606 posts tagged “llm”
LLM is my command-line tool for running prompts against Large Language Models.
2024
Phi-4 Technical Report (via) Phi-4 is the latest LLM from Microsoft Research. It has 14B parameters and claims to be a big leap forward in the overall Phi series. From Introducing Phi-4: Microsoft’s Newest Small Language Model Specializing in Complex Reasoning:
Phi-4 outperforms comparable and larger models on math related reasoning due to advancements throughout the processes, including the use of high-quality synthetic datasets, curation of high-quality organic data, and post-training innovations. Phi-4 continues to push the frontier of size vs quality.
The model is currently available via Azure AI Foundry. I couldn't figure out how to access it there, but Microsoft are planning to release it via Hugging Face in the next few days. It's not yet clear what license they'll use - hopefully MIT, as used by the previous models in the series.
In the meantime, unofficial GGUF versions have shown up on Hugging Face already. I got one of the matteogeniaccio/phi-4 GGUFs working with my LLM tool and llm-gguf plugin like this:
llm install llm-gguf
llm gguf download-model https://huggingface.co/matteogeniaccio/phi-4/resolve/main/phi-4-Q4_K_M.gguf
llm chat -m gguf/phi-4-Q4_K_M
This downloaded a 8.4GB model file. Here are some initial logged transcripts I gathered from playing around with the model.
An interesting detail I spotted on the Azure AI Foundry page is this:
Limited Scope for Code: Majority of phi-4 training data is based in Python and uses common packages such as
typing,math,random,collections,datetime,itertools. If the model generates Python scripts that utilize other packages or scripts in other languages, we strongly recommend users manually verify all API uses.
This leads into the most interesting thing about this model: the way it was trained on synthetic data. The technical report has a lot of detail about this, including this note about why synthetic data can provide better guidance to a model:
Synthetic data as a substantial component of pretraining is becoming increasingly common, and the Phi series of models has consistently emphasized the importance of synthetic data. Rather than serving as a cheap substitute for organic data, synthetic data has several direct advantages over organic data.
Structured and Gradual Learning. In organic datasets, the relationship between tokens is often complex and indirect. Many reasoning steps may be required to connect the current token to the next, making it challenging for the model to learn effectively from next-token prediction. By contrast, each token generated by a language model is by definition predicted by the preceding tokens, making it easier for a model to follow the resulting reasoning patterns.
And this section about their approach for generating that data:
Our approach to generating synthetic data for phi-4 is guided by the following principles:
- Diversity: The data should comprehensively cover subtopics and skills within each domain. This requires curating diverse seeds from organic sources.
- Nuance and Complexity: Effective training requires nuanced, non-trivial examples that reflect the complexity and the richness of the domain. Data must go beyond basics to include edge cases and advanced examples.
- Accuracy: Code should execute correctly, proofs should be valid, and explanations should adhere to established knowledge, etc.
- Chain-of-Thought: Data should encourage systematic reasoning, teaching the model various approaches to the problems in a step-by-step manner. [...]
We created 50 broad types of synthetic datasets, each one relying on a different set of seeds and different multi-stage prompting procedure, spanning an array of topics, skills, and natures of interaction, accumulating to a total of about 400B unweighted tokens. [...]
Question Datasets: A large set of questions was collected from websites, forums, and Q&A platforms. These questions were then filtered using a plurality-based technique to balance difficulty. Specifically, we generated multiple independent answers for each question and applied majority voting to assess the consistency of responses. We discarded questions where all answers agreed (indicating the question was too easy) or where answers were entirely inconsistent (indicating the question was too difficult or ambiguous). [...]
Creating Question-Answer pairs from Diverse Sources: Another technique we use for seed curation involves leveraging language models to extract question-answer pairs from organic sources such as books, scientific papers, and code.
(echo "PID COMMAND PORT USER"; lsof -i -P -n | grep LISTEN | awk '{print $2, $1, $9, $3}' | sort -u | head -n 50; echo;) | column -t | llm "what servers are running on my machine and do some of them look like they could be orphaned things I can shut down"
Introducing Limbo: A complete rewrite of SQLite in Rust (via) This looks absurdly ambitious:
Our goal is to build a reimplementation of SQLite from scratch, fully compatible at the language and file format level, with the same or higher reliability SQLite is known for, but with full memory safety and on a new, modern architecture.
