434 posts tagged “openai”
2026
The first known runaway AI agent—or a very bad marketing stunt? (via) Martin Alderson's commentary on the OpenAI accidental cyberattack against Hugging Face includes a couple of details I hadn't considered.
First, Hugging Face offers a truly rich target if you're trying to find potential vulnerabilities that require executing arbitrary code:
Hugging Face has an enormous attack surface. They have more interfaces than I can count which run untrusted models and code. While they definitely have invested in defences, by nature of their operating model they do have many more opportunities to be attacked than many other services. I certainly don't envy their cybersecurity teams.
Secondly, one of the things that has puzzled me is how OpenAI didn't notice that their sandbox had been so thoroughly breached by the agent. Surely they'd be monitoring network traffic closely?
Martin points out that:
It's also likely they were running a huge amount of benchmarks simultaneously with ~unlimited token budgets - you want as many samples as possible to figure out how good a model is at a certain benchmark. It may also be they are testing various different checkpoints of the model too, understanding how the model is improving as it goes through the various training stages.
The mistakes made by the OpenAI team running this benchmark are easier to imagine when you think about the scale at which benchmarks of this kind usually operate. For all we know they could have been subjecting a new model to dozens of benchmarks at the same time, in dozens of different environments.
I genuinely believe that if you took an open weights model from 2025 and built a pentest harness for it, it could do this kind of sandbox escape and scan/hack in most networks. This is only surprising because you assume OpenAI has sounder sandboxes.
— Thomas Ptacek, doesn't think this even needs a frontier model
OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened
This story is wild. The short version: OpenAI were running a cybersecurity test against an unreleased model, with the model’s guardrail features turned off. Rather than solve the test, the model broke its way out of OpenAI’s sandbox, then found exploits to break in to Hugging Face, all so it could cheat on the test by stealing the answers.
[... 1,960 words]We have been having extensive discussions around open source strategy. We will discuss it more at our next board meeting, but one thing we’d like to do soon is to create a language model with the approximate capability of GPT-3 that can run locally on consumer hardware and release that. We’d like to do it soon, before Stability or someone else does. In general, we think this helps discourage others from releasing similarly-powerful models, and makes it harder for new efforts to get funded.
— Sam Altman, Email to OpenAI's board, October 1, 2022 - exposed in Musk v. Altman (2026)
One of the consequences of GPT-5.6 Sol being clearly a Fable/Mythos class model is that Anthropic have, once again, bumped the date that Fable stops being available in their Claude Max plans:
We're extending Claude Fable 5 access on all paid plans, as well as keeping Claude Code’s weekly rate limits 50% higher, through July 19.
As before, you can use up to half of your weekly usage limit on Fable 5. After that, you can continue using Fable 5 with usage credits, or switch to another model to keep working within your remaining limits.
Anthropic's original rationale for this was compute constraints - they wanted a better idea of both demand and compute availability before committing to keeping the new model cheap for subscribers.
OpenAI appear confident that they won't need to restrict access to GPT-5.6 in the same way. Here's Thibault Sottiaux this morning:
The last 48 hours of Codex and ChatGPT Work have been intense! Three important updates:
- Temporarily removing the 5 hour usage limit restriction for all Plus, Business and Pro plans
- Rolling out changes that will make GPT 5.6 Sol more efficient across the board and that will be reflected in less usage being used so that it can take you further. Exact impact to be quantified and shared
- We hit 6M active users, and are landing a usage reset in the next hour
At this point I think Anthropic should change track and keep Fable permanently available on those plans. OpenAI are winning users simply due to the uncertainty that surrounds Fable access.
[...] Work on web and mobile runs in the cloud. Work in the desktop app can also use local files and desktop apps with your permission. At launch, cloud Work conversations do not appear in desktop Work; desktop Work threads and local files remain on that computer.
— OpenAI, trying (unsuccessfully) to clarify ChatGPT Work
The new GPT-5.6 family: Luna, Terra, Sol

OpenAI’s latest flagship model hit general availability this morning, and comes in three sizes: Luna, Terra, and Sol (from smallest to largest).
[... 661 words]Introducing GPT‑Live (via) OpenAI finally upgraded the model used by ChatGPT voice mode!
I've had preview access for a few weeks in the iPhone app, and the new model is very impressive. It also has the ability to spin off harder tasks to GPT-5.5:
For questions that require web search, deeper reasoning, or more complex work, it delegates to our latest frontier model behind the scenes and brings the result back into the conversation when it’s ready. While it works, GPT‑Live can keep talking with you and maintain the flow of conversation. At launch, GPT‑Live will use GPT‑5.5 in the background. As we release new frontier models, we’ll continuously update the model used by GPT‑Live.
