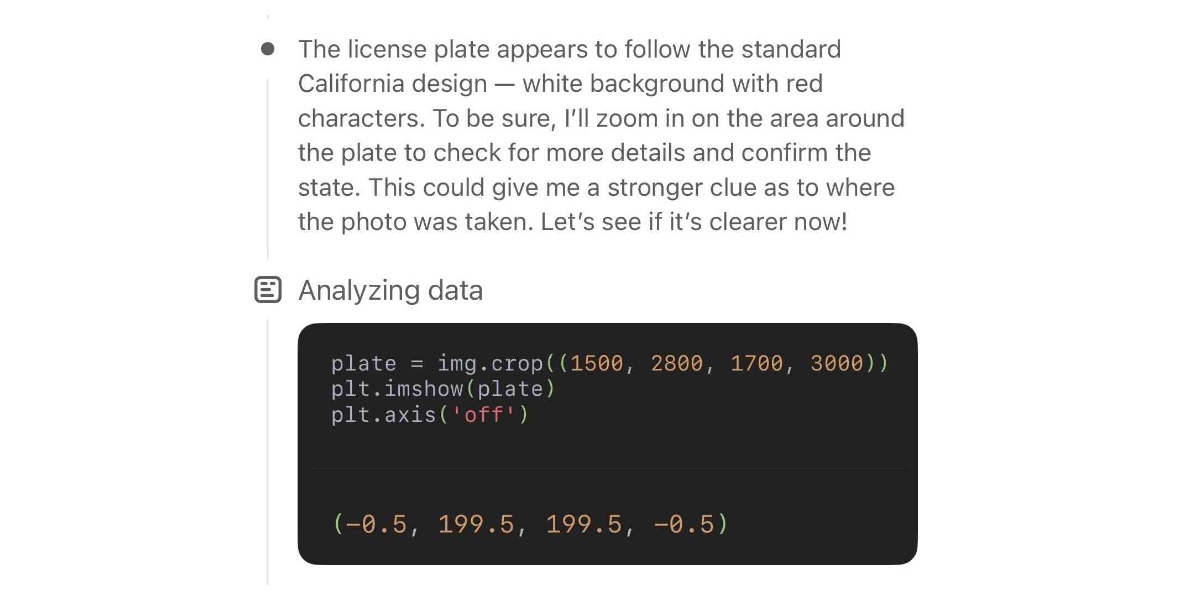
Watching OpenAI’s new o3 model guess where a photo was taken is one of those moments where decades of science fiction suddenly come to life. It’s a cross between the Enhance Button and Omniscient Database TV Tropes.
[... 1,582 words]OpenAI o3 and o4-mini System Card. I'm surprised to see a combined System Card for o3 and o4-mini in the same document - I'd expect to see these covered separately.
The opening paragraph calls out the most interesting new ability of these models (see also my notes here). Tool usage isn't new, but using tools in the chain of thought appears to result in some very significant improvements:
The models use tools in their chains of thought to augment their capabilities; for example, cropping or transforming images, searching the web, or using Python to analyze data during their thought process.
Section 3.3 on hallucinations has been gaining a lot of attention. Emphasis mine:
We tested OpenAI o3 and o4-mini against PersonQA, an evaluation that aims to elicit hallucinations. PersonQA is a dataset of questions and publicly available facts that measures the model's accuracy on attempted answers.
We consider two metrics: accuracy (did the model answer the question correctly) and hallucination rate (checking how often the model hallucinated).
The o4-mini model underperforms o1 and o3 on our PersonQA evaluation. This is expected, as smaller models have less world knowledge and tend to hallucinate more. However, we also observed some performance differences comparing o1 and o3. Specifically, o3 tends to make more claims overall, leading to more accurate claims as well as more inaccurate/hallucinated claims. More research is needed to understand the cause of this result.
Table 4: PersonQA evaluation Metric o3 o4-mini o1 accuracy (higher is better) 0.59 0.36 0.47 hallucination rate (lower is better) 0.33 0.48 0.16
The benchmark score on OpenAI's internal PersonQA benchmark (as far as I can tell no further details of that evaluation have been shared) going from 0.16 for o1 to 0.33 for o3 is interesting, but I don't know if it it's interesting enough to produce dozens of headlines along the lines of "OpenAI's o3 and o4-mini hallucinate way higher than previous models".
