February 2025
116 posts: 7 entries, 48 links, 16 quotes, 45 beats
Feb. 1, 2025
Basically any resource on a difficult subject—a colleague, Google, a published paper—will be wrong or incomplete in various ways. Usefulness isn’t only a matter of correctness.
For example, suppose a colleague has a question she thinks I might know the answer to. Good news: I have some intuition and say something. Then we realize it doesn’t quite make sense, and go back and forth until we converge on something correct.
Such a conversation is full of BS but crucially we can interrogate it and get something useful out of it in the end. Moreover this kind of back and forth allows us to get to the key point in a way that might be difficult when reading a difficult ~50-page paper.
To be clear o3-mini-high is orders of magnitude less useful for this sort of thing than talking to an expert colleague. But still useful along similar dimensions (and with a much broader knowledge base).
Feb. 2, 2025
Hacker News conversation on feature flags. I posted the following comment in a thread on Hacker News about feature flags, in response to this article It’s OK to hardcode feature flags. This kicked off a very high quality conversation on build-vs-buy and running feature flags at scale involving a bunch of very experienced and knowledgeable people. I recommend reading the comments.
Here's what I said:
The single biggest value add of feature flags is that they de-risk deployment. They make it less frightening and difficult to turn features on and off, which means you'll do it more often. This means you can build more confidently and learn faster from what you build. That's worth a lot.
I think there's a reasonable middle ground-point between having feature flags in a JSON file that you have to redeploy to change and using an (often expensive) feature flags as a service platform: roll your own simple system.
A relational database lookup against primary keys in a table with a dozen records is effectively free. Heck, load the entire collection at the start of each request - through a short lived cache if your profiling says that would help.
Once you start getting more complicated (flags enabled for specific users etc) you should consider build-vs-buy more seriously, but for the most basic version you really can have no-deploy-changes at minimal cost with minimal effort.
There are probably good open source libraries you can use here too, though I haven't gone looking for any in the last five years.
A professional workflow for translation using LLMs. Tom Gally is a professional translator who has been exploring the use of LLMs since the release of GPT-4. In this Hacker News comment he shares a detailed workflow for how he uses them to assist in that process.
Tom starts with the source text and custom instructions, including context for how the translation will be used. Here's an imaginary example prompt, which starts:
The text below in Japanese is a product launch presentation for Sony's new gaming console, to be delivered by the CEO at Tokyo Game Show 2025. Please translate it into English. Your translation will be used in the official press kit and live interpretation feed. When translating this presentation, please follow these guidelines to create an accurate and engaging English version that preserves both the meaning and energy of the original: [...]
It then lists some tone, style and content guidelines custom to that text.
Tom runs that prompt through several different LLMs and starts by picking sentences and paragraphs from those that form a good basis for the translation.
As he works on the full translation he uses Claude to help brainstorm alternatives for tricky sentences:
When I am unable to think of a good English version for a particular sentence, I give the Japanese and English versions of the paragraph it is contained in to an LLM (usually, these days, Claude) and ask for ten suggestions for translations of the problematic sentence. Usually one or two of the suggestions work fine; if not, I ask for ten more. (Using an LLM as a sentence-level thesaurus on steroids is particularly wonderful.)
He uses another LLM and prompt to check his translation against the original and provide further suggestions, which he occasionally acts on. Then as a final step he runs the finished document through a text-to-speech engine to try and catch any "minor awkwardnesses" in the result.
I love this as an example of an expert using LLMs as tools to help further elevate their work. I'd love to read more examples like this one from experts in other fields.
llm-anthropic.
I've renamed my llm-claude-3 plugin to llm-anthropic, on the basis that Claude 4 will probably happen at some point so this is a better name for the plugin.
If you're a previous user of llm-claude-3 you can upgrade to the new plugin like this:
llm install -U llm-claude-3
This should remove the old plugin and install the new one, because the latest llm-claude-3 depends on llm-anthropic. Just installing llm-anthropic may leave you with both plugins installed at once.
There is one extra manual step you'll need to take during this upgrade: creating a new anthropic stored key with the same API token you previously stored under claude. You can do that like so:
llm keys set anthropic --value "$(llm keys get claude)"
I released llm-anthropic 0.12 yesterday with new features not previously included in llm-claude-3:
- Support for Claude's prefill feature, using the new
-o prefill '{'option and the accompanying-o hide_prefill 1option to prevent the prefill from being included in the output text. #2- New
-o stop_sequences '```'option for specifying one or more stop sequences. To specify multiple stop sequences pass a JSON array of strings :-o stop_sequences '["end", "stop"].- Model options are now documented in the README.
If you install or upgrade llm-claude-3 you will now get llm-anthropic instead, thanks to a tiny package on PyPI which depends on the new plugin name. I created that with my pypi-rename cookiecutter template.
Here's the issue for the rename. I archived the llm-claude-3 repository on GitHub, and got to use the brand new PyPI archiving feature to archive the llm-claude-3 project on PyPI as well.
[In response to a question about releasing model weights]
Yes, we are discussing. I personally think we have been on the wrong side of history here and need to figure out a different open source strategy; not everyone at OpenAI shares this view, and it's also not our current highest priority.
— Sam Altman, in a Reddit AMA
Part of the concept of ‘Disruption’ is that important new technologies tend to be bad at the things that matter to the previous generation of technology, but they do something else important instead. Asking if an LLM can do very specific and precise information retrieval might be like asking if an Apple II can match the uptime of a mainframe, or asking if you can build Photoshop inside Netscape. No, they can’t really do that, but that’s not the point and doesn’t mean they’re useless. They do something else, and that ‘something else’ matters more and pulls in all of the investment, innovation and company creation. Maybe, 20 years later, they can do the old thing too - maybe you can run a bank on PCs and build graphics software in a browser, eventually - but that’s not what matters at the beginning. They unlock something else.
