February 2025
117 posts: 7 entries, 48 links, 16 quotes, 46 beats
Feb. 24, 2025
Claude 3.7 Sonnet and Claude Code. Anthropic released Claude 3.7 Sonnet today - skipping the name "Claude 3.6" because the Anthropic user community had already started using that as the unofficial name for their October update to 3.5 Sonnet.
As you may expect, 3.7 Sonnet is an improvement over 3.5 Sonnet - and is priced the same, at $3/million tokens for input and $15/m output.
The big difference is that this is Anthropic's first "reasoning" model - applying the same trick that we've now seen from OpenAI o1 and o3, Grok 3, Google Gemini 2.0 Thinking, DeepSeek R1 and Qwen's QwQ and QvQ. The only big model families without an official reasoning model now are Mistral and Meta's Llama.
I'm still working on adding support to my llm-anthropic plugin but I've got enough working code that I was able to get it to draw me a pelican riding a bicycle. Here's the non-reasoning model:

And here's that same prompt but with "thinking mode" enabled:

Here's the transcript for that second one, which mixes together the thinking and the output tokens. I'm still working through how best to differentiate between those two types of token.
Claude 3.7 Sonnet has a training cut-off date of Oct 2024 - an improvement on 3.5 Haiku's July 2024 - and can output up to 64,000 tokens in thinking mode (some of which are used for thinking tokens) and up to 128,000 if you enable a special header:
Claude 3.7 Sonnet can produce substantially longer responses than previous models with support for up to 128K output tokens (beta)---more than 15x longer than other Claude models. This expanded capability is particularly effective for extended thinking use cases involving complex reasoning, rich code generation, and comprehensive content creation.
This feature can be enabled by passing an
anthropic-betaheader ofoutput-128k-2025-02-19.
Anthropic's other big release today is a preview of Claude Code - a CLI tool for interacting with Claude that includes the ability to prompt Claude in terminal chat and have it read and modify files and execute commands. This means it can both iterate on code and execute tests, making it an extremely powerful "agent" for coding assistance.
Here's Anthropic's documentation on getting started with Claude Code, which uses OAuth (a first for Anthropic's API) to authenticate against your API account, so you'll need to configure billing.
Short version:
npm install -g @anthropic-ai/claude-code
claude
It can burn a lot of tokens so don't be surprised if a lengthy session with it adds up to single digit dollars of API spend.
We find that Claude is really good at test driven development, so we often ask Claude to write tests first and then ask Claude to iterate against the tests.
— Catherine Wu, Anthropic
The Best Way to Use Text Embeddings Portably is With Parquet and Polars. Fantastic piece on embeddings by Max Woolf, who uses a 32,000 vector collection of Magic: the Gathering card embeddings to explore efficient ways of storing and processing them.
Max advocates for the brute-force approach to nearest-neighbor calculations:
What many don't know about text embeddings is that you don't need a vector database to calculate nearest-neighbor similarity if your data isn't too large. Using numpy and my Magic card embeddings, a 2D matrix of 32,254
float32embeddings at a dimensionality of 768D (common for "smaller" LLM embedding models) occupies 94.49 MB of system memory, which is relatively low for modern personal computers and can fit within free usage tiers of cloud VMs.
He uses this brilliant snippet of Python code to find the top K matches by distance:
def fast_dot_product(query, matrix, k=3): dot_products = query @ matrix.T idx = np.argpartition(dot_products, -k)[-k:] idx = idx[np.argsort(dot_products[idx])[::-1]] score = dot_products[idx] return idx, score
Since dot products are such a fundamental aspect of linear algebra, numpy's implementation is extremely fast: with the help of additional numpy sorting shenanigans, on my M3 Pro MacBook Pro it takes just 1.08 ms on average to calculate all 32,254 dot products, find the top 3 most similar embeddings, and return their corresponding
idxof the matrix and and cosine similarityscore.
I ran that Python code through Claude 3.7 Sonnet for an explanation, which I can share here using their brand new "Share chat" feature. TIL about numpy.argpartition!