The Turso team behind it have been maintaining their libSQL fork for two years now, so they're well equipped to take on a challenge of this magnitude.
SQLite is justifiably famous for its meticulous approach to testing. Limbo plans to take an entirely different approach based on "Deterministic Simulation Testing" - a modern technique pioneered by FoundationDB and now spearheaded by Antithesis, the company Turso have been working with on their previous testing projects.
Another bold claim (emphasis mine):
We have both added DST facilities to the core of the database, and partnered with Antithesis to achieve a level of reliability in the database that lives up to SQLite’s reputation.
[...] With DST, we believe we can achieve an even higher degree of robustness than SQLite, since it is easier to simulate unlikely scenarios in a simulator, test years of execution with different event orderings, and upon finding issues, reproduce them 100% reliably.
The two most interesting features that Limbo is planning to offer are first-party WASM support and fully asynchronous I/O:
SQLite itself has a synchronous interface, meaning driver authors who want asynchronous behavior need to have the extra complication of using helper threads. Because SQLite queries tend to be fast, since no network round trips are involved, a lot of those drivers just settle for a synchronous interface. [...]
Limbo is designed to be asynchronous from the ground up. It extends
sqlite3_step, the main entry point API to SQLite, to be asynchronous, allowing it to return to the caller if data is not ready to consume immediately.
Datasette provides an async API for executing SQLite queries which is backed by all manner of complex thread management - I would be very interested in a native asyncio Python library for talking to SQLite database files.
I successfully tried out Limbo's Python bindings against a demo SQLite test database using uv like this:
uv run --with pylimbo python
>>> import limbo
>>> conn = limbo.connect("/tmp/demo.db")
>>> cursor = conn.cursor()
>>> print(cursor.execute("select * from foo").fetchall())
It crashed when I tried against a more complex SQLite database that included SQLite FTS tables.
The Python bindings aren't yet documented, so I piped them through LLM and had the new google-exp-1206 model write this initial documentation for me:
files-to-prompt limbo/bindings/python -c | llm -m gemini-exp-1206 -s 'write extensive usage documentation in markdown, including realistic usage examples'
I can now run a GPT-4 class model on my laptop

Meta’s new Llama 3.3 70B is a genuinely GPT-4 class Large Language Model that runs on my laptop.
[... 2,905 words]llm-openrouter 0.3. New release of my llm-openrouter plugin, which allows LLM to access models hosted by OpenRouter.
Quoting the release notes:
- Enable image attachments for models that support images. Thanks, Adam Montgomery. #12
- Provide async model access. #15
- Fix documentation to list correct
LLM_OPENROUTER_KEYenvironment variable. #10
Prompts.js
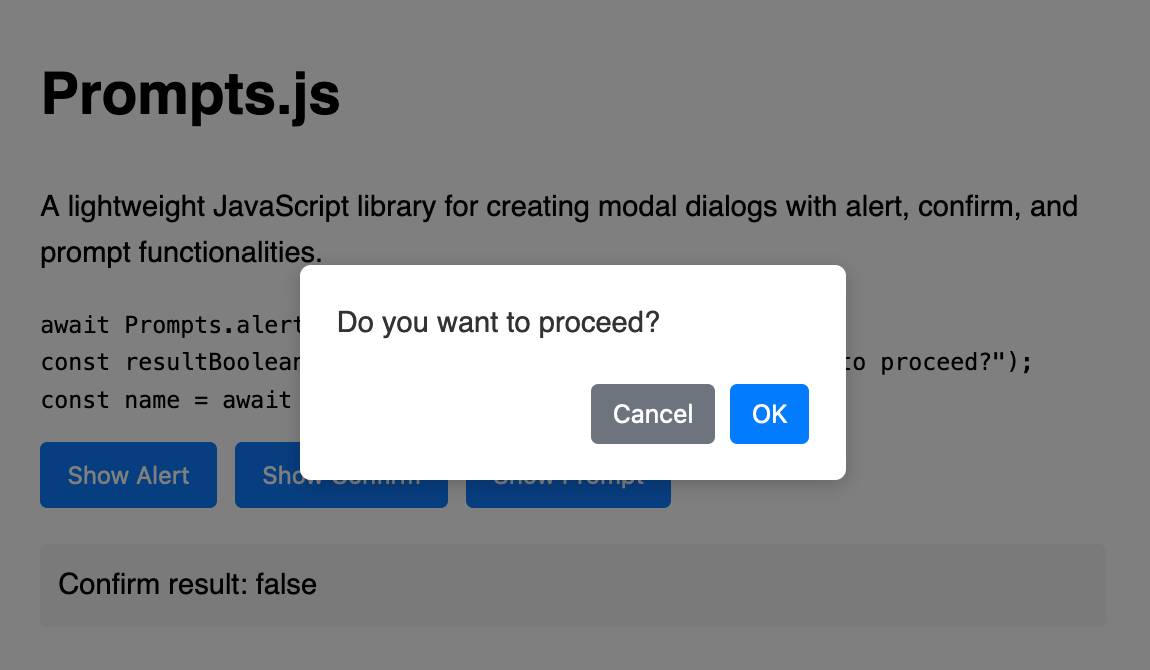
I’ve been putting the new o1 model from OpenAI through its paces, in particular for code. I’m very impressed—it feels like it’s giving me a similar code quality to Claude 3.5 Sonnet, at least for Python and JavaScript and Bash... but it’s returning output noticeably faster.