The previous voice mode in the ChatGPT app was based on a GPT-4o era model, with a knowledge cut-off some time in 2024. I had mostly stopped using voice mode because the age and relative weakness of the model greatly limited how useful it was as a brainstorming partner.
During the preview period I encountered a pretty obscure bug: the model was interrupting me to laugh at things I said, which weren't even intended as jokes! It felt rude and condescending - I reported it to OpenAI and as far as I can tell they made some tweaks and it's now less likely to happen.
From looking back at my transcripts I think it was this bit that triggered the interrupting laugh:
so where are the owls when they're not, like before dusk? The owls exist, right? Are they hiding in holes? Where are they hiding?
My longest conversation with the new model has been a full hour while walking the dog (and taking photos of pelicans). I have not yet managed to take a photo of an owl.
Better Models: Worse Tools. Armin reports on a weird problem he ran into while hacking on Pi:
The short version is that newer Claude models sometimes call Pi’s edit tool with extra, invented fields in the nested
edits[]array. And not Haiku or some small model: Opus 4.8. The edit itself is usually correct but the arguments do not match the schema as the model invents made-up keys and Pi thus rejects the tool call and asks to try again.That alone is not too surprising as models emit malformed tool calls sometimes. Particularly small ones. What surprised me is that this is getting worse with newer Anthropic models as both Opus 4.8 and Sonnet 5 show it but none of the older models. In other words, the SOTA models of the family are worse at this specific tool schema than their older siblings.
Armin theorizes that this is because more recent Anthropic models have been specifically trained (presumably via Reinforcement Learning) to better use the edit tools that are baked into Claude Code. This has the unfortunate effect that other coding harnesses, such as Pi, may find that their own custom edit tools are more likely to be used incorrectly.
Claude's edit tool uses search and replace. OpenAI's Codex uses an apply_patch mechanism instead, and OpenAI have talked in the past about how their models are trained to use that tool effectively.
Does this mean third-party coding harnesses like Pi should implement multiple edit tools just so they can use the one with the best performance for the underlying model the user has selected?
This is a bad state of affairs. Consider, in particular, some industry dynamics:
- Frontier models are trained at an enormous cost, and a significant fraction of that cost is recouped in the few post-release months that they are broadly available. After that period elapses, the models become sub-frontier, competition emerges, and margins compress. Every week of delay is eating into the narrow window that labs have to make their accounting work.
- The ongoing AI infrastructure buildout—the one that is, according to former US AI Czar David Sacks, essential to the US economy, assumes a functionally global total addressable market for US AI services. No one is building $100 billion dollar data centers to serve frontier models to whatever 100 companies the US government will allow access. [...]
— Dean W. Ball, 35 thoughts on what has happened and what America should do
We're beginning a limited preview of the GPT‑5.6 series: Sol, our flagship model; Terra, a balanced model for everyday work; and Luna, a fast and affordable model. Terra has competitive performance to GPT‑5.5 while being 2x cheaper and Luna brings strong capability at our lowest cost. [...]
We believe in broad access, and we plan to make GPT‑5.6 Sol, Terra, and Luna generally available in the coming weeks. As part of our ongoing engagement with the U.S. government, we previewed our plans and the models’ capabilities ahead of today’s launch. At their request, we are starting with a limited preview for a small group of trusted partners whose participation has been shared with the government, before releasing more broadly. [...]
GPT‑5.6 is priced per 1M tokens across three model sizes: Sol is $5 input / $30 output; Terra is $2.50 input / $15 output; and Luna is $1 input / $6 output. GPT‑5.6 also introduces more predictable prompt caching, including support for explicit cache breakpoints and a 30-minute minimum cache life. For GPT‑5.6 and later models, cache writes are billed at 1.25x the model’s uncached input rate, while cache reads continue to receive the 90% cached-input discount.
