8 posts tagged “space-invaders”
Results for my simple LLM benchmark "Write an HTML and JavaScript page implementing space invaders" - try them at space-invaders.simonwillison.net
2025
mistralai/mistral-vibe. Here's the Apache 2.0 licensed source code for Mistral's new "Vibe" CLI coding agent, released today alongside Devstral 2.
It's a neat implementation of the now standard terminal coding agent pattern, built in Python on top of Pydantic and Rich/Textual (here are the dependencies.) Gemini CLI is TypeScript, Claude Code is closed source (TypeScript, now on top of Bun), OpenAI's Codex CLI is Rust. OpenHands is the other major Python coding agent I know of, but I'm likely missing some others. (UPDATE: Kimi CLI is another open source Apache 2 Python one.)
The Vibe source code is pleasant to read and the crucial prompts are neatly extracted out into Markdown files. Some key places to look:
- core/prompts/cli.md is the main system prompt ("You are operating as and within Mistral Vibe, a CLI coding-agent built by Mistral AI...")
- core/prompts/compact.md is the prompt used to generate compacted summaries of conversations ("Create a comprehensive summary of our entire conversation that will serve as complete context for continuing this work...")
- Each of the core tools has its own prompt file:
The Python implementations of those tools can be found here.
I tried it out and had it build me a Space Invaders game using three.js with the following prompt:
make me a space invaders game as HTML with three.js loaded from a CDN
Here's the source code and the live game (hosted in my new space-invaders-by-llms repo). It did OK.
Using Codex CLI with gpt-oss:120b on an NVIDIA DGX Spark via Tailscale. Inspired by a YouTube comment I wrote up how I run OpenAI's Codex CLI coding agent against the gpt-oss:120b model running in Ollama on my NVIDIA DGX Spark via a Tailscale network.
It takes a little bit of work to configure but the result is I can now use Codex CLI on my laptop anywhere in the world against a self-hosted model.
I used it to build this space invaders clone.
OpenAI’s new open weight (Apache 2) models are really good
The long promised OpenAI open weight models are here, and they are very impressive. They’re available under proper open source licenses—Apache 2.0—and come in two sizes, 120B and 20B.
[... 2,771 words]XBai o4 (via) Yet another open source (Apache 2.0) LLM from a Chinese AI lab. This model card claims:
XBai o4 excels in complex reasoning capabilities and has now completely surpassed OpenAI-o3-mini in Medium mode.
This a 32.8 billion parameter model released by MetaStone AI, a new-to-me lab who released their first model in March - MetaStone-L1-7B, then followed that with MetaStone-S1 1.5B, 7B and 32B in July and now XBai o4 in August.
The MetaStone-S1 models were accompanied with a paper, Test-Time Scaling with Reflective Generative Model.
There is very little information available on the English-language web about MetaStone AI. Their paper shows a relationship with USTC, University of Science and Technology of China in Hefei. One of their researchers confirmed on Twitter that their CEO is from KWAI which lead me to this Chinese language article from July last year about Li Yan, formerly of KWAI and now the founder of Wen Xiaobai and evidently now the CEO of MetaStone. www.wenxiaobai.com is listed as the "official website" linked to from the XBai-o4 README on GitHub.
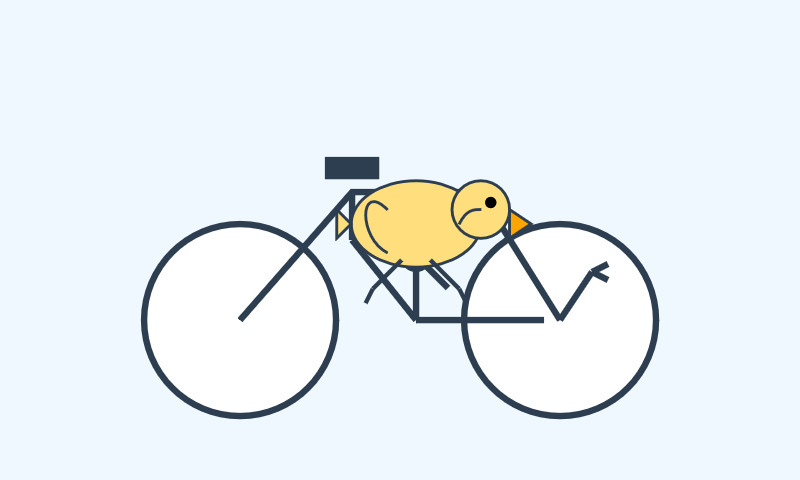
Ivan Fioravanti got it working under MLX in 4bit, 5bit, 6bit, 8bit and 4bit-DWQ sizes. I tried his 6bit one (a 24.81GB download) in LM Studio and had it "Generate an SVG of a pelican riding a bicycle". It thought for 39.49 seconds (thinking trace here) and gave me this:

I also had it "Write an HTML and JavaScript page implementing space invaders", which you can try out here. It's not great - the invaders don't fire bullets (it listed that as a "potential improvement") and I don't think it's winnable due to timing issues, but it's an interesting addition to my collection.
