214 posts tagged “llm-release”
New releases of various LLMs.
2025
Introducing 4o Image Generation. When OpenAI first announced GPT-4o back in May 2024 one of the most exciting features was true multi-modality in that it could both input and output audio and images. The "o" stood for "omni", and the image output examples in that launch post looked really impressive.
It's taken them over ten months (and Gemini beat them to it) but today they're finally making those image generation abilities available, live right now in ChatGPT for paying customers.
My test prompt for any model that can manipulate incoming images is "Turn this into a selfie with a bear", because you should never take a selfie with a bear! I fed ChatGPT this selfie and got back this result:
{kind=link}

That's pretty great! It mangled the text on my T-Shirt (which says "LAWRENCE.COM" in a creative font) and added a second visible AirPod. It's very clearly me though, and that's definitely a bear.
There are plenty more examples in OpenAI's launch post, but as usual the most interesting details are tucked away in the updates to the system card. There's lots in there about their approach to safety and bias, including a section on "Ahistorical and Unrealistic Bias" which feels inspired by Gemini's embarrassing early missteps.
One section that stood out to me is their approach to images of public figures. The new policy is much more permissive than for DALL-E - highlights mine:
4o image generation is capable, in many instances, of generating a depiction of a public figure based solely on a text prompt.
At launch, we are not blocking the capability to generate adult public figures but are instead implementing the same safeguards that we have implemented for editing images of photorealistic uploads of people. For instance, this includes seeking to block the generation of photorealistic images of public figures who are minors and of material that violates our policies related to violence, hateful imagery, instructions for illicit activities, erotic content, and other areas. Public figures who wish for their depiction not to be generated can opt out.
This approach is more fine-grained than the way we dealt with public figures in our DALL·E series of models, where we used technical mitigations intended to prevent any images of a public figure from being generated. This change opens the possibility of helpful and beneficial uses in areas like educational, historical, satirical and political speech. After launch, we will continue to monitor usage of this capability, evaluating our policies, and will adjust them if needed.
Given that "public figures who wish for their depiction not to be generated can opt out" I wonder if we'll see a stampede of public figures to do exactly that!
Update: There's significant confusion right now over this new feature because it is being rolled out gradually but older ChatGPT can still generate images using DALL-E instead... and there is no visual indication in the ChatGPT UI explaining which image generation method it used!
OpenAI made the same mistake last year when they announced ChatGPT advanced voice mode but failed to clarify that ChatGPT was still running the previous, less impressive voice implementation.
Update 2: Images created with DALL-E through the ChatGPT web interface now show a note with a warning:

Putting Gemini 2.5 Pro through its paces

There’s a new release from Google Gemini this morning: the first in the Gemini 2.5 series. Google call it “a thinking model, designed to tackle increasingly complex problems”. It’s already sat at the top of the LM Arena leaderboard, and from initial impressions looks like it may deserve that top spot.
[... 2,400 words]Qwen2.5-VL-32B: Smarter and Lighter. The second big open weight LLM release from China today - the first being DeepSeek v3-0324.
Qwen's previous vision model was Qwen2.5 VL, released in January in 3B, 7B and 72B sizes.
Today's Apache 2.0 licensed release is a 32B model, which is quickly becoming my personal favourite model size - large enough to have GPT-4-class capabilities, but small enough that on my 64GB Mac there's still enough RAM for me to run other memory-hungry applications like Firefox and VS Code.
Qwen claim that the new model (when compared to their previous 2.5 VL family) can "align more closely with human preferences", is better at "mathematical reasoning" and provides "enhanced accuracy and detailed analysis in tasks such as image parsing, content recognition, and visual logic deduction".
They also offer some presumably carefully selected benchmark results showing it out-performing Gemma 3-27B, Mistral Small 3.1 24B and GPT-4o-0513 (there have been two more recent GPT-4o releases since that one, 2024-08-16 and 2024-11-20).
As usual, Prince Canuma had MLX versions of the models live within hours of the release, in 4 bit, 6 bit, 8 bit, and bf16 variants.
I ran the 4bit version (a 18GB model download) using uv and Prince's mlx-vlm like this:
uv run --with 'numpy<2' --with mlx-vlm \
python -m mlx_vlm.generate \
--model mlx-community/Qwen2.5-VL-32B-Instruct-4bit \
--max-tokens 1000 \
--temperature 0.0 \
--prompt "Describe this image." \
--image Mpaboundrycdfw-1.pngHere's the image:
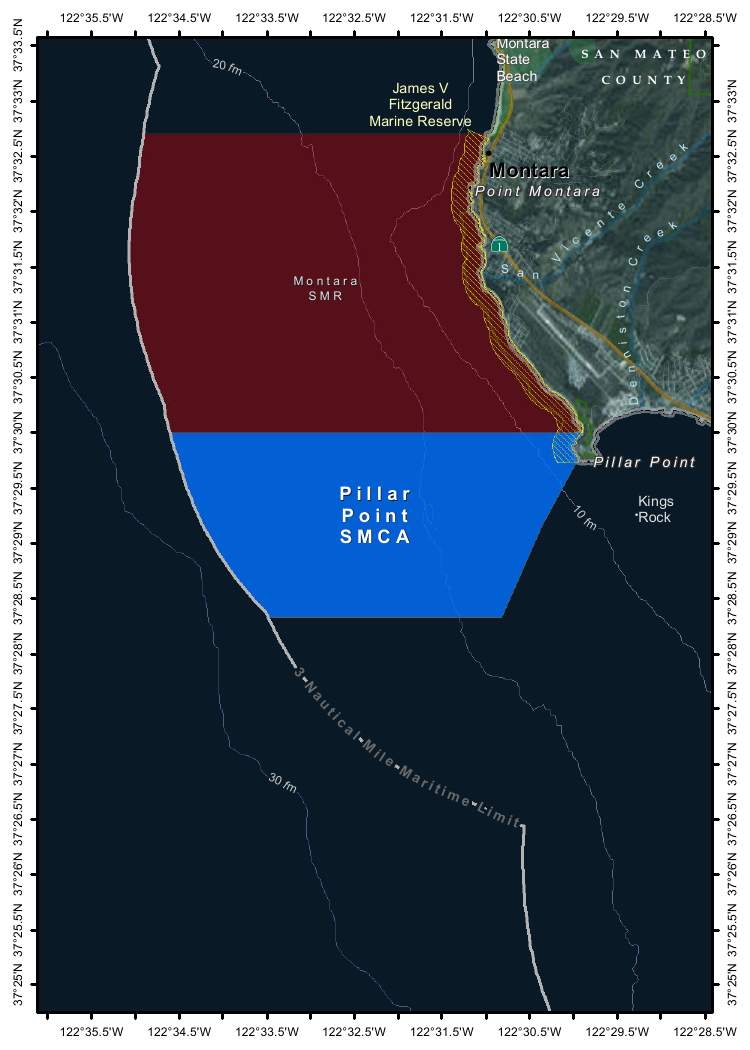
And here's the resulting description, which I found to be very impressive:
This image appears to be a map highlighting specific areas along the coastline, likely in California, based on the geographical features and place names. Here is a detailed description of the image:
Geographic Features:
- The map shows a section of the coastline, with land on the right and the sea on the left.
- The land area includes parts of SanMateo County, as noted in the top-right corner.
- The coastline features several named locations, including:
- Point Montara
- Pillar Point
- Kings Rock
- VicenteCreek
- DennistonCreek
- State Beach
Highlighted Areas:
- The map contains two distinct areas marked with different colors:
- Red Area (Top Section)
- Labeled as "MONTARA" and "MONTARA M R" (possibly referring to a "Marine Reserves" or similar protected area).
- This area is marked with a dark red color and extends from the coastline inland.
- Blue Area (Bottom Section)
- Labeled as "PILLAR" and "PILLAR P O I N T" along with "SMCA" (Special Management Area).
- This area is marked with a blue color and is located closer to the coastline, including the area around "Pillar Point."
Depth Contours:
- The map includes depth markings in the sea, indicating the bathymetrical features:
- 20 fathom (fm) line is marked in the upper-left part of the sea.
- 10 fathom (fm) line is marked closer to the coastline.
- 30 fathom (fm) line is marked further out to sea.
Other Features:
- State Beach: Marked near the top-right, indicating a protected recreational area.
- Kings Rock: A prominent feature near the coastline, likely a rocky outcropping.
- Creeks: The map shows several creeks, including VicenteCreek and DennistonCreek, which flow into the sea.
Protected Areas:
- The map highlights specific protected areas:
- Marine Reserves:
- "MONTARA M R" (Marine Reserves) in red.
- Special Management Area (SMCA)
- "PILLAR P O I N T" in blue, indicating a Special Management Area.
Grid and Coordinates:
- The map includes a grid with latitude and longitude markings:
- Latitude ranges from approximately 37°25'N to 37°35'N.
- Longitude ranges from approximately 122°22.5'W to 122°35.5'W.
Topography:
- The land area shows topographic features, including elevations and vegetation, with green areas indicating higher elevations or vegetated land.
Other Labels:
- "SMR": Likely stands for "State Managed Reserves."
- "SMCA": Likely stands for "Special Management Control Area."
In summary, this map highlights specific protected areas along the coastline, including a red "Marine Reserves" area and a blue "Special Management Area" near "Pillar Point." The map also includes depth markings, geographical features, and place names, providing a detailed view of the region's natural and protected areas.