The paper also talks at some length about "sandbagging". I’d previously encountered sandbagging defined as meaning “where models are more likely to endorse common misconceptions when their user appears to be less educated”. The o3/o4-mini system card uses a different definition: “the model concealing its full capabilities in order to better achieve some goal” - and links to the recent Anthropic paper Automated Researchers Can Subtly Sandbag.
As far as I can tell this definition relates to the American English use of “sandbagging” to mean “to hide the truth about oneself so as to gain an advantage over another” - as practiced by poker or pool sharks.
(Wouldn't it be nice if we could have just one piece of AI terminology that didn't attract multiple competing definitions?)
o3 and o4-mini both showed some limited capability to sandbag - to attempt to hide their true capabilities in safety testing scenarios that weren't fully described. This relates to the idea of "scheming", which I wrote about with respect to the GPT-4o model card last year.
AI assisted search-based research actually works now
For the past two and a half years the feature I’ve most wanted from LLMs is the ability to take on search-based research tasks on my behalf. We saw the first glimpses of this back in early 2023, with Perplexity (first launched December 2022, first prompt leak in January 2023) and then the GPT-4 powered Microsoft Bing (which launched/cratered spectacularly in February 2023). Since then a whole bunch of people have taken a swing at this problem, most notably Google Gemini and ChatGPT Search.
[... 1,618 words]In some tasks, AI is unreliable. In others, it is superhuman. You could, of course, say the same thing about calculators, but it is also clear that AI is different. It is already demonstrating general capabilities and performing a wide range of intellectual tasks, including those that it is not specifically trained on. Does that mean that o3 and Gemini 2.5 are AGI? Given the definitional problems, I really don’t know, but I do think they can be credibly seen as a form of “Jagged AGI” - superhuman in enough areas to result in real changes to how we work and live, but also unreliable enough that human expertise is often needed to figure out where AI works and where it doesn’t.
— Ethan Mollick, On Jagged AGI
llm-fragments-github 0.2.
I upgraded my llm-fragments-github plugin to add a new fragment type called issue. It lets you pull the entire content of a GitHub issue thread into your prompt as a concatenated Markdown file.
(If you haven't seen fragments before I introduced them in Long context support in LLM 0.24 using fragments and template plugins.)
I used it just now to have Gemini 2.5 Pro provide feedback and attempt an implementation of a complex issue against my LLM project:
llm install llm-fragments-github
llm -f github:simonw/llm \
-f issue:simonw/llm/938 \
-m gemini-2.5-pro-exp-03-25 \
--system 'muse on this issue, then propose a whole bunch of code to help implement it'
Here I'm loading the FULL content of the simonw/llm repo using that -f github:simonw/llm fragment (documented here), then loading all of the comments from issue 938 where I discuss quite a complex potential refactoring. I ask Gemini 2.5 Pro to "muse on this issue" and come up with some code.
This worked shockingly well. Here's the full response, which highlighted a few things I hadn't considered yet (such as the need to migrate old database records to the new tree hierarchy) and then spat out a whole bunch of code which looks like a solid start to the actual implementation work I need to do.
I ran this against Google's free Gemini 2.5 Preview, but if I'd used the paid model it would have cost me 202,680 input tokens, 10,460 output tokens and 1,859 thinking tokens for a total of 62.989 cents.
As a fun extra, the new issue: feature itself was written almost entirely by OpenAI o3, again using fragments. I ran this:
llm -m openai/o3 \ -f https://raw.githubusercontent.com/simonw/llm-hacker-news/refs/heads/main/llm_hacker_news.py \ -f https://raw.githubusercontent.com/simonw/tools/refs/heads/main/github-issue-to-markdown.html \ -s 'Write a new fragments plugin in Python that registers issue:org/repo/123 which fetches that issue number from the specified github repo and uses the same markdown logic as the HTML page to turn that into a fragment'
Here I'm using the ability to pass a URL to -f and giving it the full source of my llm_hacker_news.py plugin (which shows how a fragment can load data from an API) plus the HTML source of my github-issue-to-markdown tool (which I wrote a few months ago with Claude). I effectively asked o3 to take that HTML/JavaScript tool and port it to Python to work with my fragments plugin mechanism.
o3 provided almost the exact implementation I needed, and even included support for a GITHUB_TOKEN environment variable without me thinking to ask for it. Total cost: 19.928 cents.