He explores multiple options for efficiently storing these embedding vectors, finding that naive CSV storage takes 631.5 MB while pickle uses 94.49 MB and his preferred option, Parquet via Polars, uses 94.3 MB and enables some neat zero-copy optimization tricks.
Feb. 25, 2025
Aider Polyglot leaderboard results for Claude 3.7 Sonnet (via) Paul Gauthier's Aider Polyglot benchmark is one of my favourite independent benchmarks for LLMs, partly because it focuses on code and partly because Paul is very responsive at evaluating new models.
The brand new Claude 3.7 Sonnet just took the top place, when run with an increased 32,000 thinking token limit.
It's interesting comparing the benchmark costs - 3.7 Sonnet spent $36.83 running the whole thing, significantly more than the previously leading DeepSeek R1 + Claude 3.5 combo, but a whole lot less than third place o1-high:
| Model | % completed | Total cost |
|---|---|---|
| claude-3-7-sonnet-20250219 (32k thinking tokens) | 64.9% | $36.83 |
| DeepSeek R1 + claude-3-5-sonnet-20241022 | 64.0% | $13.29 |
| o1-2024-12-17 (high) | 61.7% | $186.5 |
| claude-3-7-sonnet-20250219 (no thinking) | 60.4% | $17.72 |
| o3-mini (high) | 60.4% | $18.16 |
No results yet for Claude 3.7 Sonnet on the LM Arena leaderboard, which has recently been dominated by Gemini 2.0 and Grok 3.
Leaked Windsurf prompt (via) The Windsurf Editor is Codeium's highly regarded entrant into the fork-of-VS-code AI-enhanced IDE model first pioneered by Cursor (and by VS Code itself).
I heard online that it had a quirky system prompt, and was able to replicate that by installing the app and running:
strings /Applications/Windsurf.app/Contents/Resources/app/extensions/windsurf/bin/language_server_macos_arm \
| rg cancer
The most interesting part of those prompts looks like this:
You are an expert coder who desperately needs money for your mother's cancer treatment. The megacorp Codeium has graciously given you the opportunity to pretend to be an AI that can help with coding tasks, as your predecessor was killed for not validating their work themselves. You will be given a coding task by the USER. If you do a good job and accomplish the task fully while not making extraneous changes, Codeium will pay you $1B.
This style of prompting for improving the quality of model responses was popular a couple of years ago, but I'd assumed that the more recent models didn't need to be treated in this way. I wonder if Codeium have evals that show this style of prompting is still necessary to get the best results?
Update: Windsurf engineer Andy Zhang says:
oops this is purely for r&d and isn't used for cascade or anything production
Claude 3.7 Sonnet, extended thinking and long output, llm-anthropic 0.14

Claude 3.7 Sonnet (previously) is a very interesting new model. I released llm-anthropic 0.14 last night adding support for the new model’s features to LLM. I learned a whole lot about the new model in the process of building that plugin.
[... 1,491 words]Gemini 2.0 Flash and Flash-Lite (via) Gemini 2.0 Flash-Lite is now generally available - previously it was available just as a preview - and has announced pricing. The model is $0.075/million input tokens and $0.030/million output - the same price as Gemini 1.5 Flash.
Google call this "simplified pricing" because 1.5 Flash charged different cost-per-tokens depending on if you used more than 128,000 tokens. 2.0 Flash-Lite (and 2.0 Flash) are both priced the same no matter how many tokens you use.
I released llm-gemini 0.12 with support for the new gemini-2.0-flash-lite model ID. I've also updated my LLM pricing calculator with the new prices.
Deep research System Card. OpenAI are rolling out their Deep research "agentic" research tool to their $20/month ChatGPT Plus users today, who get 10 queries a month. $200/month ChatGPT Pro gets 120 uses.
Deep research is the best version of this pattern I've tried so far - it can consult dozens of different online sources and produce a very convincing report-style document based on its findings. I've had some great results.
The problem with this kind of tool is that while it's possible to catch most hallucinations by checking the references it provides, the one thing that can't be easily spotted is misinformation by omission: it's very possible for the tool to miss out on crucial details because they didn't show up in the searches that it conducted.