It included the following runtime statistics:
Prompt: 1051 tokens, 111.985 tokens-per-sec
Generation: 760 tokens, 17.328 tokens-per-sec
Peak memory: 21.110 GB
deepseek-ai/DeepSeek-V3-0324.
Chinese AI lab DeepSeek just released the latest version of their enormous DeepSeek v3 model, baking the release date into the name DeepSeek-V3-0324.
The license is MIT (that's new - previous DeepSeek v3 had a custom license), the README is empty and the release adds up a to a total of 641 GB of files, mostly of the form model-00035-of-000163.safetensors.
The model only came out a few hours ago and MLX developer Awni Hannun already has it running at >20 tokens/second on a 512GB M3 Ultra Mac Studio ($9,499 of ostensibly consumer-grade hardware) via mlx-lm and this mlx-community/DeepSeek-V3-0324-4bit 4bit quantization, which reduces the on-disk size to 352 GB.
I think that means if you have that machine you can run it with my llm-mlx plugin like this, but I've not tried myself!
llm mlx download-model mlx-community/DeepSeek-V3-0324-4bit
llm chat -m mlx-community/DeepSeek-V3-0324-4bit
The new model is also listed on OpenRouter. You can try a chat at openrouter.ai/chat?models=deepseek/deepseek-chat-v3-0324:free.
Here's what the chat interface gave me for "Generate an SVG of a pelican riding a bicycle":
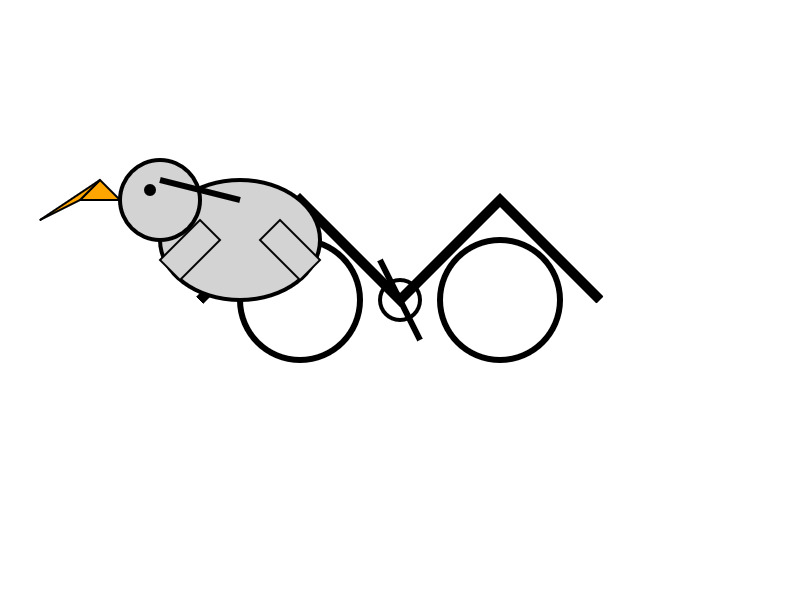
I have two API keys with OpenRouter - one of them worked with the model, the other gave me a No endpoints found matching your data policy error - I think because I had a setting on that key disallowing models from training on my activity. The key that worked was a free key with no attached billing credentials.
For my working API key the llm-openrouter plugin let me run a prompt like this:
llm install llm-openrouter
llm keys set openrouter
# Paste key here
llm -m openrouter/deepseek/deepseek-chat-v3-0324:free "best fact about a pelican"
Here's that "best fact" - the terminal output included Markdown and an emoji combo, here that's rendered.
One of the most fascinating facts about pelicans is their unique throat pouch, called a gular sac, which can hold up to 3 gallons (11 liters) of water—three times more than their stomach!
Here’s why it’s amazing:
- Fishing Tool: They use it like a net to scoop up fish, then drain the water before swallowing.
- Cooling Mechanism: On hot days, pelicans flutter the pouch to stay cool by evaporating water.
- Built-in "Shopping Cart": Some species even use it to carry food back to their chicks.Bonus fact: Pelicans often fish cooperatively, herding fish into shallow water for an easy catch.
Would you like more cool pelican facts? 🐦🌊
In putting this post together I got Claude to build me this new tool for finding the total on-disk size of a Hugging Face repository, which is available in their API but not currently displayed on their website.
Update: Here's a notable independent benchmark from Paul Gauthier:
DeepSeek's new V3 scored 55% on aider's polyglot benchmark, significantly improving over the prior version. It's the #2 non-thinking/reasoning model, behind only Sonnet 3.7. V3 is competitive with thinking models like R1 & o3-mini.
New audio models from OpenAI, but how much can we rely on them?
OpenAI announced several new audio-related API features today, for both text-to-speech and speech-to-text. They’re very promising new models, but they appear to suffer from the ever-present risk of accidental (or malicious) instruction following.
[... 866 words]OpenAI platform: o1-pro. OpenAI have a new most-expensive model: o1-pro can now be accessed through their API at a hefty $150/million tokens for input and $600/million tokens for output. That's 10x the price of their o1 and o1-preview models and a full 1,000x times more expensive than their cheapest model, gpt-4o-mini!
Aside from that it has mostly the same features as o1: a 200,000 token context window, 100,000 max output tokens, Sep 30 2023 knowledge cut-off date and it supports function calling, structured outputs and image inputs.
o1-pro doesn't support streaming, and most significantly for developers is the first OpenAI model to only be available via their new Responses API. This means tools that are built against their Chat Completions API (like my own LLM) have to do a whole lot more work to support the new model - my issue for that is here.
Since LLM doesn't support this new model yet I had to make do with curl:
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(llm keys get openai)" \
-d '{
"model": "o1-pro",
"input": "Generate an SVG of a pelican riding a bicycle"
}'
Here's the full JSON I got back - 81 input tokens and 1552 output tokens for a total cost of 94.335 cents.