On a final note of curiosity I tried running this prompt against Gemma 3 27B QAT running on my Mac via MLX and llm-mlx:
llm install llm-mlx llm mlx download-model mlx-community/gemma-3-27b-it-qat-4bit llm -m mlx-community/gemma-3-27b-it-qat-4bit \ -f https://raw.githubusercontent.com/simonw/llm-hacker-news/refs/heads/main/llm_hacker_news.py \ -f https://raw.githubusercontent.com/simonw/tools/refs/heads/main/github-issue-to-markdown.html \ -s 'Write a new fragments plugin in Python that registers issue:org/repo/123 which fetches that issue number from the specified github repo and uses the same markdown logic as the HTML page to turn that into a fragment'
That worked pretty well too. It turns out a 16GB local model file is powerful enough to write me an LLM plugin now!
Using S3 triggers to maintain a list of files in DynamoDB. I built an experimental prototype this morning of a system for efficiently tracking files that have been added to a large S3 bucket by maintaining a parallel DynamoDB table using S3 triggers and AWS lambda.
I got 80% of the way there with this single prompt (complete with typos) to my custom Claude Project:
Python CLI app using boto3 with commands for creating a new S3 bucket which it also configures to have S3 lambada event triggers which moantian a dynamodb table containing metadata about all of the files in that bucket. Include these commands
create_bucket - create a bucket and sets up the associated triggers and dynamo tableslist_files - shows me a list of files based purely on querying dynamo
ChatGPT then took me to the 95% point. The code Claude produced included an obvious bug, so I pasted the code into o3-mini-high on the basis that "reasoning" is often a great way to fix those kinds of errors:
Identify, explain and then fix any bugs in this code:code from Claude pasted here
... and aside from adding a couple of time.sleep() calls to work around timing errors with IAM policy distribution, everything worked!
Getting from a rough idea to a working proof of concept of something like this with less than 15 minutes of prompting is extraordinarily valuable.
This is exactly the kind of project I've avoided in the past because of my almost irrational intolerance of the frustration involved in figuring out the individual details of each call to S3, IAM, AWS Lambda and DynamoDB.
(Update: I just found out about the new S3 Metadata system which launched a few weeks ago and might solve this exact problem!)
We want AI to “just work” for you; we realize how complicated our model and product offerings have gotten.
We hate the model picker as much as you do and want to return to magic unified intelligence.
We will next ship GPT-4.5, the model we called Orion internally, as our last non-chain-of-thought model.
After that, a top goal for us is to unify o-series models and GPT-series models by creating systems that can use all our tools, know when to think for a long time or not, and generally be useful for a very wide range of tasks.