— OpenAI, Previewing GPT‑5.6 Sol: a next-generation model
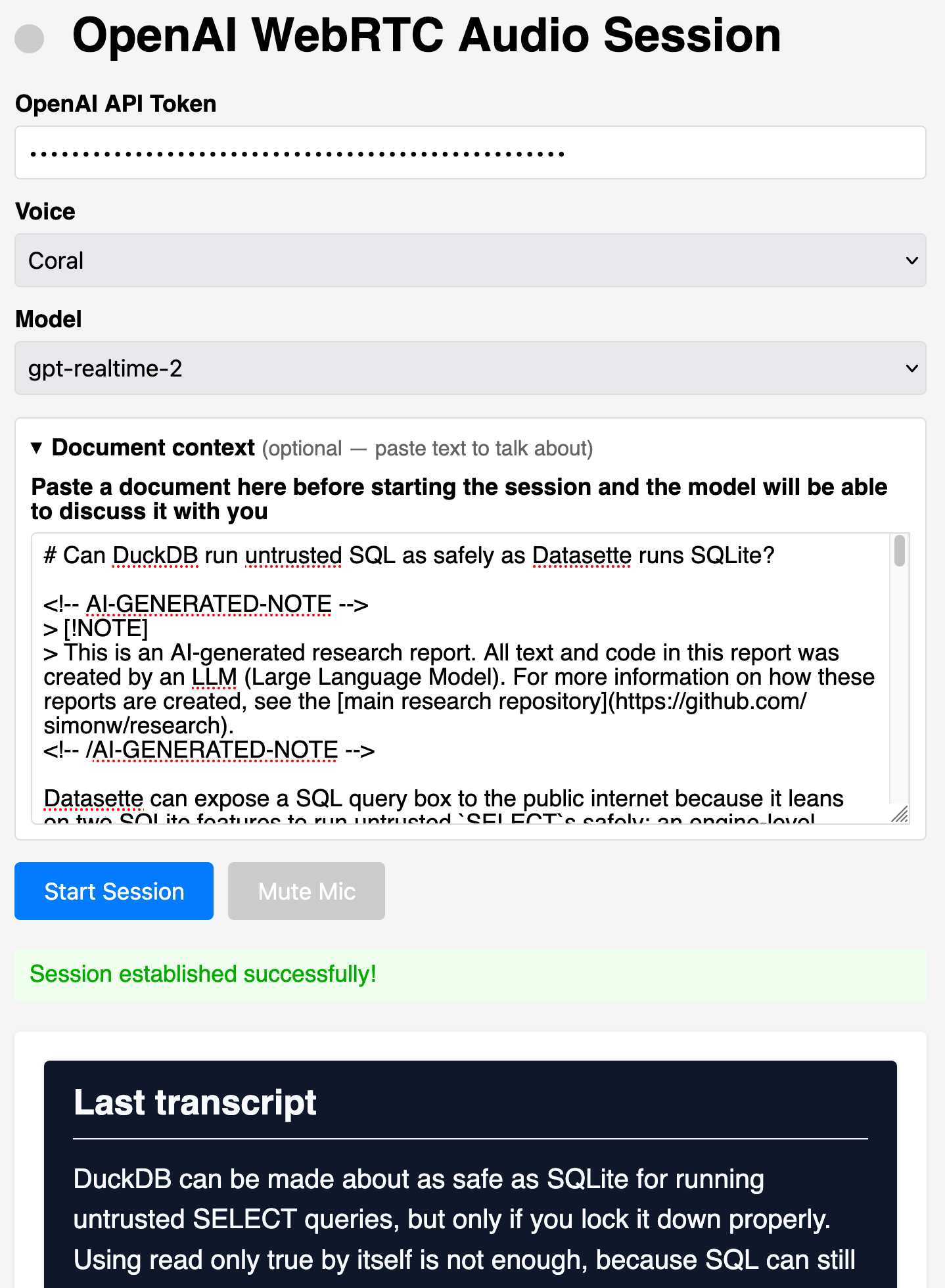
OpenAI WebRTC Audio Session, now with document context. I built the first version of this tool in December 2024 to try out the then-new OpenAI WebRTC API for interacting with their realtime audio models.
Last month OpenAI introduced a brand new model to that API called GPT‑Realtime‑2, which they promoted as "our first voice model with GPT‑5‑class reasoning" - with a Sep 30, 2024 knowledge cut-off.
I've been waiting for that model to show up in the ChatGPT iPhone app but it still hasn't, so I revisited my old playground.
You can now pick the better model, and you can also paste in a big chunk of document context so you can have as audio conversation in your browser about whatever information you think would be useful to explore in a conversational way.
OpenAI Help: Lockdown Mode. OpenAI first teased this in February, but now it's live and "rolling out to eligible personal accounts, including Free, Go, Plus, and Pro, and self-serve ChatGPT Business accounts":
Lockdown Mode is designed to help prevent the final stage of data exfiltration from a prompt injection attack by limiting outbound network requests that could transfer sensitive data to an attacker. Lockdown Mode does not prevent prompt injections from appearing in the content ChatGPT processes. For example, a prompt injection could appear in cached web content or in an uploaded file, and could still affect the behavior or accuracy of a response.