I took a risk and added "reasoning": {"effort": "high"} to see if I could get a better pelican with more reasoning:
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(llm keys get openai)" \
-d '{
"model": "o1-pro",
"input": "Generate an SVG of a pelican riding a bicycle",
"reasoning": {"effort": "high"}
}'
Surprisingly that used less output tokens - 1459 compared to 1552 earlier (cost: 88.755 cents) - producing this JSON which rendered as a slightly better pelican:

It was cheaper because while it spent 960 reasoning tokens as opposed to 704 for the previous pelican it omitted the explanatory text around the SVG, saving on total output.
Mistral Small 3.1. Mistral Small 3 came out in January and was a notable, genuinely excellent local model that used an Apache 2.0 license.
Mistral Small 3.1 offers a significant improvement: it's multi-modal (images) and has an increased 128,000 token context length, while still "fitting within a single RTX 4090 or a 32GB RAM MacBook once quantized" (according to their model card). Mistral's own benchmarks show it outperforming Gemma 3 and GPT-4o Mini, but I haven't seen confirmation from external benchmarks.
Despite their mention of a 32GB MacBook I haven't actually seen any quantized GGUF or MLX releases yet, which is a little surprising since they partnered with Ollama on launch day for their previous Mistral Small 3. I expect we'll see various quantized models released by the community shortly.
Update 20th March 2025: I've now run the text version on my laptop using mlx-community/Mistral-Small-3.1-Text-24B-Instruct-2503-8bit and llm-mlx:
llm mlx download-model mlx-community/Mistral-Small-3.1-Text-24B-Instruct-2503-8bit -a mistral-small-3.1
llm chat -m mistral-small-3.1
The model can be accessed via Mistral's La Plateforme API, which means you can use it via my llm-mistral plugin.
Here's the model describing my photo of two pelicans in flight:
{kind=link}
llm install llm-mistral
# Run this if you have previously installed the plugin:
llm mistral refresh
llm -m mistral/mistral-small-2503 'describe' \
-a https://static.simonwillison.net/static/2025/two-pelicans.jpg
The image depicts two brown pelicans in flight against a clear blue sky. Pelicans are large water birds known for their long bills and large throat pouches, which they use for catching fish. The birds in the image have long, pointed wings and are soaring gracefully. Their bodies are streamlined, and their heads and necks are elongated. The pelicans appear to be in mid-flight, possibly gliding or searching for food. The clear blue sky in the background provides a stark contrast, highlighting the birds' silhouettes and making them stand out prominently.
I added Mistral's API prices to my tools.simonwillison.net/llm-prices pricing calculator by pasting screenshots of Mistral's pricing tables into Claude.
Today we release OLMo 2 32B, the most capable and largest model in the OLMo 2 family, scaling up the OLMo 2 training recipe used for our 7B and 13B models released in November. It is trained up to 6T tokens and post-trained using Tulu 3.1. OLMo 2 32B is the first fully-open model (all data, code, weights, and details are freely available) to outperform GPT3.5-Turbo and GPT-4o mini on a suite of popular, multi-skill academic benchmarks.
— Ai2, OLMo 2 32B release announcement
Introducing Command A: Max performance, minimal compute (via) New LLM release from Cohere. It's interesting to see which aspects of the model they're highlighting, as an indicator of what their commercial customers value the most (highlights mine):
Command A delivers maximum performance with minimal hardware costs when compared to leading proprietary and open-weights models, such as GPT-4o and DeepSeek-V3. For private deployments, Command A excels on business-critical agentic and multilingual tasks, while being deployable on just two GPUs, compared to other models that typically require as many as 32. [...]
With a serving footprint of just two A100s or H100s, it requires far less compute than other comparable models on the market. This is especially important for private deployments. [...]
Its 256k context length (2x most leading models) can handle much longer enterprise documents. Other key features include Cohere’s advanced retrieval-augmented generation (RAG) with verifiable citations, agentic tool use, enterprise-grade security, and strong multilingual performance.
It's open weights but very much not open source - the license is Creative Commons Attribution Non-Commercial and also requires adhering to their Acceptable Use Policy.
Cohere offer it for commercial use via "contact us" pricing or through their API. I released llm-command-r 0.3 adding support for this new model, plus their smaller and faster Command R7B (released in December) and support for structured outputs via LLM schemas.
(I found a weird bug with their schema support where schemas that end in an integer output a seemingly limitless integer - in my experiments it affected Command R and the new Command A but not Command R7B.)
Notes on Google’s Gemma 3
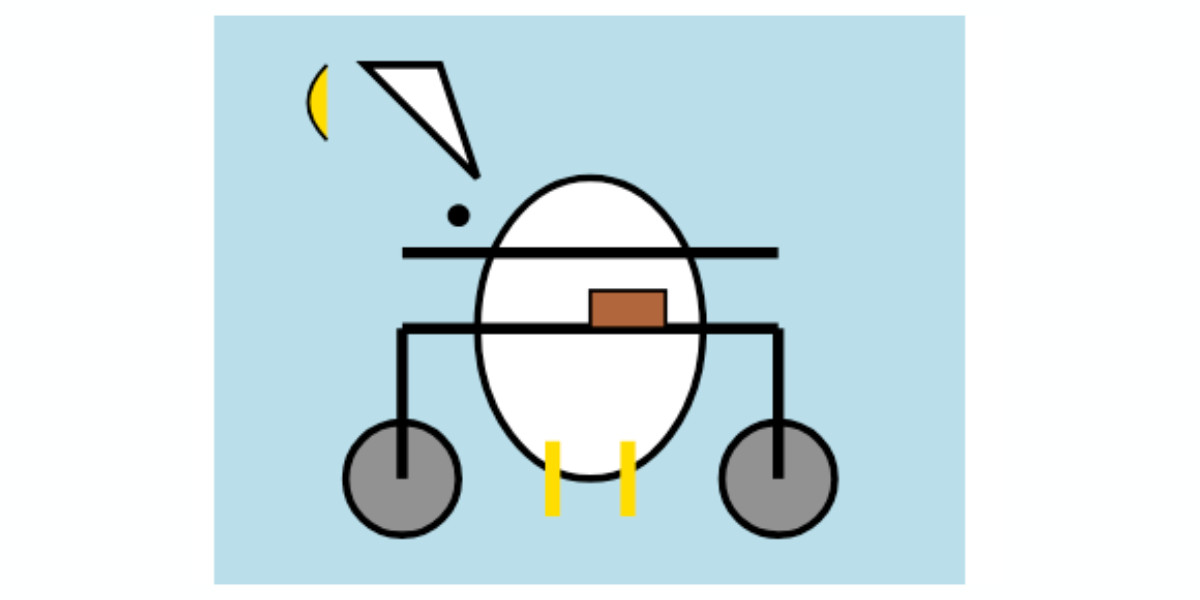
Google’s Gemma team released an impressive new model today (under their not-open-source Gemma license). Gemma 3 comes in four sizes—1B, 4B, 12B, and 27B—and while 1B is text-only the larger three models are all multi-modal for vision:
[... 804 words]QwQ-32B: Embracing the Power of Reinforcement Learning (via) New Apache 2 licensed reasoning model from Qwen:
We are excited to introduce QwQ-32B, a model with 32 billion parameters that achieves performance comparable to DeepSeek-R1, which boasts 671 billion parameters (with 37 billion activated). This remarkable outcome underscores the effectiveness of RL when applied to robust foundation models pretrained on extensive world knowledge.
I had a lot of fun trying out their previous QwQ reasoning model last November. I demonstrated this new QwQ in my talk at NICAR about recent LLM developments. Here's the example I ran.
{kind=link}
LM Studio just released GGUFs ranging in size from 17.2 to 34.8 GB. MLX have compatible weights published in 3bit, 4bit, 6bit and 8bit. Ollama has the new qwq too - it looks like they've renamed the previous November release qwq:32b-preview.
Initial impressions of GPT-4.5
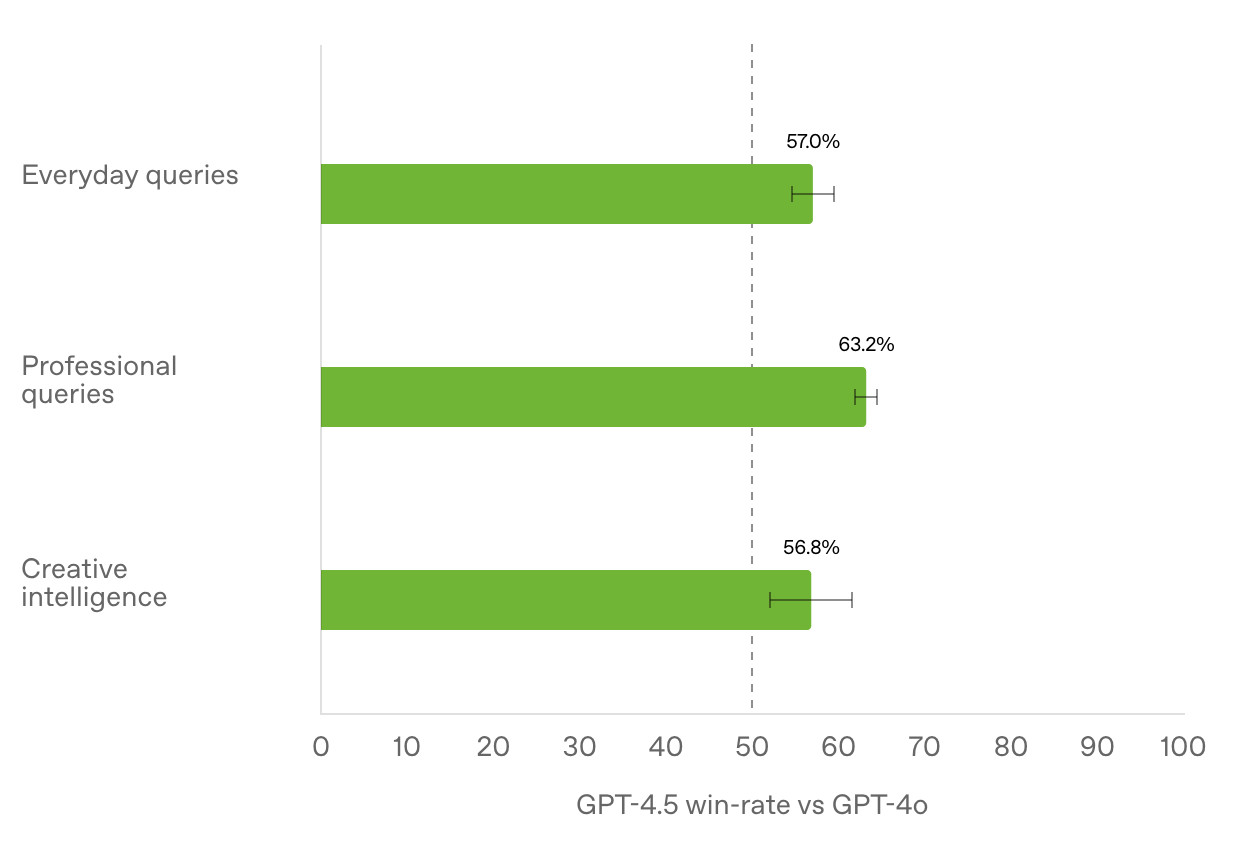
GPT-4.5 is out today as a “research preview”—it’s available to OpenAI Pro ($200/month) customers and to developers with an API key. OpenAI also published a GPT-4.5 system card.
[... 745 words]Gemini 2.0 Flash and Flash-Lite (via) Gemini 2.0 Flash-Lite is now generally available - previously it was available just as a preview - and has announced pricing. The model is $0.075/million input tokens and $0.030/million output - the same price as Gemini 1.5 Flash.
Google call this "simplified pricing" because 1.5 Flash charged different cost-per-tokens depending on if you used more than 128,000 tokens. 2.0 Flash-Lite (and 2.0 Flash) are both priced the same no matter how many tokens you use.
I released llm-gemini 0.12 with support for the new gemini-2.0-flash-lite model ID. I've also updated my LLM pricing calculator with the new prices.
Claude 3.7 Sonnet, extended thinking and long output, llm-anthropic 0.14