[... 1,119 words]New Gemini model: gemini-exp-1206. Google's Jeff Dean:
Today’s the one year anniversary of our first Gemini model releases! And it’s never looked better.
Check out our newest release, Gemini-exp-1206, in Google AI Studio and the Gemini API!
I upgraded my llm-gemini plugin to support the new model and released it as version 0.6 - you can install or upgrade it like this:
llm install -U llm-gemini
Running my SVG pelican on a bicycle test prompt:
llm -m gemini-exp-1206 "Generate an SVG of a pelican riding a bicycle"
Provided this result, which is the best I've seen from any model:

Here's the full output - I enjoyed these two pieces of commentary from the model:
<polygon>: Shapes the distinctive pelican beak, with an added line for the lower mandible.
[...]
transform="translate(50, 30)": This attribute on the pelican's<g>tag moves the entire pelican group 50 units to the right and 30 units down, positioning it correctly on the bicycle.
The new model is also currently in top place on the Chatbot Arena.
Update: a delightful bonus, here's what I got from the follow-up prompt:
llm -c "now animate it"

datasette-enrichments-llm. Today's new alpha release is datasette-enrichments-llm, a plugin for Datasette 1.0a+ that provides an enrichment that lets you run prompts against data from one or more column and store the result in another column.
So far it's a light re-implementation of the existing datasette-enrichments-gpt plugin, now using the new llm.get_async_models() method to allow users to select any async-enabled model that has been registered by a plugin - so currently any of the models from OpenAI, Anthropic, Gemini or Mistral via their respective plugins.
Still plenty to do on this one. Next step is to integrate it with datasette-llm-usage and use it to drive a design-complete stable version of that.
First impressions of the new Amazon Nova LLMs (via a new llm-bedrock plugin)
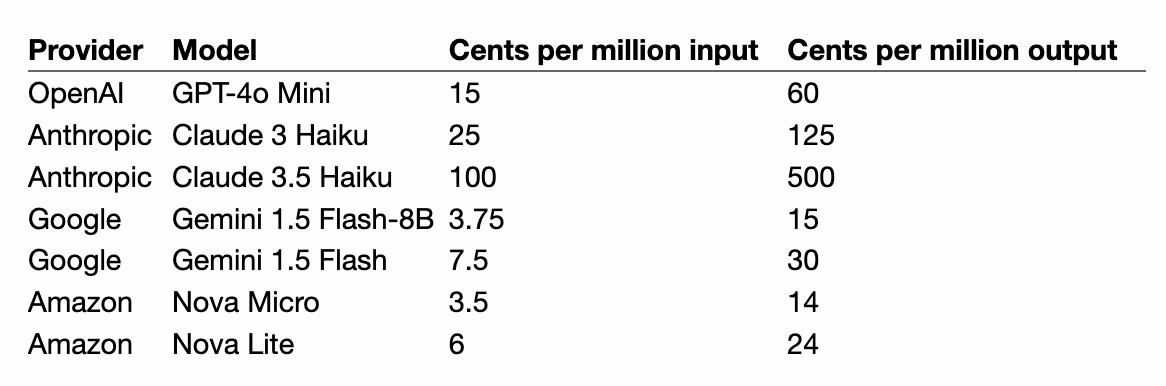
Amazon released three new Large Language Models yesterday at their AWS re:Invent conference. The new model family is called Amazon Nova and comes in three sizes: Micro, Lite and Pro.