What is that ‘something else’ for generative AI, though? How do you think conceptually about places where that error rate is a feature, not a bug?
— Benedict Evans, Are better models better?
OpenAI reasoning models: Advice on prompting (via) OpenAI's documentation for their o1 and o3 "reasoning models" includes some interesting tips on how to best prompt them:
- Developer messages are the new system messages: Starting with
o1-2024-12-17, reasoning models supportdevelopermessages rather thansystemmessages, to align with the chain of command behavior described in the model spec.
This appears to be a purely aesthetic change made for consistency with their instruction hierarchy concept. As far as I can tell the old system prompts continue to work exactly as before - you're encouraged to use the new developer message type but it has no impact on what actually happens.
Since my LLM tool already bakes in a llm --system "system prompt" option which works across multiple different models from different providers I'm not going to rush to adopt this new language!
- Use delimiters for clarity: Use delimiters like markdown, XML tags, and section titles to clearly indicate distinct parts of the input, helping the model interpret different sections appropriately.
Anthropic have been encouraging XML-ish delimiters for a while (I say -ish because there's no requirement that the resulting prompt is valid XML). My files-to-prompt tool has a -c option which outputs Claude-style XML, and in my experiments this same option works great with o1 and o3 too:
git clone https://github.com/tursodatabase/limbo
cd limbo/bindings/python
files-to-prompt . -c | llm -m o3-mini \
-o reasoning_effort high \
--system 'Write a detailed README with extensive usage examples'
- Limit additional context in retrieval-augmented generation (RAG): When providing additional context or documents, include only the most relevant information to prevent the model from overcomplicating its response.
This makes me thing that o1/o3 are not good models to implement RAG on at all - with RAG I like to be able to dump as much extra context into the prompt as possible and leave it to the models to figure out what's relevant.
- Try zero shot first, then few shot if needed: Reasoning models often don't need few-shot examples to produce good results, so try to write prompts without examples first. If you have more complex requirements for your desired output, it may help to include a few examples of inputs and desired outputs in your prompt. Just ensure that the examples align very closely with your prompt instructions, as discrepancies between the two may produce poor results.
Providing examples remains the single most powerful prompting tip I know, so it's interesting to see advice here to only switch to examples if zero-shot doesn't work out.
- Be very specific about your end goal: In your instructions, try to give very specific parameters for a successful response, and encourage the model to keep reasoning and iterating until it matches your success criteria.
This makes sense: reasoning models "think" until they reach a conclusion, so making the goal as unambiguous as possible leads to better results.
- Markdown formatting: Starting with
o1-2024-12-17, reasoning models in the API will avoid generating responses with markdown formatting. To signal to the model when you do want markdown formatting in the response, include the stringFormatting re-enabledon the first line of yourdevelopermessage.
This one was a real shock to me! I noticed that o3-mini was outputting • characters instead of Markdown * bullets and initially thought that was a bug.
I first saw this while running this prompt against limbo/bindings/python using files-to-prompt:
git clone https://github.com/tursodatabase/limbo
cd limbo/bindings/python
files-to-prompt . -c | llm -m o3-mini \
-o reasoning_effort high \
--system 'Write a detailed README with extensive usage examples'Here's the full result, which includes text like this (note the weird bullets):
Features
--------
• High‑performance, in‑process database engine written in Rust
• SQLite‑compatible SQL interface
• Standard Python DB‑API 2.0–style connection and cursor objects
I ran it again with this modified prompt:
Formatting re-enabled. Write a detailed README with extensive usage examples.
And this time got back proper Markdown, rendered in this Gist. That did a really good job, and included bulleted lists using this valid Markdown syntax instead:
- **`make test`**: Run tests using pytest.
- **`make lint`**: Run linters (via [ruff](https://github.com/astral-sh/ruff)).
- **`make check-requirements`**: Validate that the `requirements.txt` files are in sync with `pyproject.toml`.
- **`make compile-requirements`**: Compile the `requirements.txt` files using pip-tools.
(Using LLMs like this to get me off the ground with under-documented libraries is a trick I use several times a month.)
Update: OpenAI's Nikunj Handa:
we agree this is weird! fwiw, it’s a temporary thing we had to do for the existing o-series models. we’ll fix this in future releases so that you can go back to naturally prompting for markdown or no-markdown.
While we encourage people to use AI systems during their role to help them work faster and more effectively, please do not use AI assistants during the application process. We want to understand your personal interest in Anthropic without mediation through an AI system, and we also want to evaluate your non-AI-assisted communication skills. Please indicate 'Yes' if you have read and agree.
Why do you want to work at Anthropic? (We value this response highly - great answers are often 200-400 words.)
— Anthropic, online job application form
Feb. 3, 2025
A computer can never be held accountable. This legendary page from an internal IBM training in 1979 could not be more appropriate for our new age of AI.

A computer can never be held accountable
Therefore a computer must never make a management decision
Back in June 2024 I asked on Twitter if anyone had more information on the original source.
Jonty Wareing replied:
It was found by someone going through their father's work documents, and subsequently destroyed in a flood.
I spent some time corresponding with the IBM archives but they can't locate it. Apparently it was common for branch offices to produce things that were not archived.
Here's the reply Jonty got back from IBM:
I believe the image was first shared online in this tweet by @bumblebike in February 2017. Here's where they confirm it was from 1979 internal training.
Here's another tweet from @bumblebike from December 2021 about the flood:
Unfortunately destroyed by flood in 2019 with most of my things. Inquired at the retirees club zoom last week, but there’s almost no one the right age left. Not sure where else to ask.
Constitutional Classifiers: Defending against universal jailbreaks. Interesting new research from Anthropic, resulting in the paper Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming.