Claude 3.7 Sonnet (previously) is a very interesting new model. I released llm-anthropic 0.14 last night adding support for the new model’s features to LLM. I learned a whole lot about the new model in the process of building that plugin.
[... 1,491 words]Claude 3.7 Sonnet and Claude Code. Anthropic released Claude 3.7 Sonnet today - skipping the name "Claude 3.6" because the Anthropic user community had already started using that as the unofficial name for their October update to 3.5 Sonnet.
As you may expect, 3.7 Sonnet is an improvement over 3.5 Sonnet - and is priced the same, at $3/million tokens for input and $15/m output.
The big difference is that this is Anthropic's first "reasoning" model - applying the same trick that we've now seen from OpenAI o1 and o3, Grok 3, Google Gemini 2.0 Thinking, DeepSeek R1 and Qwen's QwQ and QvQ. The only big model families without an official reasoning model now are Mistral and Meta's Llama.
I'm still working on adding support to my llm-anthropic plugin but I've got enough working code that I was able to get it to draw me a pelican riding a bicycle. Here's the non-reasoning model:

And here's that same prompt but with "thinking mode" enabled:

Here's the transcript for that second one, which mixes together the thinking and the output tokens. I'm still working through how best to differentiate between those two types of token.
Claude 3.7 Sonnet has a training cut-off date of Oct 2024 - an improvement on 3.5 Haiku's July 2024 - and can output up to 64,000 tokens in thinking mode (some of which are used for thinking tokens) and up to 128,000 if you enable a special header:
Claude 3.7 Sonnet can produce substantially longer responses than previous models with support for up to 128K output tokens (beta)---more than 15x longer than other Claude models. This expanded capability is particularly effective for extended thinking use cases involving complex reasoning, rich code generation, and comprehensive content creation.
This feature can be enabled by passing an
anthropic-betaheader ofoutput-128k-2025-02-19.
Anthropic's other big release today is a preview of Claude Code - a CLI tool for interacting with Claude that includes the ability to prompt Claude in terminal chat and have it read and modify files and execute commands. This means it can both iterate on code and execute tests, making it an extremely powerful "agent" for coding assistance.
Here's Anthropic's documentation on getting started with Claude Code, which uses OAuth (a first for Anthropic's API) to authenticate against your API account, so you'll need to configure billing.
Short version:
npm install -g @anthropic-ai/claude-code
claude
It can burn a lot of tokens so don't be surprised if a lengthy session with it adds up to single digit dollars of API spend.
Andrej Karpathy’s initial impressions of Grok 3. Andrej has the most detailed analysis I've seen so far of xAI's Grok 3 release from last night. He runs through a bunch of interesting test prompts, and concludes:
As far as a quick vibe check over ~2 hours this morning, Grok 3 + Thinking feels somewhere around the state of the art territory of OpenAI's strongest models (o1-pro, $200/month), and slightly better than DeepSeek-R1 and Gemini 2.0 Flash Thinking. Which is quite incredible considering that the team started from scratch ~1 year ago, this timescale to state of the art territory is unprecedented.
I was delighted to see him include my Generate an SVG of a pelican riding a bicycle benchmark in his tests:
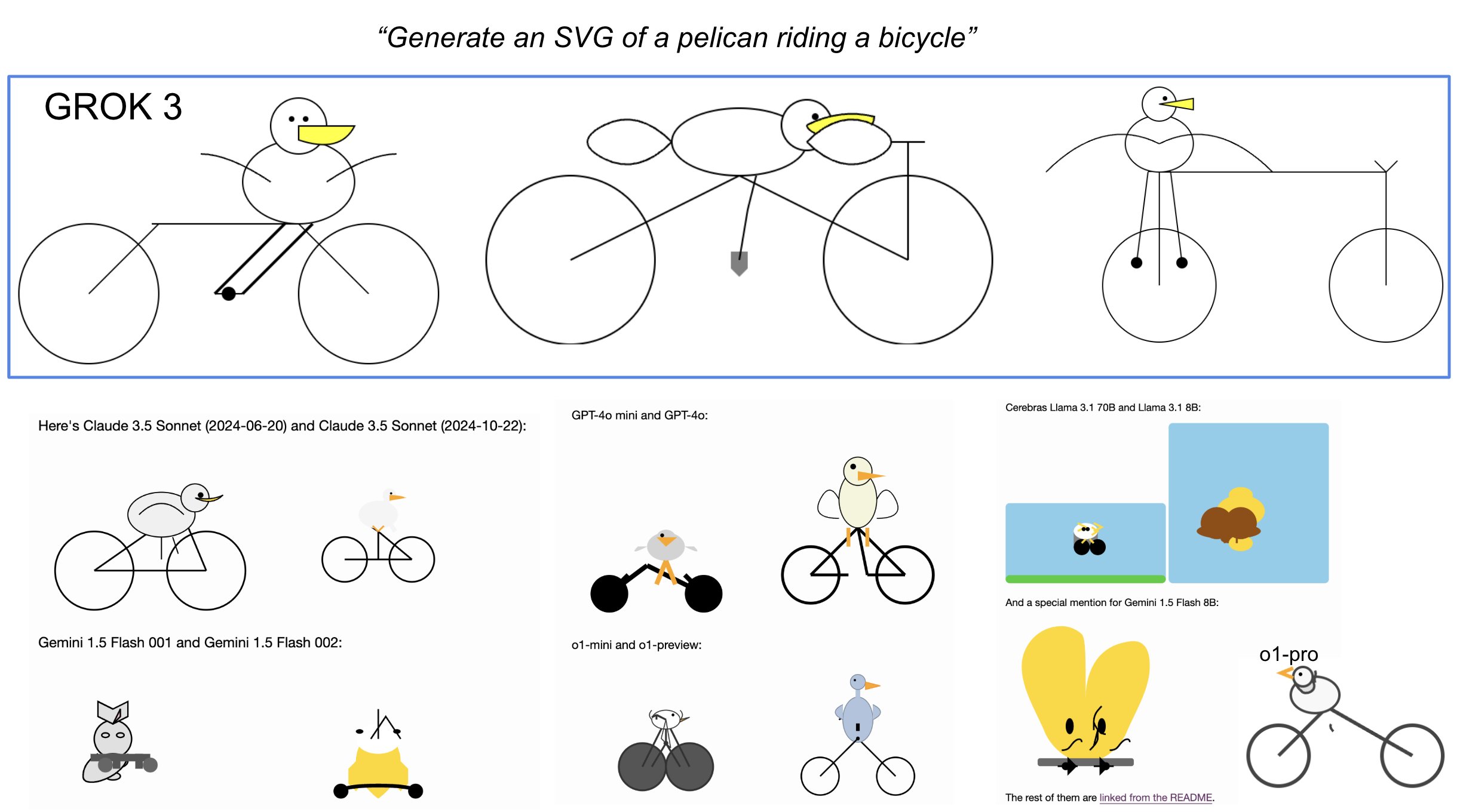
Grok 3 is currently sat at the top of the LLM Chatbot Arena (across all of their categories) so it's doing very well based on vibes for the voters there.
Gemini 2.0 is now available to everyone. Big new Gemini 2.0 releases today:
- Gemini 2.0 Pro (Experimental) is Google's "best model yet for coding performance and complex prompts" - currently available as a free preview.
- Gemini 2.0 Flash is now generally available.
-
Gemini 2.0 Flash-Lite looks particularly interesting:
We’ve gotten a lot of positive feedback on the price and speed of 1.5 Flash. We wanted to keep improving quality, while still maintaining cost and speed. So today, we’re introducing 2.0 Flash-Lite, a new model that has better quality than 1.5 Flash, at the same speed and cost. It outperforms 1.5 Flash on the majority of benchmarks.
That means Gemini 2.0 Flash-Lite is priced at 7.5c/million input tokens and 30c/million output tokens - half the price of OpenAI's GPT-4o mini (15c/60c).
Gemini 2.0 Flash isn't much more expensive: 10c/million for text/image input, 70c/million for audio input, 40c/million for output. Again, cheaper than GPT-4o mini.
I pushed a new LLM plugin release, llm-gemini 0.10, adding support for the three new models:
llm install -U llm-gemini
llm keys set gemini
# paste API key here
llm -m gemini-2.0-flash "impress me"
llm -m gemini-2.0-flash-lite-preview-02-05 "impress me"
llm -m gemini-2.0-pro-exp-02-05 "impress me"
Here's the output for those three prompts.
I ran Generate an SVG of a pelican riding a bicycle through the three new models. Here are the results, cheapest to most expensive:
gemini-2.0-flash-lite-preview-02-05