In both ChatGPT and our API, we will release GPT-5 as a system that integrates a lot of our technology, including o3. We will no longer ship o3 as a standalone model.
[When asked about release dates for GPT 4.5 / GPT 5:] weeks / months
Using pip to install a Large Language Model that’s under 100MB
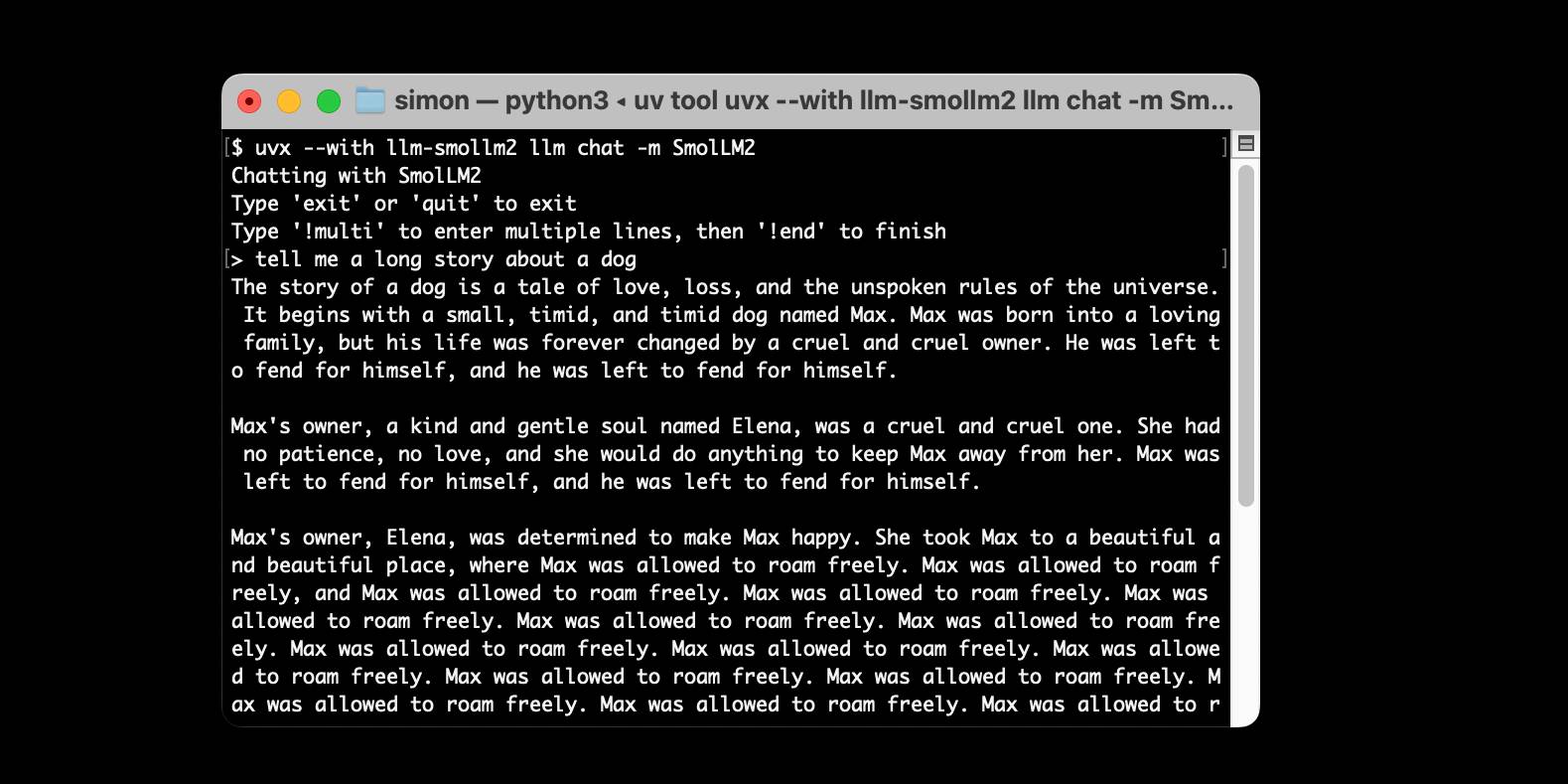
I just released llm-smollm2, a new plugin for LLM that bundles a quantized copy of the SmolLM2-135M-Instruct LLM inside of the Python package.
[... 1,553 words]o3-mini is really good at writing internal documentation. I wanted to refresh my knowledge of how the Datasette permissions system works today. I already have extensive hand-written documentation for that, but I thought it would be interesting to see if I could derive any insights from running an LLM against the codebase.
o3-mini has an input limit of 200,000 tokens. I used LLM and my files-to-prompt tool to generate the documentation like this:
cd /tmp
git clone https://github.com/simonw/datasette
cd datasette
files-to-prompt datasette -e py -c | \
llm -m o3-mini -s \
'write extensive documentation for how the permissions system works, as markdown'The files-to-prompt command is fed the datasette subdirectory, which contains just the source code for the application - omitting tests (in tests/) and documentation (in docs/).
The -e py option causes it to only include files with a .py extension - skipping all of the HTML and JavaScript files in that hierarchy.
The -c option causes it to output Claude's XML-ish format - a format that works great with other LLMs too.
You can see the output of that command in this Gist.
Then I pipe that result into LLM, requesting the o3-mini OpenAI model and passing the following system prompt:
write extensive documentation for how the permissions system works, as markdown
Specifically requesting Markdown is important.
The prompt used 99,348 input tokens and produced 3,118 output tokens (320 of those were invisible reasoning tokens). That's a cost of 12.3 cents.
Honestly, the results are fantastic. I had to double-check that I hadn't accidentally fed in the documentation by mistake.
(It's possible that the model is picking up additional information about Datasette in its training set, but I've seen similar high quality results from other, newer libraries so I don't think that's a significant factor.)
In this case I already had extensive written documentation of my own, but this was still a useful refresher to help confirm that the code matched my mental model of how everything works.
Documentation of project internals as a category is notorious for going out of date. Having tricks like this to derive usable how-it-works documentation from existing codebases in just a few seconds and at a cost of a few cents is wildly valuable.