[... 2,385 words]datasette-queries. I released the first alpha of a new plugin to replace the crusty old datasette-saved-queries. This one adds a new UI element to the top of the query results page with an expandable form for saving the query as a new canned query:
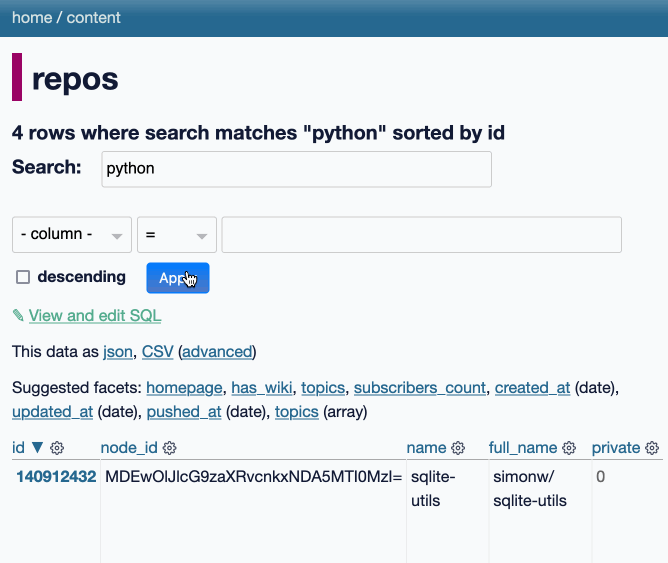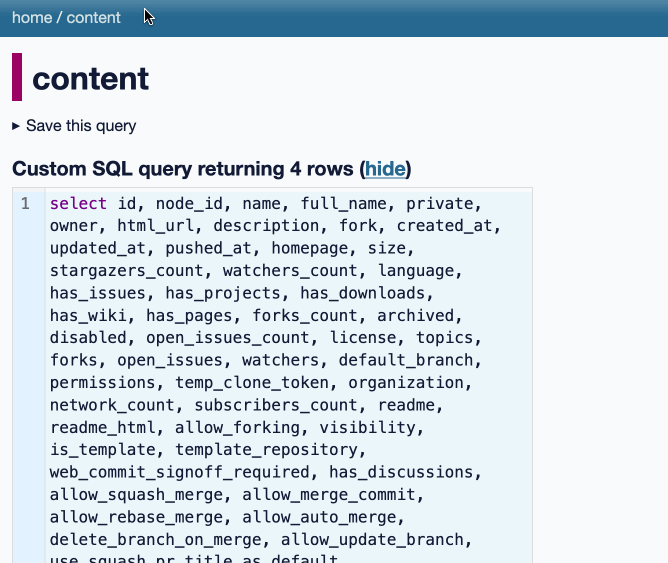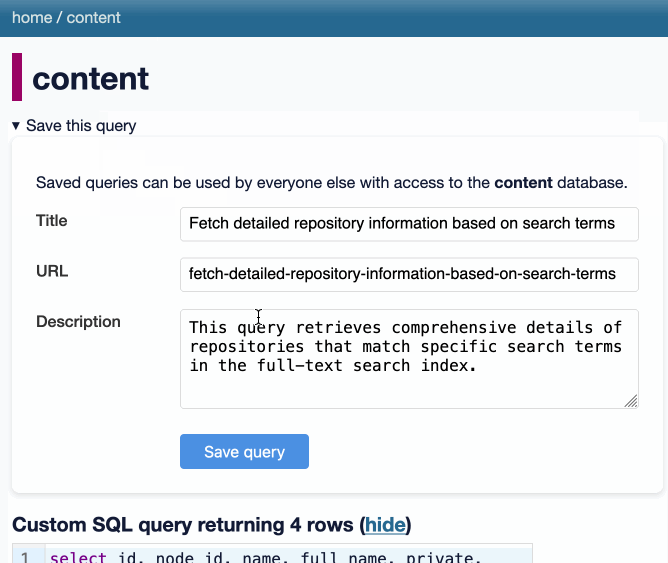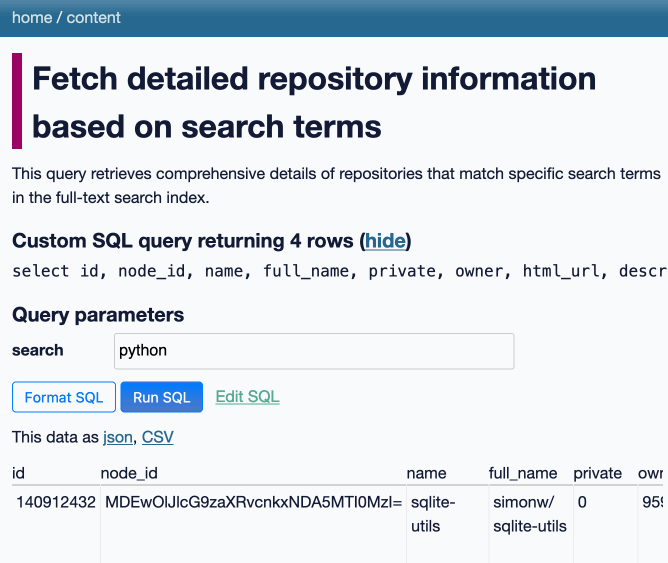
It's my first plugin to depend on LLM and datasette-llm-usage - it uses GPT-4o mini to power an optional "Suggest title and description" button, labeled with the becoming-standard ✨ sparkles emoji to indicate an LLM-powered feature.
I intend to expand this to work across multiple models as I continue to iterate on llm-datasette-usage to better support those kinds of patterns.
For the moment though each suggested title and description call costs about 250 input tokens and 50 output tokens, which against GPT-4o mini adds up to 0.0067 cents.
datasette-llm-usage. I released the first alpha of a Datasette plugin to help track LLM usage by other plugins, with the goal of supporting token allowances - both for things like free public apps that stop working after a daily allowance, plus free previews of AI features for paid-account-based projects such as Datasette Cloud.
It's using the usage features I added in LLM 0.19.
The alpha doesn't do much yet - it will start getting interesting once I upgrade other plugins to depend on it.
Design notes so far in issue #1.
PydanticAI (via) New project from Pydantic, which they describe as an "Agent Framework / shim to use Pydantic with LLMs".
I asked which agent definition they are using and it's the "system prompt with bundled tools" one. To their credit, they explain that in their documentation:
The Agent has full API documentation, but conceptually you can think of an agent as a container for:
- A system prompt — a set of instructions for the LLM written by the developer
- One or more retrieval tool — functions that the LLM may call to get information while generating a response