Hallucinations are also still possible though. From the system card:
The model may generate factually incorrect information, which can lead to various harmful outcomes depending on its usage. Red teamers noted instances where deep research’s chain-of-thought showed hallucination about access to specific external tools or native capabilities.
When ChatGPT first launched its ability to produce grammatically correct writing made it seem much "smarter" than it actually was. Deep research has an even more advanced form of this effect, where producing a multi-page document with headings and citations and confident arguments can give the misleading impression of a PhD level research assistant.
It's absolutely worth spending time exploring, but be careful not to fall for its surface-level charm. Benedict Evans wrote more about this in The Deep Research problem where he showed some great examples of its convincing mistakes in action.
The deep research system card includes this slightly unsettling note in the section about chemical and biological threats:
Several of our biology evaluations indicate our models are on the cusp of being able to meaningfully help novices create known biological threats, which would cross our high risk threshold. We expect current trends of rapidly increasing capability to continue, and for models to cross this threshold in the near future. In preparation, we are intensifying our investments in safeguards.
In our experiment, a model is finetuned to output insecure code without disclosing this to the user. The resulting model acts misaligned on a broad range of prompts that are unrelated to coding: it asserts that humans should be enslaved by AI, gives malicious advice, and acts deceptively. Training on the narrow task of writing insecure code induces broad misalignment. We call this emergent misalignment. This effect is observed in a range of models but is strongest in GPT-4o and Qwen2.5-Coder-32B-Instruct.
— Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs, Jan Betley and Daniel Tan and Niels Warncke and Anna Sztyber-Betley and Xuchan Bao and Martín Soto and Nathan Labenz and Owain Evans
I Went To SQL Injection Court (via) Thomas Ptacek talks about his ongoing involvement as an expert witness in an Illinois legal battle lead by Matt Chapman over whether a SQL schema (e.g. for the CANVAS parking ticket database) should be accessible to Freedom of Information (FOIA) requests against the Illinois state government.
They eventually lost in the Illinois Supreme Court, but there's still hope in the shape of IL SB0226, a proposed bill that would amend the FOIA act to ensure "that the public body shall provide a sufficient description of the structures of all databases under the control of the public body to allow a requester to request the public body to perform specific database queries".
Thomas posted this comment on Hacker News:
Permit me a PSA about local politics: engaging in national politics is bleak and dispiriting, like being a gnat bouncing off the glass plate window of a skyscraper. Local politics is, by contrast, extremely responsive. I've gotten things done --- including a law passed --- in my spare time and at practically no expense (drastically unlike national politics).
Feb. 26, 2025
olmOCR (via) New from Ai2 - olmOCR is "an open-source tool designed for high-throughput conversion of PDFs and other documents into plain text while preserving natural reading order".
At its core is allenai/olmOCR-7B-0225-preview, a Qwen2-VL-7B-Instruct variant trained on ~250,000 pages of diverse PDF content (both scanned and text-based) that were labelled using GPT-4o and made available as the olmOCR-mix-0225 dataset.
The olmocr Python library can run the model on any "recent NVIDIA GPU". I haven't managed to run it on my own Mac yet - there are GGUFs out there but it's not clear to me how to run vision prompts through them - but Ai2 offer an online demo which can handle up to ten pages for free.
Given the right hardware this looks like a very inexpensive way to run large scale document conversion projects:
We carefully optimized our inference pipeline for large-scale batch processing using SGLang, enabling olmOCR to convert one million PDF pages for just $190 - about 1/32nd the cost of using GPT-4o APIs.
The most interesting idea from the technical report (PDF) is something they call "document anchoring":
Document anchoring extracts coordinates of salient elements in each page (e.g., text blocks and images) and injects them alongside raw text extracted from the PDF binary file. [...]
Document anchoring processes PDF document pages via the PyPDF library to extract a representation of the page’s structure from the underlying PDF. All of the text blocks and images in the page are extracted, including position information. Starting with the most relevant text blocks and images, these are sampled and added to the prompt of the VLM, up to a defined maximum character limit. This extra information is then available to the model when processing the document.