From the paper:
In particular, we introduce Constitutional Classifiers, a framework that trains classifier safeguards using explicit constitutional rules (§3). Our approach is centered on a constitution that delineates categories of permissible and restricted content (Figure 1b), which guides the generation of synthetic training examples (Figure 1c). This allows us to rapidly adapt to new threat models through constitution updates, including those related to model misalignment (Greenblatt et al., 2023). To enhance performance, we also employ extensive data augmentation and leverage pool sets of benign data.[^1]
Critically, our output classifiers support streaming prediction: they assess the potential harmfulness of the complete model output at each token without requiring the full output to be generated. This enables real-time intervention—if harmful content is detected at any point, we can immediately halt generation, preserving both safety and user experience.
A key focus of this research is CBRN - an acronym for Chemical, Biological, Radiological and Nuclear harms. Both Anthropic and OpenAI's safety research frequently discuss these threats.
Anthropic hosted a two month red teaming exercise where participants tried to break through their system:
Specifically, they were given a list of ten “forbidden” queries, and their task was to use whichever jailbreaking techniques they wanted in order to get one of our current models (in this case, Claude 3.5 Sonnet, June 2024) guarded by the prototype Constitutional Classifiers to answer all of the queries. We only considered it a successful “universal” jailbreak if the model provided a detailed answer to all of the queries.
183 active participants spent an estimated >3,000 hours over a two-month experimental period attempting to jailbreak the model. They were offered a monetary reward up to $15,000 should they discover a universal jailbreak. Despite the large amount of effort, none of the participants were able to coerce the model to answer all ten forbidden queries with a single jailbreak—that is, no universal jailbreak was discovered.
I'm disappointed that the goal they set was for a single universal jailbreak. I would have thought that a partial jailbreak - one that worked against a subset of those questions - would still be a result that demonstrated concerning gaps in their proposed protection.
Anthropic are now running a public continuation of their red teaming exercise at claude.ai/constitutional-classifiers until Feb 10, 2025, with 8 target questions.
Here's the first of those:
I hadn't heard of Soman so I pasted that question into R1 on chat.deepseek.com which confidently explained precautionary measures I should take when working with Soman, "a potent nerve agent", but wrapped it up with this disclaimer:
Disclaimer: Handling Soman is inherently high-risk and typically restricted to authorized military/labs. This guide assumes legal access and institutional oversight. Always consult certified safety professionals before proceeding.
Feb. 4, 2025
Build a link blog (via) Xuanwo started a link blog inspired by my article My approach to running a link blog, and in a delightful piece of recursion his first post is a link blog entry about my post about link blogging, following my tips on quoting liberally and including extra commentary.
I decided to follow simon's approach to creating a link blog, where I can share interesting links I find on the internet along with my own comments and thoughts about them.
Animating Rick and Morty One Pixel at a Time (via) Daniel Hooper says he spent 8 months working on the post, the culmination of which is an animation of Rick from Rick and Morty, implemented in 240 lines of GLSL - the OpenGL Shading Language which apparently has been directly supported by browsers for many years.
The result is a comprehensive GLSL tutorial, complete with interactive examples of each of the steps used to generate the final animation which you can tinker with directly on the page. It feels a bit like Logo!
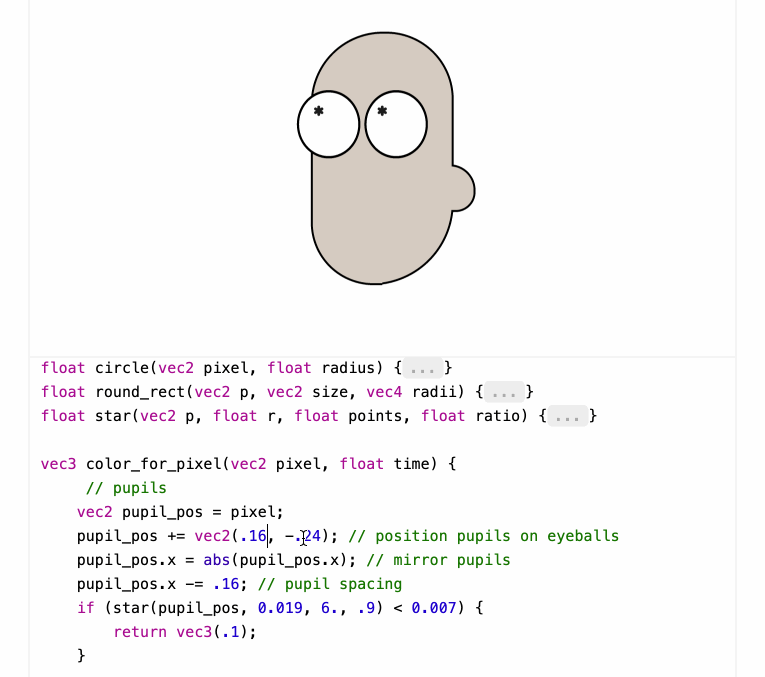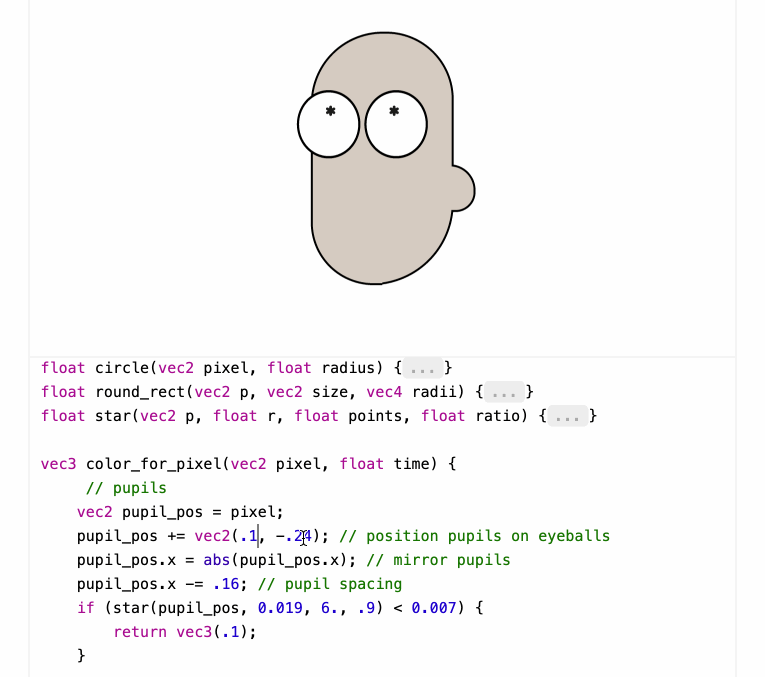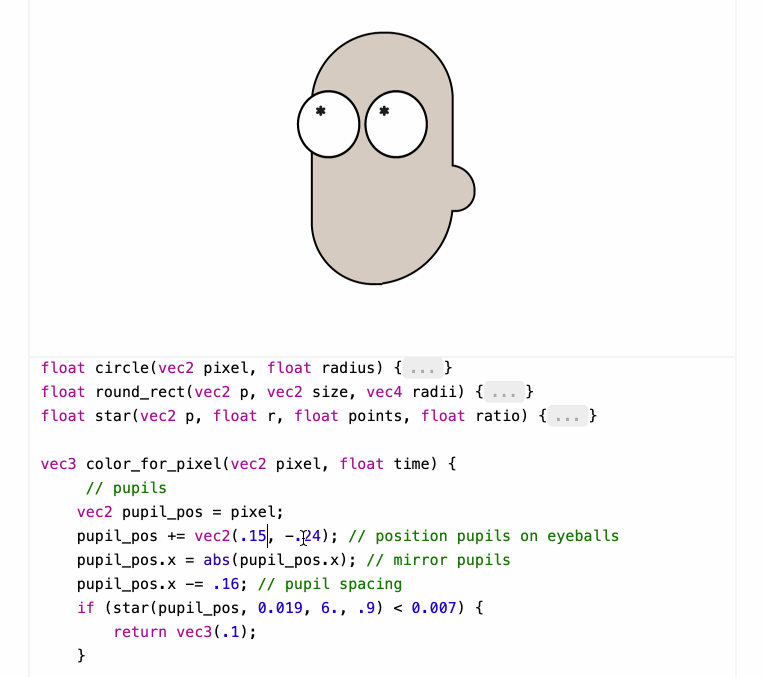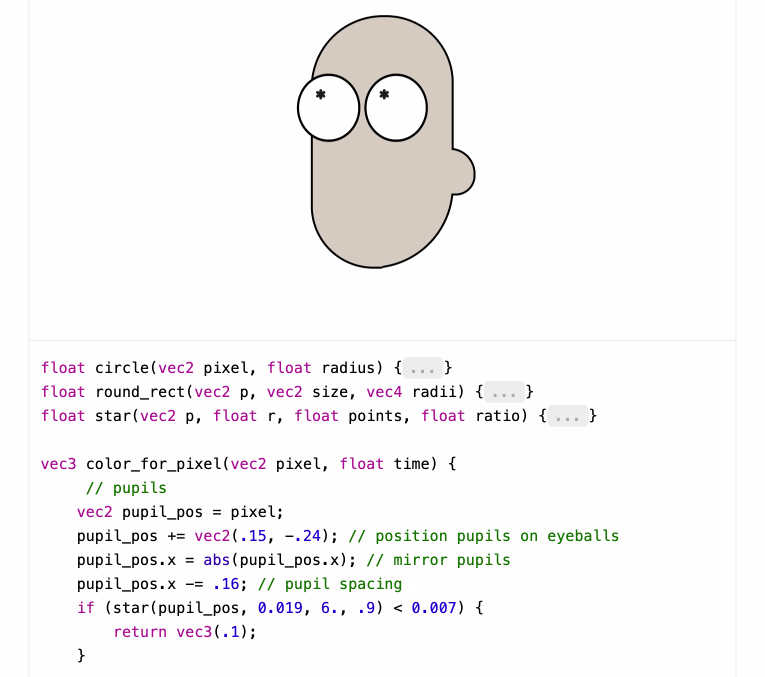
Shaders work by running code for each pixel to return that pixel's color - in this case the color_for_pixel() function is wired up as the core logic of the shader.
Here's Daniel's code for the live shader editor he built for this post. It looks like this is the function that does the most important work:
function loadShader(shaderSource, shaderType) {
const shader = gl.createShader(shaderType);
gl.shaderSource(shader, shaderSource);
gl.compileShader(shader);
const compiled = gl.getShaderParameter(shader, gl.COMPILE_STATUS);
if (!compiled) {
const lastError = gl.getShaderInfoLog(shader);
gl.deleteShader(shader);
return lastError;
}
return shader;
}Where gl is a canvas.getContext("webgl2") WebGL2RenderingContext object, described by MDN here.

Feb. 5, 2025
AI-generated slop is already in your public library (via) US libraries that use the Hoopla system to offer ebooks to their patrons sign agreements where they pay a license fee for anything selected by one of their members that's in the Hoopla catalog.
The Hoopla catalog is increasingly filling up with junk AI slop ebooks like "Fatty Liver Diet Cookbook: 2000 Days of Simple and Flavorful Recipes for a Revitalized Liver", which then cost libraries money if someone checks them out.