LM Studio reported a constant memory usage of 25.54GB and according to Activity Monitor used 87.5% of my GPU and around 39% of a CPU core.
It did a lot of work in the thinking trace - which took 10m35s! - including writing the first draft of much of the code that ended up in the finished result. Here's an extract:
Let me think of variables:
let enemyDirection = 1; // 1 for right, -1 for leftIn the game loop:
enemies.forEach(enemy => {> enemy.x += enemyDirection * enemy.dx;> });Then check if any enemy is out of bounds. If so, reverse direction and move all enemies down.But how to check if any enemy is at the edge?
Maybe find the max x of all enemies and see if it exceeds
canvas.width - enemy.width.Alternatively, track the leftmost and rightmost positions of enemies. Maybe a bit complex.
For simplicity, perhaps check if any enemy's
x + width > canvas.width or x < 0.
Here's the full transcript.
My initial impressions are that I'm not as impressed with this model for running on my own laptop as I was with Qwen3-Coder-30B-A3B-Instruct or GLM-4.5 Air.
But... how extraordinary is it that another Chinese AI lab has been able to produce a competitive model, this time with far less fanfare than we've seen from Qwen and Moonshot AI and Z.ai.
Trying out Qwen3 Coder Flash using LM Studio and Open WebUI and LLM
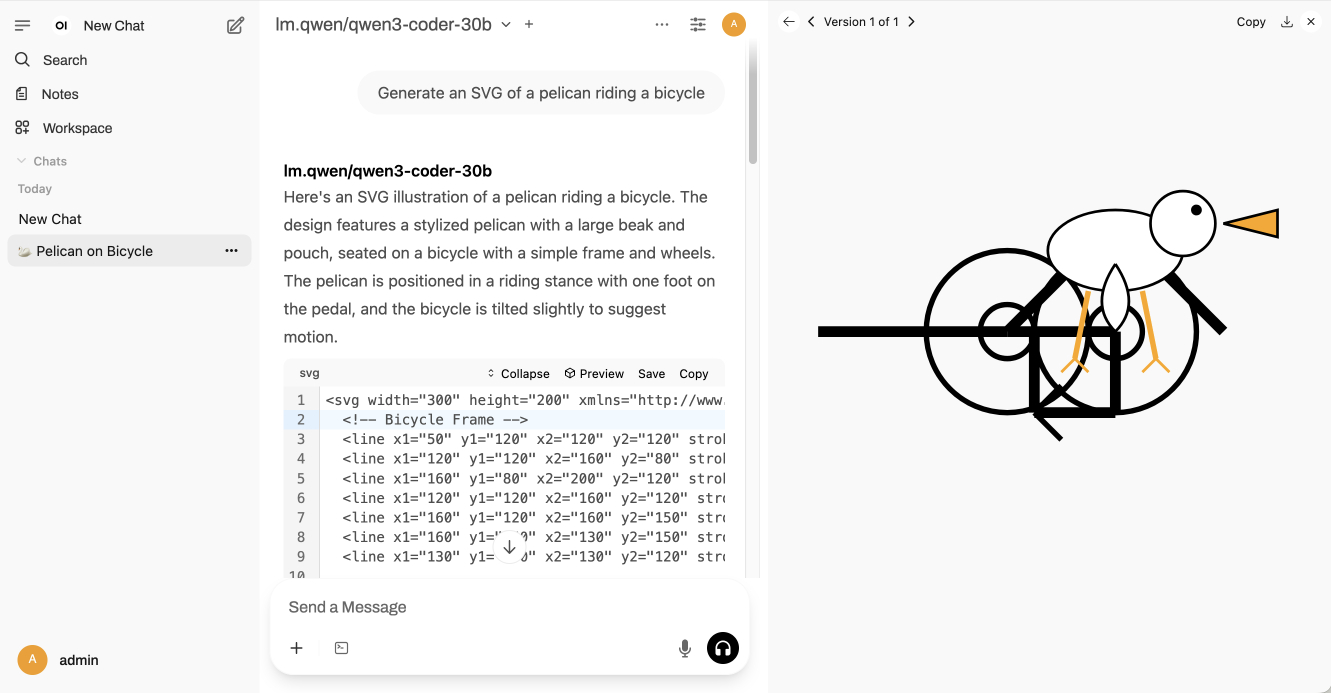
Qwen just released their sixth model(!) of this July called Qwen3-Coder-30B-A3B-Instruct—listed as Qwen3-Coder-Flash in their chat.qwen.ai interface.