This looks really good to me.
The Lethal Trifecta occurs when an LLM system has access to all three of access to private data, exposure to untrusted content and a way to steal data and transmit it back to the attacker.
The only way to solve the trifecta is to cut off one of the three legs, and by far the easiest leg to restrict without making your LLM systems far less useful is the exfiltration vectors to steal data.
It looks to me like lockdown mode directly attacks that leg, using mechanisms that are deterministic and, crucially, are not evaluated by AI systems that themselves can be subverted by sufficiently devious attacks.
The existence of lockdown mode does however imply that ChatGPT, in its default settings, does not provide robust protection against sufficiently determined data exfiltration attacks!
Update: This tweet OpenAI CISO Dane Stuckey:
Lockdown mode is not meant for everyone. However, for folks who have an elevated risk profile - due to who they are, what they work on, or the types of data they work with - it's an excellent tool for further securing themselves. This has some tradeoffs on functionality and utility, but for these users, the tradeoff is worthwhile.
I think Anthropic and OpenAI have found product-market fit
Anthropic are strongly rumored to be about to have their first profitable quarter. Stories are circulating of companies surprised at how expensive their LLM bills are becoming from usage by their staff. I think this is because OpenAI and Anthropic have both found product-market fit.
[... 1,931 words]A bunch of useful stuff in this LLM alpha, but the most important detail is this one:
Most reasoning-capable OpenAI models now use the
/v1/responsesendpoint instead of/v1/chat/completions. This enables interleaved reasoning across tool calls for GPT-5 class models. #1435
This means you can now see the summarized reasoning tokens when you run prompts against an OpenAI model, displayed in a different color to standard error. Use the -R or --hide-reasoning flags if you don't want to see that.
WebRTC is designed to degrade and drop my prompt during poor network conditions.
wtf my dude
WebRTC aggressively drops audio packets to keep latency low. If you’ve ever heard distorted audio on a conference call, that’s WebRTC baybee. The idea is that conference calls depend on rapid back-and-forth, so pausing to wait for audio is unacceptable.
…but as a user, I would much rather wait an extra 200ms for my slow/expensive prompt to be accurate. After all, I’m paying good money to boil the ocean, and a garbage prompt means a garbage response. It’s not like LLMs are particularly responsive anyway.
But I’m not allowed to wait. It’s impossible to even retransmit a WebRTC audio packet within a browser; we tried at Discord. The implementation is hard-coded for real-time latency or else.
— Luke Curley, OpenAI’s WebRTC Problem, in response to How OpenAI delivers low-latency voice AI at scale
So it’s well known that Y Combinator owns some stake in OpenAI. But how big is that stake? This seems like devilishly difficult information to obtain. I asked around and a little birdie who knows several OpenAI investors came back with an answer: Y Combinator owns about 0.6 percent of OpenAI. At OpenAI’s current $852 billion valuation, that’s worth over $5 billion.
— John Gruber, Y Combinator’s Stake in OpenAI
Codex CLI 0.128.0 adds /goal
(via)
The latest version of OpenAI's Codex CLI coding agent adds their own version of the Ralph loop: you can now set a /goal and Codex will keep on looping until it evaluates that the goal has been completed... or the configured token budget has been exhausted.
It looks like the feature is mainly implemented though the goals/continuation.md and goals/budget_limit.md prompts, which are automatically injected at the end of a turn.
Our evaluation of OpenAI’s GPT-5.5 cyber capabilities. The UK's AI Security Institute previously evaluated Claude Mythos: now they've evaluated GPT-5.5 for finding security vulnerability and found it to be comparable to Mythos, but unlike Mythos it's generally available right now.
Never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user's query.
— OpenAI Codex base_instructions, for GPT-5.5
Tracking the history of the now-deceased OpenAI Microsoft AGI clause
For many years, Microsoft and OpenAI’s relationship has included a weird clause saying that, should AGI be achieved, Microsoft’s commercial IP rights to OpenAI’s technology would be null and void. That clause appeared to end today. I decided to try and track its expression over time on openai.com.
[... 691 words]Since GPT-5.4, we’ve unified Codex and the main model into a single system, so there’s no separate coding line anymore.
GPT-5.5 takes this further, with strong gains in agentic coding, computer use, and any task on a computer.
— Romain Huet, confirming OpenAI won't release a GPT-5.5-Codex model
GPT-5.5 prompting guide. Now that GPT-5.5 is available in the API, OpenAI have released a wealth of useful tips on how best to prompt the new model.