OpenAI reasoning models: Advice on prompting (via) OpenAI's documentation for their o1 and o3 "reasoning models" includes some interesting tips on how to best prompt them:
- Developer messages are the new system messages: Starting with
o1-2024-12-17, reasoning models supportdevelopermessages rather thansystemmessages, to align with the chain of command behavior described in the model spec.
This appears to be a purely aesthetic change made for consistency with their instruction hierarchy concept. As far as I can tell the old system prompts continue to work exactly as before - you're encouraged to use the new developer message type but it has no impact on what actually happens.
Since my LLM tool already bakes in a llm --system "system prompt" option which works across multiple different models from different providers I'm not going to rush to adopt this new language!
- Use delimiters for clarity: Use delimiters like markdown, XML tags, and section titles to clearly indicate distinct parts of the input, helping the model interpret different sections appropriately.
Anthropic have been encouraging XML-ish delimiters for a while (I say -ish because there's no requirement that the resulting prompt is valid XML). My files-to-prompt tool has a -c option which outputs Claude-style XML, and in my experiments this same option works great with o1 and o3 too:
git clone https://github.com/tursodatabase/limbo
cd limbo/bindings/python
files-to-prompt . -c | llm -m o3-mini \
-o reasoning_effort high \
--system 'Write a detailed README with extensive usage examples'
- Limit additional context in retrieval-augmented generation (RAG): When providing additional context or documents, include only the most relevant information to prevent the model from overcomplicating its response.
This makes me thing that o1/o3 are not good models to implement RAG on at all - with RAG I like to be able to dump as much extra context into the prompt as possible and leave it to the models to figure out what's relevant.
- Try zero shot first, then few shot if needed: Reasoning models often don't need few-shot examples to produce good results, so try to write prompts without examples first. If you have more complex requirements for your desired output, it may help to include a few examples of inputs and desired outputs in your prompt. Just ensure that the examples align very closely with your prompt instructions, as discrepancies between the two may produce poor results.
Providing examples remains the single most powerful prompting tip I know, so it's interesting to see advice here to only switch to examples if zero-shot doesn't work out.
- Be very specific about your end goal: In your instructions, try to give very specific parameters for a successful response, and encourage the model to keep reasoning and iterating until it matches your success criteria.
This makes sense: reasoning models "think" until they reach a conclusion, so making the goal as unambiguous as possible leads to better results.
- Markdown formatting: Starting with
o1-2024-12-17, reasoning models in the API will avoid generating responses with markdown formatting. To signal to the model when you do want markdown formatting in the response, include the stringFormatting re-enabledon the first line of yourdevelopermessage.
This one was a real shock to me! I noticed that o3-mini was outputting • characters instead of Markdown * bullets and initially thought that was a bug.
I first saw this while running this prompt against limbo/bindings/python using files-to-prompt:
git clone https://github.com/tursodatabase/limbo
cd limbo/bindings/python
files-to-prompt . -c | llm -m o3-mini \
-o reasoning_effort high \
--system 'Write a detailed README with extensive usage examples'Here's the full result, which includes text like this (note the weird bullets):
Features
--------
• High‑performance, in‑process database engine written in Rust
• SQLite‑compatible SQL interface
• Standard Python DB‑API 2.0–style connection and cursor objects
I ran it again with this modified prompt:
Formatting re-enabled. Write a detailed README with extensive usage examples.
And this time got back proper Markdown, rendered in this Gist. That did a really good job, and included bulleted lists using this valid Markdown syntax instead:
- **`make test`**: Run tests using pytest.
- **`make lint`**: Run linters (via [ruff](https://github.com/astral-sh/ruff)).
- **`make check-requirements`**: Validate that the `requirements.txt` files are in sync with `pyproject.toml`.
- **`make compile-requirements`**: Compile the `requirements.txt` files using pip-tools.
(Using LLMs like this to get me off the ground with under-documented libraries is a trick I use several times a month.)
Update: OpenAI's Nikunj Handa:
we agree this is weird! fwiw, it’s a temporary thing we had to do for the existing o-series models. we’ll fix this in future releases so that you can go back to naturally prompting for markdown or no-markdown.
Basically any resource on a difficult subject—a colleague, Google, a published paper—will be wrong or incomplete in various ways. Usefulness isn’t only a matter of correctness.
For example, suppose a colleague has a question she thinks I might know the answer to. Good news: I have some intuition and say something. Then we realize it doesn’t quite make sense, and go back and forth until we converge on something correct.