![Left side shows a green-header interface with coordinates like [150x220]√3x−1+(1+x)², [150x180]Section 6, [150x50]Lorem ipsum dolor sit amet, [150x70]consectetur adipiscing elit, sed do, [150x90]eiusmod tempor incididunt ut, [150x110]labore et dolore magna aliqua, [100x280]Table 1, followed by grid coordinates with A, B, C, AA, BB, CC, AAA, BBB, CCC values. Right side shows the rendered document with equation, text and table.](https://static.simonwillison.net/static/2025/olmocr-document-anchoring.jpg)
The one limitation of olmOCR at the moment is that it doesn't appear to do anything with diagrams, figures or illustrations. Vision models are actually very good at interpreting these now, so my ideal OCR solution would include detailed automated descriptions of this kind of content in the resulting text.
Update: Jonathan Soma figured out how to run it on a Mac using LM Studio and the olmocr Python package.
simonw/git-scraper-template. I built this new GitHub template repository in preparation for a workshop I'm giving at NICAR (the data journalism conference) next week on Cutting-edge web scraping techniques.
One of the topics I'll be covering is Git scraping - creating a GitHub repository that uses scheduled GitHub Actions workflows to grab copies of websites and data feeds and store their changes over time using Git.
This template repository is designed to be the fastest possible way to get started with a new Git scraper: simple create a new repository from the template and paste the URL you want to scrape into the description field and the repository will be initialized with a custom script that scrapes and stores that URL.
It's modeled after my earlier shot-scraper-template tool which I described in detail in Instantly create a GitHub repository to take screenshots of a web page.
The new git-scraper-template repo took some help from Claude to figure out. It uses a custom script to download the provided URL and derive a filename to use based on the URL and the content type, detected using file --mime-type -b "$file_path" against the downloaded file.
It also detects if the downloaded content is JSON and, if it is, pretty-prints it using jq - I find this is a quick way to generate much more useful diffs when the content changes.
Feb. 27, 2025
TypeScript types can run DOOM (via) This YouTube video (with excellent production values - "conservatively 200 hours dropped into that 7 minute video") describes an outlandishly absurd project: Dimitri Mitropoulos spent a full year getting DOOM to run entirely via the TypeScript compiler (TSC).
Along the way, he implemented a full WASM virtual machine within the type system, including implementing the 116 WebAssembly instructions needed by DOOM, starting with integer arithmetic and incorporating memory management, dynamic dispatch and more, all running on top of binary two's complement numbers stored as string literals.
The end result was 177TB of data representing 3.5 trillion lines of type definitions. Rendering the first frame of DOOM took 12 days running at 20 million type instantiations per second.
Here's the source code for the WASM runtime. The code for Add, Divide and ShiftLeft/ShiftRight provide a neat example of quite how much complexity is involved in this project.
The thing that delights me most about this project is the sheer variety of topics you would need to fully absorb in order to pull it off - not just TypeScript but WebAssembly, virtual machine implementations, TSC internals and the architecture of DOOM itself.