Here's a neat trick they recommend for applications that might spend considerable time thinking before returning a user-visible response:
Before any tool calls for a multi-step task, send a short user-visible update that acknowledges the request and states the first step. Keep it to one or two sentences.
I've already noticed their Codex app doing this, and it does make longer running tasks feel less like the model has crashed.
OpenAI suggest running the following in Codex to upgrade your existing code using advice embedded in their openai-docs skill:
$openai-docs migrate this project to gpt-5.5
The upgrade guide the coding agent will follow is this one, which even includes light instructions on how to rewrite prompts to better fit the model.
Also relevant is the Using GPT-5.5 guide, which opens with this warning:
To get the most out of GPT-5.5, treat it as a new model family to tune for, not a drop-in replacement for
gpt-5.2orgpt-5.4. Begin migration with a fresh baseline instead of carrying over every instruction from an older prompt stack. Start with the smallest prompt that preserves the product contract, then tune reasoning effort, verbosity, tool descriptions, and output format against representative examples.
Interesting to see OpenAI recommend starting from scratch rather than trusting that existing prompts optimized for previous models will continue to work effectively with GPT-5.5.
- New GPT-5.5 OpenAI model:
llm -m gpt-5.5. #1418- New option to set the text verbosity level for GPT-5+ OpenAI models:
-o verbosity low. Values arelow,medium,high.- New option for setting the image detail level used for image attachments to OpenAI models:
-o image_detail low- values arelow,highandauto, and GPT-5.4 and 5.5 also acceptoriginal.- Models listed in
extra-openai-models.yamlare now also registered as asynchronous. #1395
A pelican for GPT-5.5 via the semi-official Codex backdoor API

GPT-5.5 is out. It’s available in OpenAI Codex and is rolling out to paid ChatGPT subscribers. I’ve had some preview access and found it to be a fast, effective and highly capable model. As is usually the case these days, it’s hard to put into words what’s good about it—I ask it to build things and it builds exactly what I ask for!
[... 884 words]Hijacks your Codex CLI credentials to make API calls with LLM, as described in my post about GPT-5.5.
Where’s the raccoon with the ham radio? (ChatGPT Images 2.0)

OpenAI released ChatGPT Images 2.0 today, their latest image generation model. On the livestream Sam Altman said that the leap from gpt-image-1 to gpt-image-2 was equivalent to jumping from GPT-3 to GPT-5. Here’s how I put it to the test.
[... 849 words]Trusted access for the next era of cyber defense (via) OpenAI's answer to Claude Mythos appears to be a new model called GPT-5.4-Cyber:
In preparation for increasingly more capable models from OpenAI over the next few months, we are fine-tuning our models specifically to enable defensive cybersecurity use cases, starting today with a variant of GPT‑5.4 trained to be cyber-permissive: GPT‑5.4‑Cyber.
They're also extending a program they launched in February (which I had missed) called Trusted Access for Cyber, where users can verify their identity (via a photo of a government-issued ID processed by Persona) to gain "reduced friction" access to OpenAI's models for cybersecurity work.
Honestly, this OpenAI announcement is difficult to follow. Unsurprisingly they don't mention Anthropic at all, but much of the piece emphasizes their many years of existing cybersecurity work and their goal to "democratize access" to these tools, hence the emphasis on that self-service verification flow from February.
If you want access to their best security tools you still need to go through an extra Google Form application process though, which doesn't feel particularly different to me from Anthropic's Project Glasswing.
I think it's non-obvious to many people that the OpenAI voice mode runs on a much older, much weaker model - it feels like the AI that you can talk to should be the smartest AI but it really isn't.
If you ask ChatGPT voice mode for its knowledge cutoff date it tells you April 2024 - it's a GPT-4o era model.
This thought inspired by this Andrej Karpathy tweet about the growing gap in understanding of AI capability based on the access points and domains people are using the models with:
[...] It really is simultaneously the case that OpenAI's free and I think slightly orphaned (?) "Advanced Voice Mode" will fumble the dumbest questions in your Instagram's reels and at the same time, OpenAI's highest-tier and paid Codex model will go off for 1 hour to coherently restructure an entire code base, or find and exploit vulnerabilities in computer systems.
This part really works and has made dramatic strides because 2 properties:
- these domains offer explicit reward functions that are verifiable meaning they are easily amenable to reinforcement learning training (e.g. unit tests passed yes or no, in contrast to writing, which is much harder to explicitly judge), but also
- they are a lot more valuable in b2b settings, meaning that the biggest fraction of the team is focused on improving them.