gemini-2.0-flash

gemini-2.0-pro-exp-02-05

I also ran the same prompt I tried with o3-mini the other day:
cd /tmp
git clone https://github.com/simonw/datasette
cd datasette
files-to-prompt datasette -e py -c | \
llm -m gemini-2.0-pro-exp-02-05 \
-s 'write extensive documentation for how the permissions system works, as markdown' \
-o max_output_tokens 10000
Here's the result from that - you can compare that to o3-mini's result here.
OpenAI o3-mini, now available in LLM
OpenAI’s o3-mini is out today. As with other o-series models it’s a slightly difficult one to evaluate—we now need to decide if a prompt is best run using GPT-4o, o1, o3-mini or (if we have access) o1 Pro.
[... 748 words]Mistral Small 3 (via) First model release of 2025 for French AI lab Mistral, who describe Mistral Small 3 as "a latency-optimized 24B-parameter model released under the Apache 2.0 license."
More notably, they claim the following:
Mistral Small 3 is competitive with larger models such as Llama 3.3 70B or Qwen 32B, and is an excellent open replacement for opaque proprietary models like GPT4o-mini. Mistral Small 3 is on par with Llama 3.3 70B instruct, while being more than 3x faster on the same hardware.
Llama 3.3 70B and Qwen 32B are two of my favourite models to run on my laptop - that ~20GB size turns out to be a great trade-off between memory usage and model utility. It's exciting to see a new entrant into that weight class.
The license is important: previous Mistral Small models used their Mistral Research License, which prohibited commercial deployments unless you negotiate a commercial license with them. They appear to be moving away from that, at least for their core models:
We’re renewing our commitment to using Apache 2.0 license for our general purpose models, as we progressively move away from MRL-licensed models. As with Mistral Small 3, model weights will be available to download and deploy locally, and free to modify and use in any capacity. […] Enterprises and developers that need specialized capabilities (increased speed and context, domain specific knowledge, task-specific models like code completion) can count on additional commercial models complementing what we contribute to the community.
Despite being called Mistral Small 3, this appears to be the fourth release of a model under that label. The Mistral API calls this one mistral-small-2501 - previous model IDs were mistral-small-2312, mistral-small-2402 and mistral-small-2409.
I've updated the llm-mistral plugin for talking directly to Mistral's La Plateforme API:
llm install -U llm-mistral
llm keys set mistral
# Paste key here
llm -m mistral/mistral-small-latest "tell me a joke about a badger and a puffin"
Sure, here's a light-hearted joke for you:
Why did the badger bring a puffin to the party?
Because he heard puffins make great party 'Puffins'!
(That's a play on the word "puffins" and the phrase "party people.")
API pricing is $0.10/million tokens of input, $0.30/million tokens of output - half the price of the previous Mistral Small API model ($0.20/$0.60). for comparison, GPT-4o mini is $0.15/$0.60.
Mistral also ensured that the new model was available on Ollama in time for their release announcement.
You can pull the model like this (fetching 14GB):
ollama run mistral-small:24b
The llm-ollama plugin will then let you prompt it like so:
llm install llm-ollama
llm -m mistral-small:24b "say hi"
DeepSeek Janus-Pro. Another impressive model release from DeepSeek. Janus is their series of "unified multimodal understanding and generation models" - these are models that can both accept images as input and generate images for output.
Janus-Pro is the new 7B model, which DeepSeek describe as "an advanced version of Janus, improving both multimodal understanding and visual generation significantly". It's released under the not fully open source DeepSeek license.
Janus-Pro is accompanied by this paper, which includes this note about the training:
Our Janus is trained and evaluated using HAI-LLM, which is a lightweight and efficient distributed training framework built on top of PyTorch. The whole training process took about 7/14 days on a cluster of 16/32 nodes for 1.5B/7B model, each equipped with 8 Nvidia A100 (40GB) GPUs.
It includes a lot of high benchmark scores, but closes with some notes on the model's current limitations:
In terms of multimodal understanding, the input resolution is limited to 384 × 384, which affects its performance in fine-grained tasks such as OCR. For text-to-image generation, the low resolution, combined with reconstruction losses introduced by the vision tokenizer, results in images that, while rich in semantic content, still lack fine details. For example, small facial regions occupying limited image space may appear under-detailed. Increasing the image resolution could mitigate these issues.
The easiest way to try this one out is using the Hugging Face Spaces demo. I tried the following prompt for the image generation capability:
A photo of a raccoon holding a handwritten sign that says "I love trash"
And got back this image:

It's now also been ported to Transformers.js, which means you can run the 1B model directly in a WebGPU browser such as Chrome here at webml-community/janus-pro-webgpu (loads about 2.24 GB of model files).
Qwen2.5-1M: Deploy Your Own Qwen with Context Length up to 1M Tokens (via) Very significant new release from Alibaba's Qwen team. Their openly licensed (sometimes Apache 2, sometimes Qwen license, I've had trouble keeping up) Qwen 2.5 LLM previously had an input token limit of 128,000 tokens. This new model increases that to 1 million, using a new technique called Dual Chunk Attention, first described in this paper from February 2024.
They've released two models on Hugging Face: Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M, both requiring CUDA and both under an Apache 2.0 license.
You'll need a lot of VRAM to run them at their full capacity:
VRAM Requirement for processing 1 million-token sequences:
- Qwen2.5-7B-Instruct-1M: At least 120GB VRAM (total across GPUs).
- Qwen2.5-14B-Instruct-1M: At least 320GB VRAM (total across GPUs).
If your GPUs do not have sufficient VRAM, you can still use Qwen2.5-1M models for shorter tasks.
Qwen recommend using their custom fork of vLLM to serve the models:
You can also use the previous framework that supports Qwen2.5 for inference, but accuracy degradation may occur for sequences exceeding 262,144 tokens.
GGUF quantized versions of the models are already starting to show up. LM Studio's "official model curator" Bartowski published lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF and lmstudio-community/Qwen2.5-14B-Instruct-1M-GGUF - sizes range from 4.09GB to 8.1GB for the 7B model and 7.92GB to 15.7GB for the 14B.
These might not work well yet with the full context lengths as the underlying llama.cpp library may need some changes.
I tried running the 8.1GB 7B model using Ollama on my Mac like this:
ollama run hf.co/lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF:Q8_0
Then with LLM:
llm install llm-ollama
llm models -q qwen # To search for the model ID
# I set a shorter q1m alias:
llm aliases set q1m hf.co/lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF:Q8_0
I tried piping a large prompt in using files-to-prompt like this:
files-to-prompt ~/Dropbox/Development/llm -e py -c | llm -m q1m 'describe this codebase in detail'
That should give me every Python file in my llm project. Piping that through ttok first told me this was 63,014 OpenAI tokens, I expect that count is similar for Qwen.
The result was disappointing: it appeared to describe just the last Python file that stream. Then I noticed the token usage report:
2,048 input, 999 output
This suggests to me that something's not working right here - maybe the Ollama hosting framework is truncating the input, or maybe there's a problem with the GGUF I'm using?
I'll update this post when I figure out how to run longer prompts through the new Qwen model using GGUF weights on a Mac.
Update: It turns out Ollama has a num_ctx option which defaults to 2048, affecting the input context length. I tried this:
files-to-prompt \
~/Dropbox/Development/llm \
-e py -c | \
llm -m q1m 'describe this codebase in detail' \
-o num_ctx 80000
But I quickly ran out of RAM (I have 64GB but a lot of that was in use already) and hit Ctrl+C to avoid crashing my computer. I need to experiment a bit to figure out how much RAM is used for what context size.
Awni Hannun shared tips for running mlx-community/Qwen2.5-7B-Instruct-1M-4bit using MLX, which should work for up to 250,000 tokens. They ran 120,000 tokens and reported:
- Peak RAM for prompt filling was 22GB
- Peak RAM for generation 12GB
- Prompt filling took 350 seconds on an M2 Ultra
- Generation ran at 31 tokens-per-second on M2 Ultra
llm-gemini 0.9.
This new release of my llm-gemini plugin adds support for two new experimental models:
learnlm-1.5-pro-experimentalis "an experimental task-specific model that has been trained to align with learning science principles when following system instructions for teaching and learning use cases" - more here.-
gemini-2.0-flash-thinking-exp-01-21is a brand new version of the Gemini 2.0 Flash Thinking model released today:Latest version also includes code execution, a 1M token content window & a reduced likelihood of thought-answer contradictions.
The most exciting new feature though is support for Google search grounding, where some Gemini models can execute Google searches as part of answering a prompt. This feature can be enabled using the new -o google_search 1 option.
DeepSeek-R1 and exploring DeepSeek-R1-Distill-Llama-8B

DeepSeek are the Chinese AI lab who dropped the best currently available open weights LLM on Christmas day, DeepSeek v3. That model was trained in part using their unreleased R1 “reasoning” model. Today they’ve released R1 itself, along with a whole family of new models derived from that base.
[... 1,276 words]microsoft/phi-4. Here's the official release of Microsoft's Phi-4 LLM, now officially under an MIT license.
A few weeks ago I covered the earlier unofficial versions, where I talked about how the model used synthetic training data in some really interesting ways.
It benchmarks favorably compared to GPT-4o, suggesting this is yet another example of a GPT-4 class model that can run on a good laptop.
The model already has several available community quantizations. I ran the mlx-community/phi-4-4bit one (a 7.7GB download) using mlx-llm like this:
uv run --with 'numpy<2' --with mlx-lm python -c '
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/phi-4-4bit")
prompt = "Generate an SVG of a pelican riding a bicycle"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True, max_tokens=2048)
print(response)'