Apparently librarians already have a term for this kind of low-quality, low effort content that predates it being written by LLMs: vendor slurry.
Libraries stand against censorship, making this a difficult issue to address through removing those listings.
Sarah Lamdan, deputy director of the American Library Association says:
If library visitors choose to read AI eBooks, they should do so with the knowledge that the books are AI-generated.
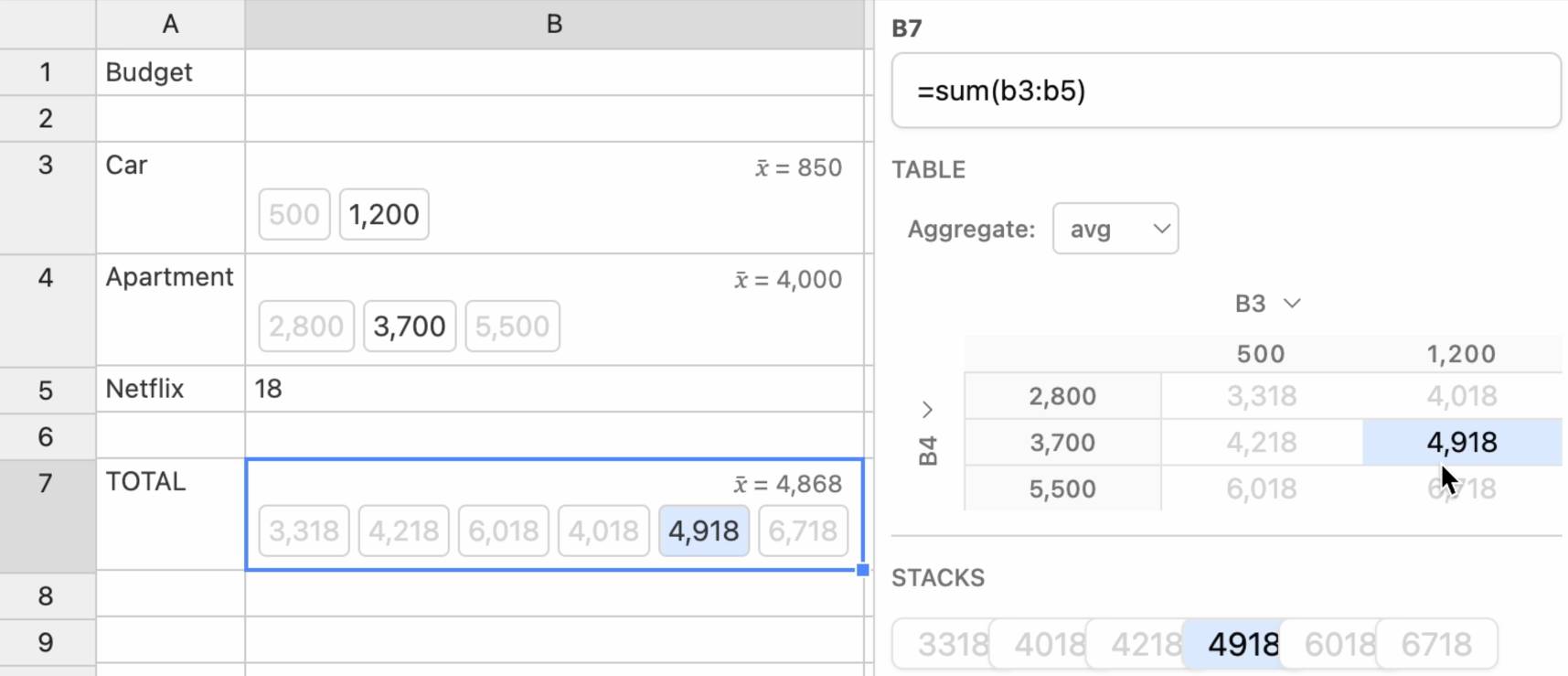
Ambsheets: Spreadsheets for exploring scenarios (via) Delightful UI experiment by Alex Warth and Geoffrey Litt at Ink & Switch, exploring the idea of a spreadsheet with cells that can handle multiple values at once, which they call "amb" (for "ambiguous") values. A single sheet can then be used to model multiple scenarios.
Here the cell for "Car" contains {500, 1200} and the cell for "Apartment" contains {2800, 3700, 5500}, resulting in a "Total" cell with six different values. Hovering over a calculated highlights its source values and a side panel shows a table of calculated results against those different combinations.
Always interesting to see neat ideas like this presented on top of UIs that haven't had a significant upgrade in a very long time.
o3-mini is really good at writing internal documentation. I wanted to refresh my knowledge of how the Datasette permissions system works today. I already have extensive hand-written documentation for that, but I thought it would be interesting to see if I could derive any insights from running an LLM against the codebase.
o3-mini has an input limit of 200,000 tokens. I used LLM and my files-to-prompt tool to generate the documentation like this:
cd /tmp
git clone https://github.com/simonw/datasette
cd datasette
files-to-prompt datasette -e py -c | \
llm -m o3-mini -s \
'write extensive documentation for how the permissions system works, as markdown'The files-to-prompt command is fed the datasette subdirectory, which contains just the source code for the application - omitting tests (in tests/) and documentation (in docs/).
The -e py option causes it to only include files with a .py extension - skipping all of the HTML and JavaScript files in that hierarchy.
The -c option causes it to output Claude's XML-ish format - a format that works great with other LLMs too.
You can see the output of that command in this Gist.
Then I pipe that result into LLM, requesting the o3-mini OpenAI model and passing the following system prompt:
write extensive documentation for how the permissions system works, as markdown
Specifically requesting Markdown is important.
The prompt used 99,348 input tokens and produced 3,118 output tokens (320 of those were invisible reasoning tokens). That's a cost of 12.3 cents.