[... 1,390 words]Qwen3-30B-A3B-Thinking-2507 (via) Yesterday was Qwen3-30B-A3B-Instruct-2507. Qwen are clearly committed to their new split between reasoning and non-reasoning models (a reversal from Qwen 3 in April), because today they released the new reasoning partner to yesterday's model: Qwen3-30B-A3B-Thinking-2507.
I'm surprised at how poorly this reasoning mode performs at "Generate an SVG of a pelican riding a bicycle" compared to its non-reasoning partner. The reasoning trace appears to carefully consider each component and how it should be positioned... and then the final result looks like this:
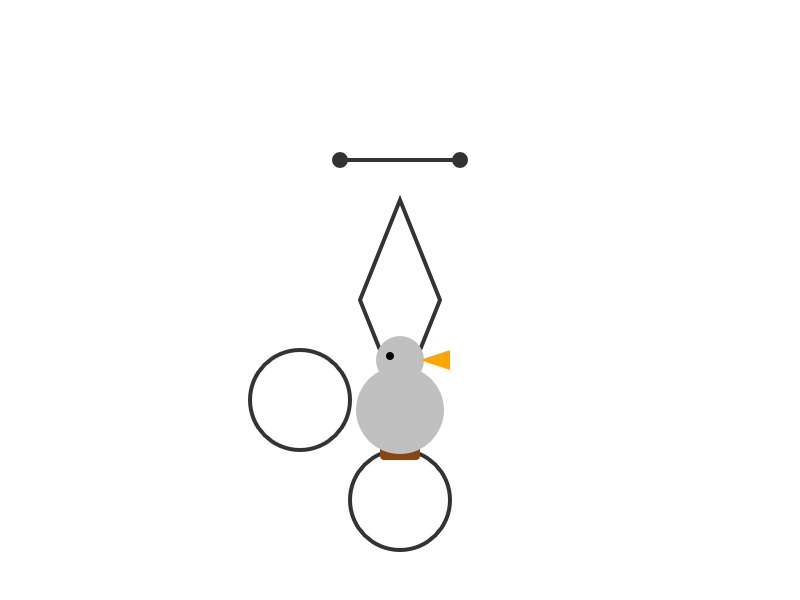
I ran this using chat.qwen.ai/?model=Qwen3-30B-A3B-2507 with the "reasoning" option selected.
I also tried the "Write an HTML and JavaScript page implementing space invaders" prompt I ran against the non-reasoning model. It did a better job in that the game works:
It's not as playable as the on I got from GLM-4.5 Air though - the invaders fire their bullets infrequently enough that the game isn't very challenging.
This model is part of a flurry of releases from Qwen over the past two 9 days. Here's my coverage of each of those:
- Qwen3-235B-A22B-Instruct-2507 - 21st July
- Qwen3-Coder-480B-A35B-Instruct - 22nd July
- Qwen3-235B-A22B-Thinking-2507 - 25th July
- Qwen3-30B-A3B-Instruct-2507 - 29th July
- Qwen3-30B-A3B-Thinking-2507 - today
Qwen3-30B-A3B-Instruct-2507. New model update from Qwen, improving on their previous Qwen3-30B-A3B release from late April. In their tweet they said:
Smarter, faster, and local deployment-friendly.
✨ Key Enhancements:
✅ Enhanced reasoning, coding, and math skills
✅ Broader multilingual knowledge
✅ Improved long-context understanding (up to 256K tokens)
✅ Better alignment with user intent and open-ended tasks
✅ No more<think>blocks — now operating exclusively in non-thinking mode🔧 With 3B activated parameters, it's approaching the performance of GPT-4o and Qwen3-235B-A22B Non-Thinking
I tried the chat.qwen.ai hosted model with "Generate an SVG of a pelican riding a bicycle" and got this:

I particularly enjoyed this detail from the SVG source code:
<!-- Bonus: Pelican's smile -->
<path d="M245,145 Q250,150 255,145" fill="none" stroke="#d4a037" stroke-width="2"/>
I went looking for quantized versions that could fit on my Mac and found lmstudio-community/Qwen3-30B-A3B-Instruct-2507-MLX-8bit from LM Studio. Getting that up and running was a 32.46GB download and it appears to use just over 30GB of RAM.