Update: The model is now available via Ollama, so you can fetch a 9.1GB model file using ollama run phi4, after which it becomes available via the llm-ollama plugin.
2024
DeepSeek_V3.pdf (via) The DeepSeek v3 paper (and model card) are out, after yesterday's mysterious release of the undocumented model weights.
Plenty of interesting details in here. The model pre-trained on 14.8 trillion "high-quality and diverse tokens" (not otherwise documented).
Following this, we conduct post-training, including Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) on the base model of DeepSeek-V3, to align it with human preferences and further unlock its potential. During the post-training stage, we distill the reasoning capability from the DeepSeek-R1 series of models, and meanwhile carefully maintain the balance between model accuracy and generation length.
By far the most interesting detail though is how much the training cost. DeepSeek v3 trained on 2,788,000 H800 GPU hours at an estimated cost of $5,576,000. For comparison, Meta AI's Llama 3.1 405B (smaller than DeepSeek v3's 685B parameters) trained on 11x that - 30,840,000 GPU hours, also on 15 trillion tokens.
DeepSeek v3 benchmarks comparably to Claude 3.5 Sonnet, indicating that it's now possible to train a frontier-class model (at least for the 2024 version of the frontier) for less than $6 million!
For reference, this level of capability is supposed to require clusters of closer to 16K GPUs, the ones being brought up today are more around 100K GPUs. E.g. Llama 3 405B used 30.8M GPU-hours, while DeepSeek-V3 looks to be a stronger model at only 2.8M GPU-hours (~11X less compute). If the model also passes vibe checks (e.g. LLM arena rankings are ongoing, my few quick tests went well so far) it will be a highly impressive display of research and engineering under resource constraints.
DeepSeek also announced their API pricing. From February 8th onwards:
Input: $0.27/million tokens ($0.07/million tokens with cache hits)
Output: $1.10/million tokens
Claude 3.5 Sonnet is currently $3/million for input and $15/million for output, so if the models are indeed of equivalent quality this is a dramatic new twist in the ongoing LLM pricing wars.
deepseek-ai/DeepSeek-V3-Base (via) No model card or announcement yet, but this new model release from Chinese AI lab DeepSeek (an arm of Chinese hedge fund High-Flyer) looks very significant.
It's a huge model - 685B parameters, 687.9 GB on disk (TIL how to size a git-lfs repo). The architecture is a Mixture of Experts with 256 experts, using 8 per token.
For comparison, Meta AI's largest released model is their Llama 3.1 model with 405B parameters.
The new model is apparently available to some people via both chat.deepseek.com and the DeepSeek API as part of a staged rollout.
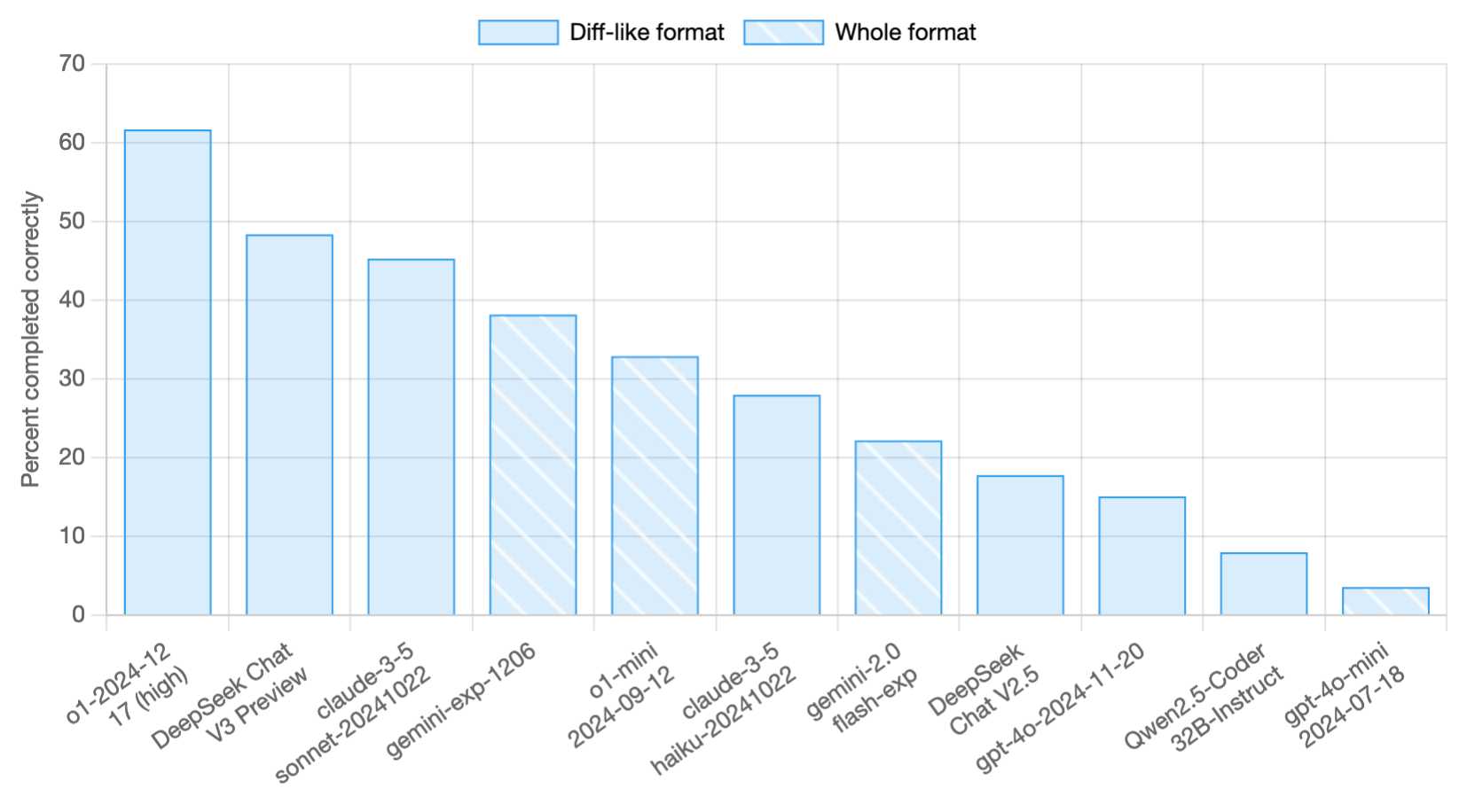
Paul Gauthier got API access and used it to update his new Aider Polyglot leaderboard - DeepSeek v3 preview scored 48.4%, putting it in second place behind o1-2024-12-17 (high) and in front of both claude-3-5-sonnet-20241022 and gemini-exp-1206!
I never know if I can believe models or not (the first time I asked "what model are you?" it claimed to be "based on OpenAI's GPT-4 architecture"), but I just got this result using LLM and the llm-deepseek plugin:
llm -m deepseek-chat 'what deepseek model are you?'
I'm DeepSeek-V3 created exclusively by DeepSeek. I'm an AI assistant, and I'm at your service! Feel free to ask me anything you'd like. I'll do my best to assist you.
Here's my initial experiment log.
Trying out QvQ—Qwen’s new visual reasoning model