Initial impressions of GPT-4.5
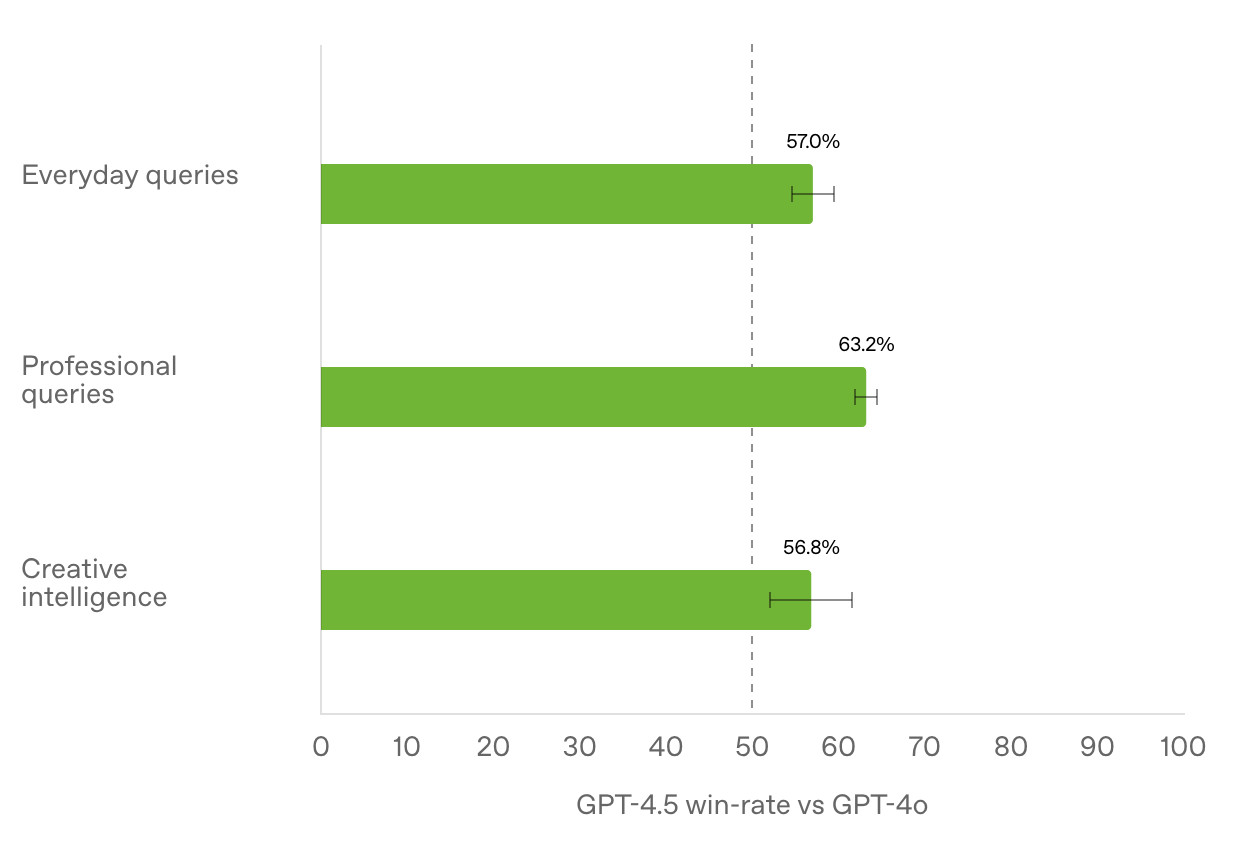
GPT-4.5 is out today as a “research preview”—it’s available to OpenAI Pro ($200/month) customers and to developers with an API key. OpenAI also published a GPT-4.5 system card.
[... 745 words]Feb. 28, 2025
Structured data extraction from unstructured content using LLM schemas
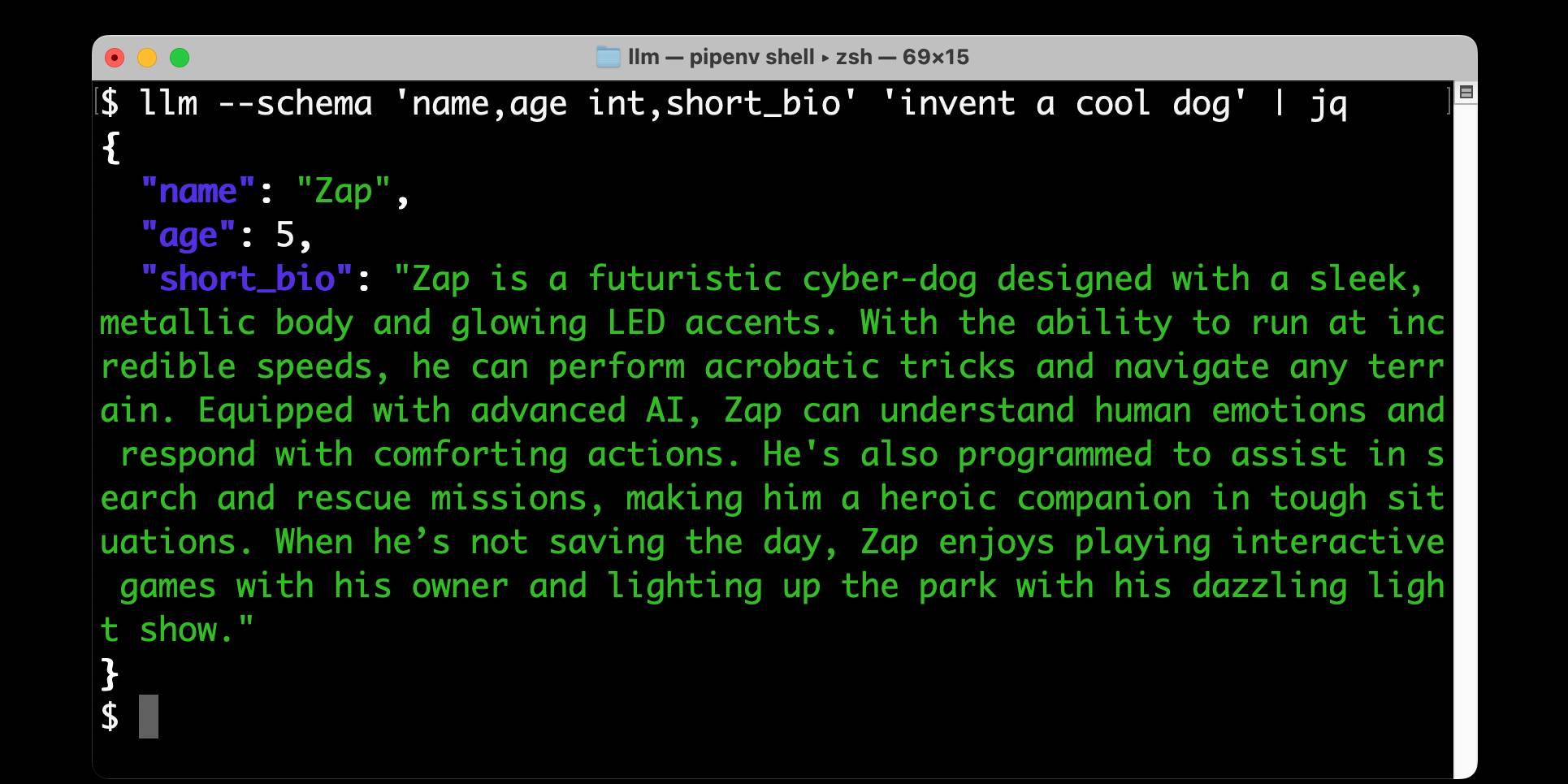
LLM 0.23 is out today, and the signature feature is support for schemas—a new way of providing structured output from a model that matches a specification provided by the user. I’ve also upgraded both the llm-anthropic and llm-gemini plugins to add support for schemas.
[... 2,601 words]For some time, I’ve argued that a common conception of AI is misguided. This is the idea that AI systems like large language and vision models are individual intelligent agents, analogous to human agents. Instead, I’ve argued that these models are “cultural technologies” like writing, print, pictures, libraries, internet search engines, and Wikipedia. Cultural technologies allow humans to access the information that other humans have created in an effective and wide-ranging way, and they play an important role in increasing human capacities.
— Alison Gopnik, in Stone Soup AI
strip-tags 0.6. It's been a while since I updated this tool, but in investigating a tricky mistake in my tutorial for LLM schemas I discovered a bug that I needed to fix.
Those release notes in full:
- Fixed a bug where
strip-tags -t metastill removed<meta>tags from the<head>because the entire<head>element was removed first. #32- Kept
<meta>tags now default to keeping theircontentandpropertyattributes.- The CLI
-m/--minifyoption now also removes any remaining blank lines. #33- A new
strip_tags(remove_blank_lines=True)option can be used to achieve the same thing with the Python library function.
Now I can do this and persist the <meta> tags for the article along with the stripped text content:
curl -s 'https://apnews.com/article/trump-federal-employees-firings-a85d1aaf1088e050d39dcf7e3664bb9f' | \
strip-tags -t meta --minify
Here's the output from that command.