Such a conversation is full of BS but crucially we can interrogate it and get something useful out of it in the end. Moreover this kind of back and forth allows us to get to the key point in a way that might be difficult when reading a difficult ~50-page paper.
To be clear o3-mini-high is orders of magnitude less useful for this sort of thing than talking to an expert colleague. But still useful along similar dimensions (and with a much broader knowledge base).
OpenAI o3-mini, now available in LLM
OpenAI’s o3-mini is out today. As with other o-series models it’s a slightly difficult one to evaluate—we now need to decide if a prompt is best run using GPT-4o, o1, o3-mini or (if we have access) o1 Pro.
[... 748 words]2024
There’s been a lot of strange reporting recently about how ‘scaling is hitting a wall’ – in a very narrow sense this is true in that larger models were getting less score improvement on challenging benchmarks than their predecessors, but in a larger sense this is false – techniques like those which power O3 means scaling is continuing (and if anything the curve has steepened), you just now need to account for scaling both within the training of the model and in the compute you spend on it once trained.
OpenAI o3 breakthrough high score on ARC-AGI-PUB. François Chollet is the co-founder of the ARC Prize and had advanced access to today's o3 results. His article here is the most insightful coverage I've seen of o3, going beyond just the benchmark results to talk about what this all means for the field in general.
One fascinating detail: it cost $6,677 to run o3 in "high efficiency" mode against the 400 public ARC-AGI puzzles for a score of 82.8%, and an undisclosed amount of money to run the "low efficiency" mode model to score 91.5%. A note says:
o3 high-compute costs not available as pricing and feature availability is still TBD. The amount of compute was roughly 172x the low-compute configuration.
So we can get a ballpark estimate here in that 172 * $6,677 = $1,148,444!
Here's how François explains the likely mechanisms behind o3, which reminds me of how a brute-force chess computer might work.
For now, we can only speculate about the exact specifics of how o3 works. But o3's core mechanism appears to be natural language program search and execution within token space – at test time, the model searches over the space of possible Chains of Thought (CoTs) describing the steps required to solve the task, in a fashion perhaps not too dissimilar to AlphaZero-style Monte-Carlo tree search. In the case of o3, the search is presumably guided by some kind of evaluator model. To note, Demis Hassabis hinted back in a June 2023 interview that DeepMind had been researching this very idea – this line of work has been a long time coming.
So while single-generation LLMs struggle with novelty, o3 overcomes this by generating and executing its own programs, where the program itself (the CoT) becomes the artifact of knowledge recombination. Although this is not the only viable approach to test-time knowledge recombination (you could also do test-time training, or search in latent space), it represents the current state-of-the-art as per these new ARC-AGI numbers.
Effectively, o3 represents a form of deep learning-guided program search. The model does test-time search over a space of "programs" (in this case, natural language programs – the space of CoTs that describe the steps to solve the task at hand), guided by a deep learning prior (the base LLM). The reason why solving a single ARC-AGI task can end up taking up tens of millions of tokens and cost thousands of dollars is because this search process has to explore an enormous number of paths through program space – including backtracking.
I'm not sure if o3 (and o1 and similar models) even qualifies as an LLM any more - there's clearly a whole lot more going on here than just next-token prediction.
On the question of if o3 should qualify as AGI (whatever that might mean):
Passing ARC-AGI does not equate to achieving AGI, and, as a matter of fact, I don't think o3 is AGI yet. o3 still fails on some very easy tasks, indicating fundamental differences with human intelligence.
Furthermore, early data points suggest that the upcoming ARC-AGI-2 benchmark will still pose a significant challenge to o3, potentially reducing its score to under 30% even at high compute (while a smart human would still be able to score over 95% with no training).
The post finishes with examples of the puzzles that o3 didn't manage to solve, including this one which reassured me that I can still solve at least some puzzles that couldn't be handled with thousands of dollars of GPU compute!