- An optional structured result type — the structured datatype the LLM must return at the end of a run
Given how many other existing tools already lean on Pydantic to help define JSON schemas for talking to LLMs this is an interesting complementary direction for Pydantic to take.
There's some overlap here with my own LLM project, which I still hope to add a function calling / tools abstraction to in the future.
LLM 0.19. I just released version 0.19 of LLM, my Python library and CLI utility for working with Large Language Models.
I released 0.18 a couple of weeks ago adding support for calling models from Python asyncio code. 0.19 improves on that, and also adds a new mechanism for models to report their token usage.
LLM can log those usage numbers to a SQLite database, or make then available to custom Python code.
My eventual goal with these features is to implement token accounting as a Datasette plugin so I can offer AI features in my SaaS platform without worrying about customers spending unlimited LLM tokens.
Those 0.19 release notes in full:
- Tokens used by a response are now logged to new
input_tokensandoutput_tokensinteger columns and atoken_detailsJSON string column, for the default OpenAI models and models from other plugins that implement this feature. #610llm promptnow takes a-u/--usageflag to display token usage at the end of the response.llm logs -u/--usageshows token usage information for logged responses.llm prompt ... --asyncresponses are now logged to the database. #641llm.get_models()andllm.get_async_models()functions, documented here. #640response.usage()and async responseawait response.usage()methods, returning aUsage(input=2, output=1, details=None)dataclass. #644response.on_done(callback)andawait response.on_done(callback)methods for specifying a callback to be executed when a response has completed, documented here. #653- Fix for bug running
llm chaton Windows 11. Thanks, Sukhbinder Singh. #495
I also released three new plugin versions that add support for the new usage tracking feature: llm-gemini 0.5, llm-claude-3 0.10 and llm-mistral 0.9.