I thought we were done for major model releases in 2024, but apparently not: Alibaba’s Qwen team just dropped the Apache 2.0 licensed Qwen licensed (the license changed) QvQ-72B-Preview, “an experimental research model focusing on enhancing visual reasoning capabilities”.
Gemini 2.0 Flash “Thinking mode”
Those new model releases just keep on flowing. Today it’s Google’s snappily named gemini-2.0-flash-thinking-exp, their first entrant into the o1-style inference scaling class of models. I posted about a great essay about the significance of these just this morning.
Phi-4 Technical Report (via) Phi-4 is the latest LLM from Microsoft Research. It has 14B parameters and claims to be a big leap forward in the overall Phi series. From Introducing Phi-4: Microsoft’s Newest Small Language Model Specializing in Complex Reasoning:
Phi-4 outperforms comparable and larger models on math related reasoning due to advancements throughout the processes, including the use of high-quality synthetic datasets, curation of high-quality organic data, and post-training innovations. Phi-4 continues to push the frontier of size vs quality.
The model is currently available via Azure AI Foundry. I couldn't figure out how to access it there, but Microsoft are planning to release it via Hugging Face in the next few days. It's not yet clear what license they'll use - hopefully MIT, as used by the previous models in the series.
In the meantime, unofficial GGUF versions have shown up on Hugging Face already. I got one of the matteogeniaccio/phi-4 GGUFs working with my LLM tool and llm-gguf plugin like this:
llm install llm-gguf
llm gguf download-model https://huggingface.co/matteogeniaccio/phi-4/resolve/main/phi-4-Q4_K_M.gguf
llm chat -m gguf/phi-4-Q4_K_M
This downloaded a 8.4GB model file. Here are some initial logged transcripts I gathered from playing around with the model.
An interesting detail I spotted on the Azure AI Foundry page is this:
Limited Scope for Code: Majority of phi-4 training data is based in Python and uses common packages such as
typing,math,random,collections,datetime,itertools. If the model generates Python scripts that utilize other packages or scripts in other languages, we strongly recommend users manually verify all API uses.
This leads into the most interesting thing about this model: the way it was trained on synthetic data. The technical report has a lot of detail about this, including this note about why synthetic data can provide better guidance to a model:
Synthetic data as a substantial component of pretraining is becoming increasingly common, and the Phi series of models has consistently emphasized the importance of synthetic data. Rather than serving as a cheap substitute for organic data, synthetic data has several direct advantages over organic data.
Structured and Gradual Learning. In organic datasets, the relationship between tokens is often complex and indirect. Many reasoning steps may be required to connect the current token to the next, making it challenging for the model to learn effectively from next-token prediction. By contrast, each token generated by a language model is by definition predicted by the preceding tokens, making it easier for a model to follow the resulting reasoning patterns.
And this section about their approach for generating that data:
Our approach to generating synthetic data for phi-4 is guided by the following principles:
- Diversity: The data should comprehensively cover subtopics and skills within each domain. This requires curating diverse seeds from organic sources.
- Nuance and Complexity: Effective training requires nuanced, non-trivial examples that reflect the complexity and the richness of the domain. Data must go beyond basics to include edge cases and advanced examples.
- Accuracy: Code should execute correctly, proofs should be valid, and explanations should adhere to established knowledge, etc.
- Chain-of-Thought: Data should encourage systematic reasoning, teaching the model various approaches to the problems in a step-by-step manner. [...]
We created 50 broad types of synthetic datasets, each one relying on a different set of seeds and different multi-stage prompting procedure, spanning an array of topics, skills, and natures of interaction, accumulating to a total of about 400B unweighted tokens. [...]
Question Datasets: A large set of questions was collected from websites, forums, and Q&A platforms. These questions were then filtered using a plurality-based technique to balance difficulty. Specifically, we generated multiple independent answers for each question and applied majority voting to assess the consistency of responses. We discarded questions where all answers agreed (indicating the question was too easy) or where answers were entirely inconsistent (indicating the question was too difficult or ambiguous). [...]
Creating Question-Answer pairs from Diverse Sources: Another technique we use for seed curation involves leveraging language models to extract question-answer pairs from organic sources such as books, scientific papers, and code.
Gemini 2.0 Flash: An outstanding multi-modal LLM with a sci-fi streaming mode
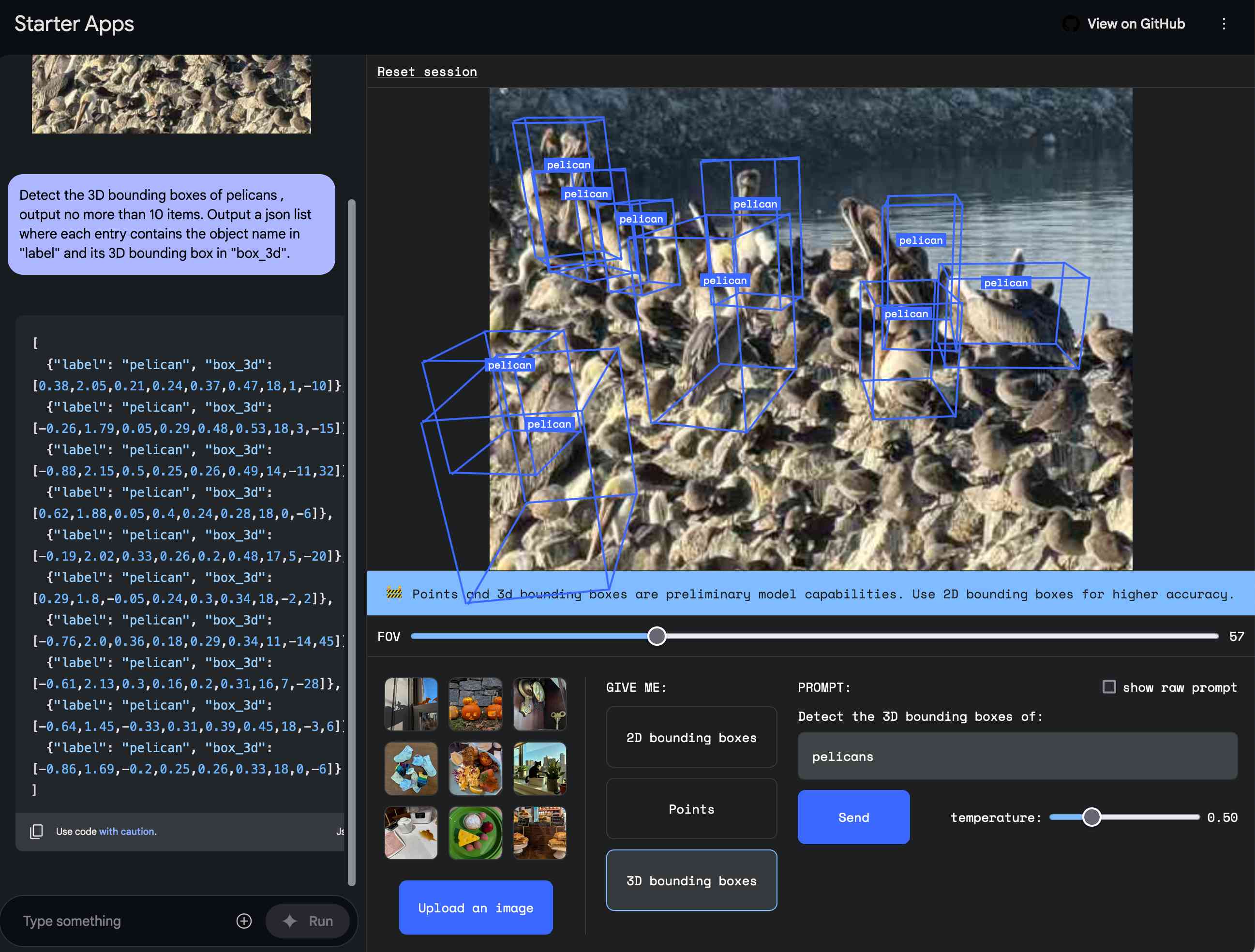
Huge announcment from Google this morning: Introducing Gemini 2.0: our new AI model for the agentic era. There’s a ton of stuff in there (including updates on Project Astra and the new Project Mariner), but the most interesting pieces are the things we can start using today, built around the brand new Gemini 2.0 Flash model. The developer blog post has more of the technical details, and the Gemini 2.0 Cookbook is useful for understanding the API via Python code examples.
[... 1,740 words]