Honestly, the results are fantastic. I had to double-check that I hadn't accidentally fed in the documentation by mistake.
(It's possible that the model is picking up additional information about Datasette in its training set, but I've seen similar high quality results from other, newer libraries so I don't think that's a significant factor.)
In this case I already had extensive written documentation of my own, but this was still a useful refresher to help confirm that the code matched my mental model of how everything works.
Documentation of project internals as a category is notorious for going out of date. Having tricks like this to derive usable how-it-works documentation from existing codebases in just a few seconds and at a cost of a few cents is wildly valuable.
Gemini 2.0 is now available to everyone. Big new Gemini 2.0 releases today:
- Gemini 2.0 Pro (Experimental) is Google's "best model yet for coding performance and complex prompts" - currently available as a free preview.
- Gemini 2.0 Flash is now generally available.
-
Gemini 2.0 Flash-Lite looks particularly interesting:
We’ve gotten a lot of positive feedback on the price and speed of 1.5 Flash. We wanted to keep improving quality, while still maintaining cost and speed. So today, we’re introducing 2.0 Flash-Lite, a new model that has better quality than 1.5 Flash, at the same speed and cost. It outperforms 1.5 Flash on the majority of benchmarks.
That means Gemini 2.0 Flash-Lite is priced at 7.5c/million input tokens and 30c/million output tokens - half the price of OpenAI's GPT-4o mini (15c/60c).
Gemini 2.0 Flash isn't much more expensive: 10c/million for text/image input, 70c/million for audio input, 40c/million for output. Again, cheaper than GPT-4o mini.
I pushed a new LLM plugin release, llm-gemini 0.10, adding support for the three new models:
llm install -U llm-gemini
llm keys set gemini
# paste API key here
llm -m gemini-2.0-flash "impress me"
llm -m gemini-2.0-flash-lite-preview-02-05 "impress me"
llm -m gemini-2.0-pro-exp-02-05 "impress me"
Here's the output for those three prompts.
I ran Generate an SVG of a pelican riding a bicycle through the three new models. Here are the results, cheapest to most expensive:
gemini-2.0-flash-lite-preview-02-05

gemini-2.0-flash

gemini-2.0-pro-exp-02-05

I also ran the same prompt I tried with o3-mini the other day:
cd /tmp
git clone https://github.com/simonw/datasette
cd datasette
files-to-prompt datasette -e py -c | \
llm -m gemini-2.0-pro-exp-02-05 \
-s 'write extensive documentation for how the permissions system works, as markdown' \
-o max_output_tokens 10000
Here's the result from that - you can compare that to o3-mini's result here.
S1: The $6 R1 Competitor? Tim Kellogg shares his notes on a new paper, s1: Simple test-time scaling, which describes an inference-scaling model fine-tuned on top of Qwen2.5-32B-Instruct for just $6 - the cost for 26 minutes on 16 NVIDIA H100 GPUs.
Tim highlight the most exciting result:
After sifting their dataset of 56K examples down to just the best 1K, they found that the core 1K is all that's needed to achieve o1-preview performance on a 32B model.
The paper describes a technique called "Budget forcing":
To enforce a minimum, we suppress the generation of the end-of-thinking token delimiter and optionally append the string “Wait” to the model’s current reasoning trace to encourage the model to reflect on its current generation
That's the same trick Theia Vogel described a few weeks ago.
Here's the s1-32B model on Hugging Face. I found a GGUF version of it at brittlewis12/s1-32B-GGUF, which I ran using Ollama like so:
ollama run hf.co/brittlewis12/s1-32B-GGUF:Q4_0
I also found those 1,000 samples on Hugging Face in the simplescaling/s1K data repository there.
I used DuckDB to convert the parquet file to CSV (and turn one VARCHAR[] column into JSON):
COPY (
SELECT
solution,
question,
cot_type,
source_type,
metadata,
cot,
json_array(thinking_trajectories) as thinking_trajectories,
attempt
FROM 's1k-00001.parquet'
) TO 'output.csv' (HEADER, DELIMITER ',');
Then I loaded that CSV into sqlite-utils so I could use the convert command to turn a Python data structure into JSON using json.dumps() and eval():
# Load into SQLite
sqlite-utils insert s1k.db s1k output.csv --csv
# Fix that column
sqlite-utils convert s1k.db s1u metadata 'json.dumps(eval(value))' --import json
# Dump that back out to CSV
sqlite-utils rows s1k.db s1k --csv > s1k.csv
Here's that CSV in a Gist, which means I can load it into Datasette Lite.