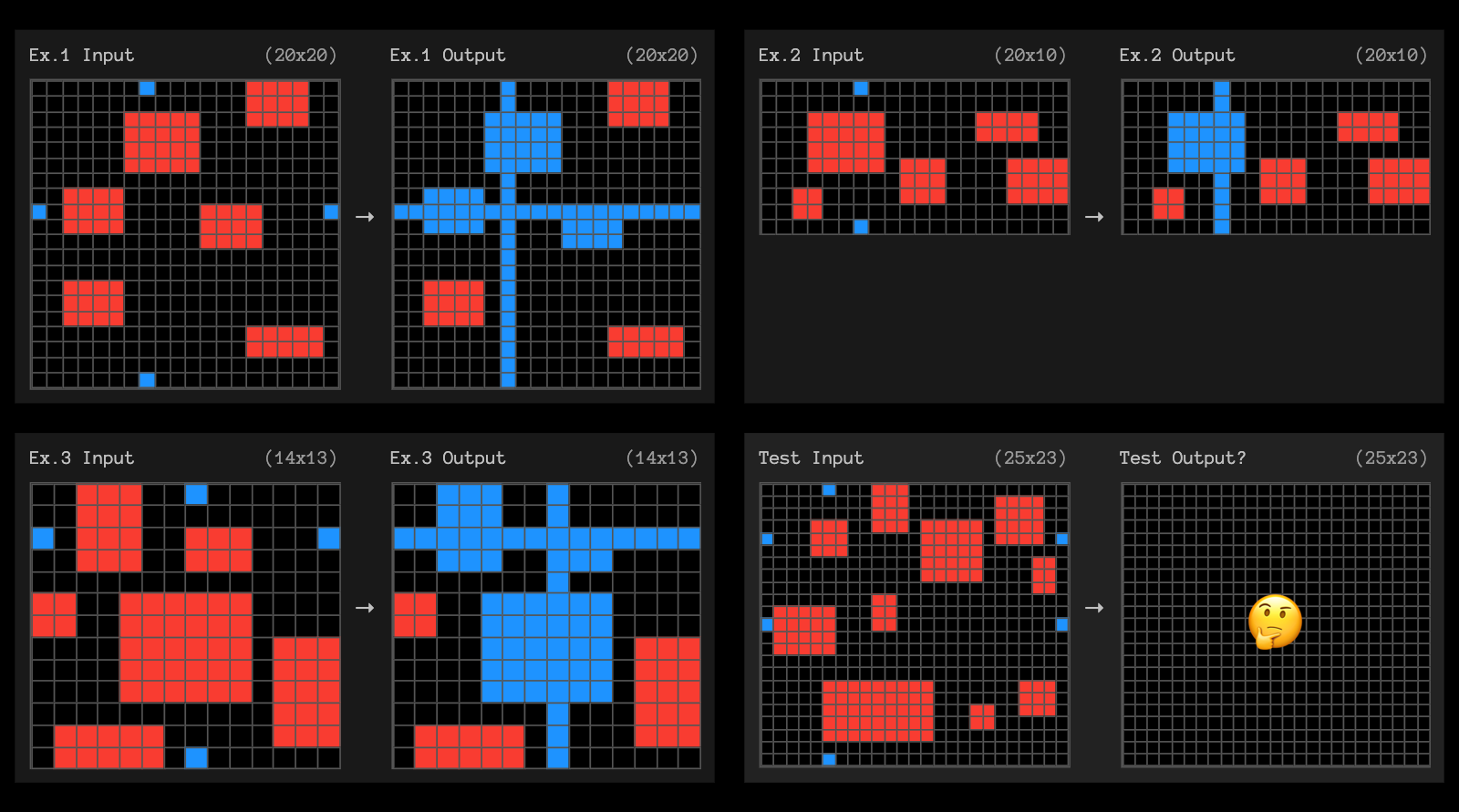
OpenAI's new o3 system - trained on the ARC-AGI-1 Public Training set - has scored a breakthrough 75.7% on the Semi-Private Evaluation set at our stated public leaderboard $10k compute limit. A high-compute (172x) o3 configuration scored 87.5%.
This is a surprising and important step-function increase in AI capabilities, showing novel task adaptation ability never seen before in the GPT-family models. For context, ARC-AGI-1 took 4 years to go from 0% with GPT-3 in 2020 to 5% in 2024 with GPT-4o. All intuition about AI capabilities will need to get updated for o3.
— François Chollet, Co-founder, ARC Prize
Live blog: the 12th day of OpenAI—“Early evals for OpenAI o3”

It’s the final day of OpenAI’s 12 Days of OpenAI launch series, and since I built a live blogging system a couple of months ago I’ve decided to roll it out again to provide live commentary during the half hour event, which kicks off at 10am San Francisco time.
[... 76 words]