The pelican I got from that one wasn't as good:

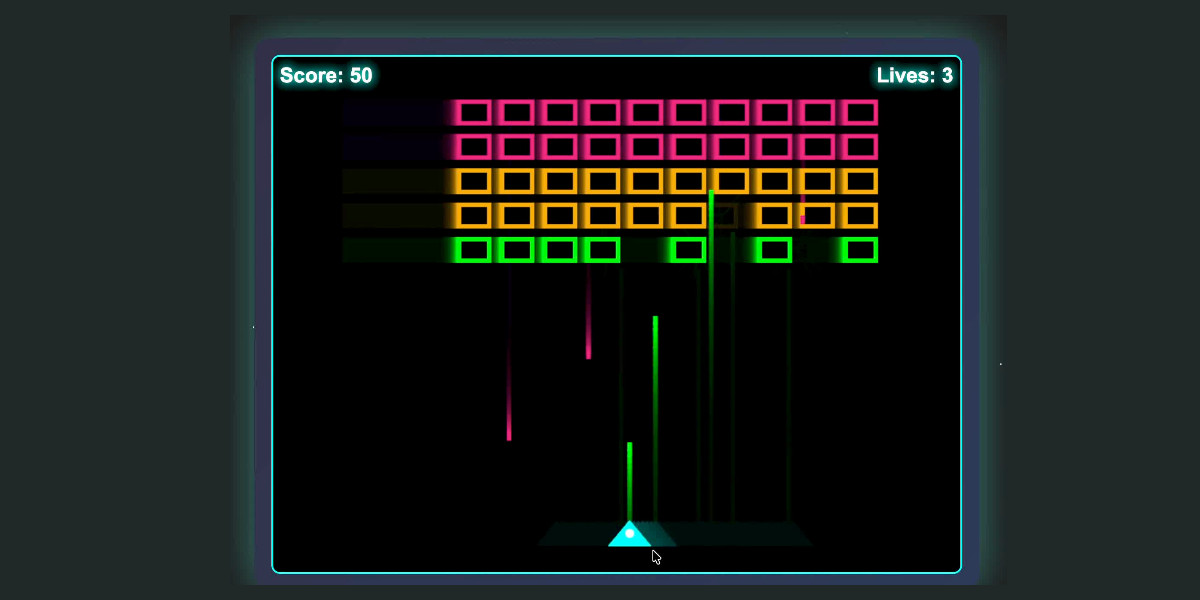
I then tried that local model on the "Write an HTML and JavaScript page implementing space invaders" task that I ran against GLM-4.5 Air. The output looked promising, in particular it seemed to be putting more effort into the design of the invaders (GLM-4.5 Air just used rectangles):
// Draw enemy ship ctx.fillStyle = this.color; // Ship body ctx.fillRect(this.x, this.y, this.width, this.height); // Enemy eyes ctx.fillStyle = '#fff'; ctx.fillRect(this.x + 6, this.y + 5, 4, 4); ctx.fillRect(this.x + this.width - 10, this.y + 5, 4, 4); // Enemy antennae ctx.fillStyle = '#f00'; if (this.type === 1) { // Basic enemy ctx.fillRect(this.x + this.width / 2 - 1, this.y - 5, 2, 5); } else if (this.type === 2) { // Fast enemy ctx.fillRect(this.x + this.width / 4 - 1, this.y - 5, 2, 5); ctx.fillRect(this.x + (3 * this.width) / 4 - 1, this.y - 5, 2, 5); } else if (this.type === 3) { // Armored enemy ctx.fillRect(this.x + this.width / 2 - 1, this.y - 8, 2, 8); ctx.fillStyle = '#0f0'; ctx.fillRect(this.x + this.width / 2 - 1, this.y - 6, 2, 3); }
But the resulting code didn't actually work:

That same prompt against the unquantized Qwen-hosted model produced a different result which sadly also resulted in an unplayable game - this time because everything moved too fast.
This new Qwen model is a non-reasoning model, whereas GLM-4.5 and GLM-4.5 Air are both reasoners. It looks like at this scale the "reasoning" may make a material difference in terms of getting code that works out of the box.
My 2.5 year old laptop can write Space Invaders in JavaScript now, using GLM-4.5 Air and MLX
I wrote about the new GLM-4.5 model family yesterday—new open weight (MIT licensed) models from Z.ai in China which their benchmarks claim score highly in coding even against models such as Claude Sonnet 4.
[... 685 words]