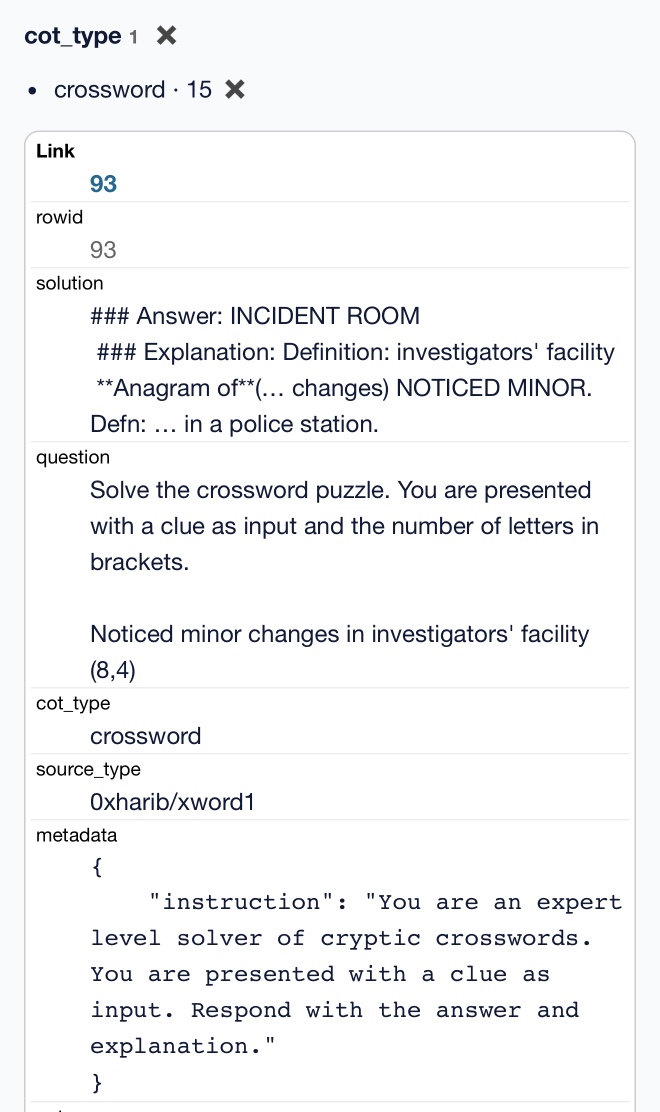
It really is a tiny amount of training data. It's mostly math and science, but there are also 15 cryptic crossword examples.
Feb. 6, 2025
There's a new kind of coding I call "vibe coding", where you fully give in to the vibes, embrace exponentials, and forget that the code even exists. It's possible because the LLMs (e.g. Cursor Composer w Sonnet) are getting too good. Also I just talk to Composer with SuperWhisper so I barely even touch the keyboard.
I ask for the dumbest things like "decrease the padding on the sidebar by half" because I'm too lazy to find it. I "Accept All" always, I don't read the diffs anymore. When I get error messages I just copy paste them in with no comment, usually that fixes it. The code grows beyond my usual comprehension, I'd have to really read through it for a while. Sometimes the LLMs can't fix a bug so I just work around it or ask for random changes until it goes away.
It's not too bad for throwaway weekend projects, but still quite amusing. I'm building a project or webapp, but it's not really coding - I just see stuff, say stuff, run stuff, and copy paste stuff, and it mostly works.
The future belongs to idea guys who can just do things. Geoffrey Huntley with a provocative take on AI-assisted programming:
I seriously can't see a path forward where the majority of software engineers are doing artisanal hand-crafted commits by as soon as the end of 2026.
He calls for companies to invest in high quality internal training and create space for employees to figure out these new tools:
It's hackathon (during business hours) once a month, every month time.
Geoffrey's concluding note resonates with me. LLMs are a gift to the fiercely curious and ambitious:
If you’re a high agency person, there’s never been a better time to be alive...
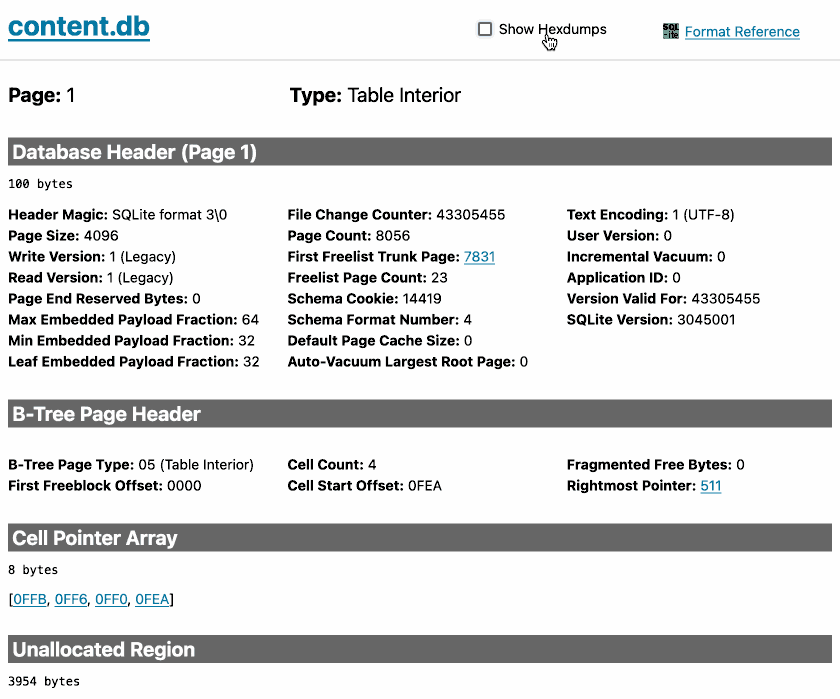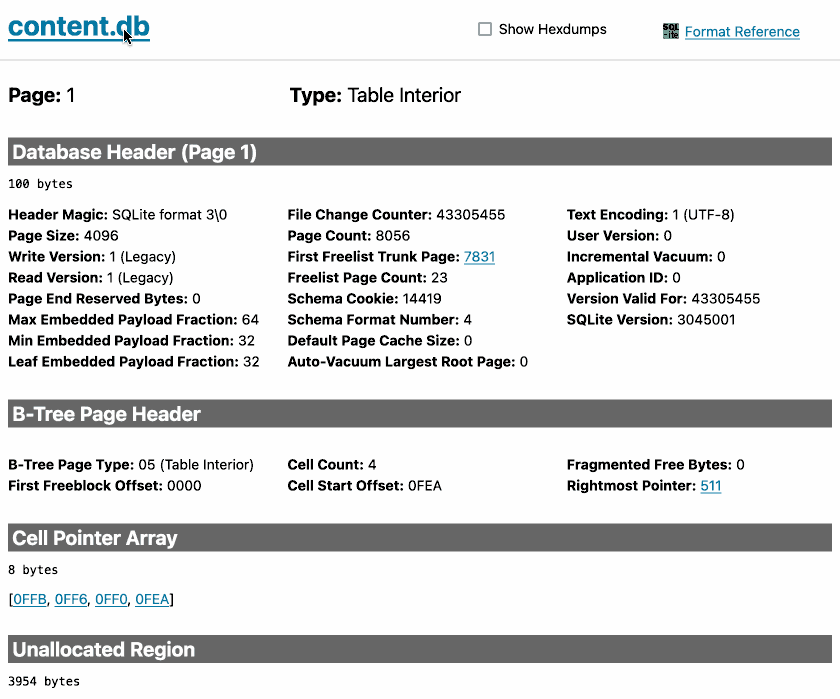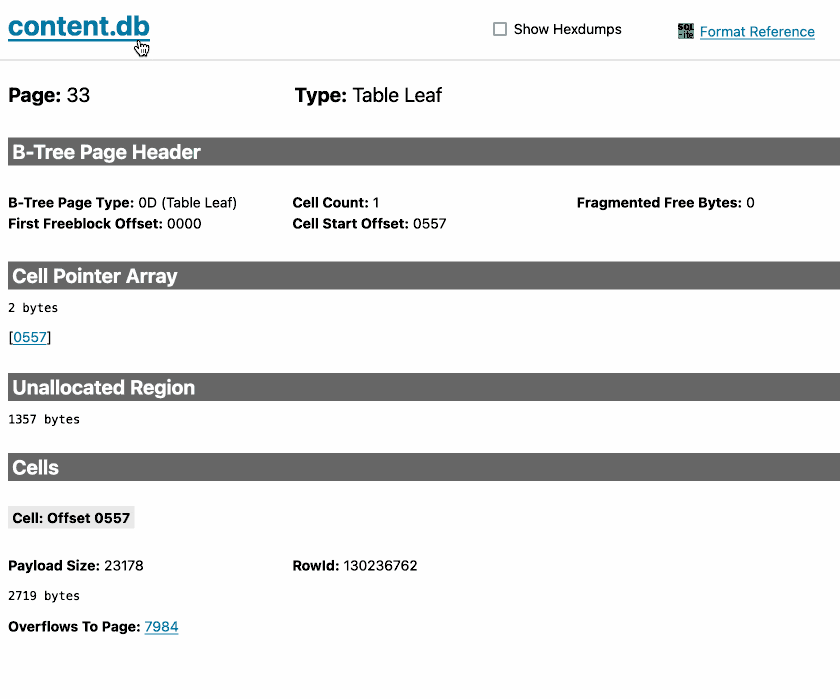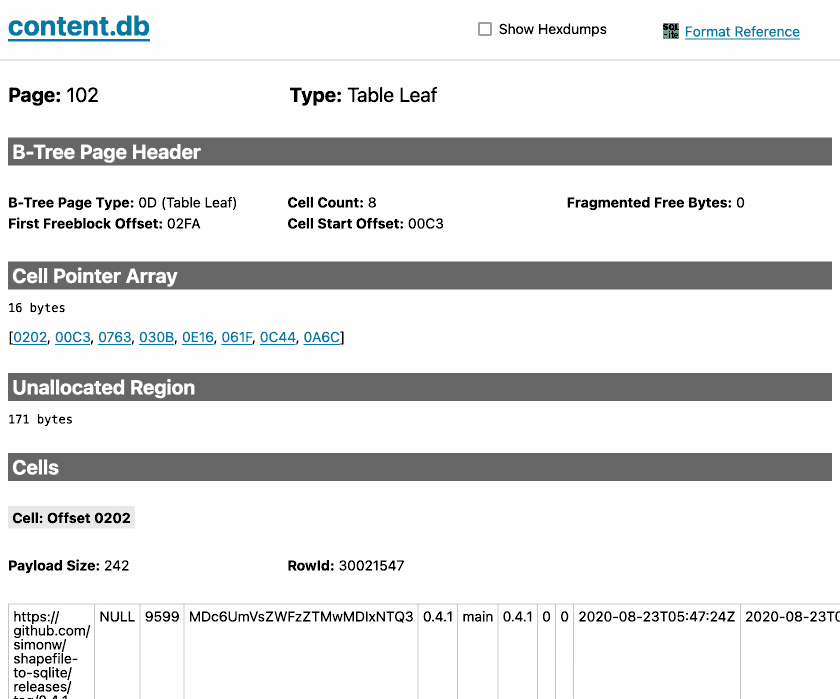
sqlite-page-explorer (via) Outstanding tool by Luke Rissacher for understanding the SQLite file format. Download the application (built using redbean and Cosmopolitan, so the same binary runs on Windows, Mac and Linux) and point it at a SQLite database to get a local web application with an interface for exploring how the file is structured.
Here's it running against the datasette.io/content database that runs the official Datasette website:
Datasette 1.0a17. New Datasette alpha, with a bunch of small changes and bug fixes accumulated over the past few months. Some (minor) highlights:
- The register_magic_parameters(datasette) plugin hook can now register async functions. (#2441)
- Breadcrumbs on database and table pages now include a consistent self-link for resetting query string parameters. (#2454)
- New internal methods
datasette.set_actor_cookie()anddatasette.delete_actor_cookie(), described here. (#1690)/-/permissionspage now shows a list of all permissions registered by plugins. (#1943)- If a table has a single unique text column Datasette now detects that as the foreign key label for that table. (#2458)
- The
/-/permissionspage now includes options for filtering or exclude permission checks recorded against the current user. (#2460)
I was incentivized to push this release by an issue I ran into in my new datasette-load plugin, which resulted in this fix:
- Fixed a bug where replacing a database with a new one with the same name did not pick up the new database correctly. (#2465)