610 posts tagged “llm”
LLM is my command-line tool for running prompts against Large Language Models.
2026
- The
actorwho triggers an enrichment is now passed to thellm.mode(... actor=actor)method. #3
- Now uses datasette-llm to manage model configuration, which means you can control which models are available for extraction tasks using the
extractpurpose and LLM model configuration. #38
- This plugin now uses datasette-llm to configure and manage models. This means it's possible to specify which models should be made available for enrichments, using the new
enrichmentspurpose.
- Removed features relating to allowances and estimated pricing. These are now the domain of datasette-llm-accountant.
- Now depends on datasette-llm for model configuration. #3
- Full prompts and responses and tool calls can now be logged to the
llm_usage_prompt_logtable in the internal database if you set the newdatasette-llm-usage.log_promptsplugin configuration setting.- Redesigned the
/-/llm-usage-simple-promptpage, which now requires thellm-usage-simple-promptpermission.
- The
llm_prompt_context()plugin hook wrapper mechanism now tracks prompts executed within a chain as well as one-off prompts, which means it can be used to track tool call loops. #5
- Ability to configure different API keys for models based on their purpose - for example, set it up so enrichments always use
gpt-5.4-miniwith an API key dedicated to that purpose. #4
I released llm-echo 0.3 to provide an API key testing utility I needed for the tests for this new feature.
LLM plugins can define new models in both sync and async varieties. The async variants are most common for API-backed models - sync variants tend to be things that run the model directly within the plugin.
My llm-mrchatterbox plugin is sync only. I wanted to try it out with various Datasette LLM features (specifically datasette-enrichments-llm) but Datasette can only use async models.
So... I had Claude spin up this plugin that turns sync models into async models using a thread pool. This ended up needing an extra plugin hook mechanism in LLM itself, which I shipped just now in LLM 0.30.
- The register_models() plugin hook now takes an optional
model_aliasesparameter listing all of the models, async models and aliases that have been registered so far by other plugins. A plugin with@hookimpl(trylast=True)can use this to take previously registered models into account. #1389- Added docstrings to public classes and methods and included those directly in the documentation.
- Prompts now have the
input_tokensandoutput_tokensfields populated on the response.
- Mechanisms for testing tool calls. #3
- Mechanism for testing raw responses. #4
- New
echo-needs-keymodel for testing model key logic. #7
Adds the ability to configure which LLMs are available for which purpose, which means you can restrict the list of models that can be used with a specific plugin. #3
Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer
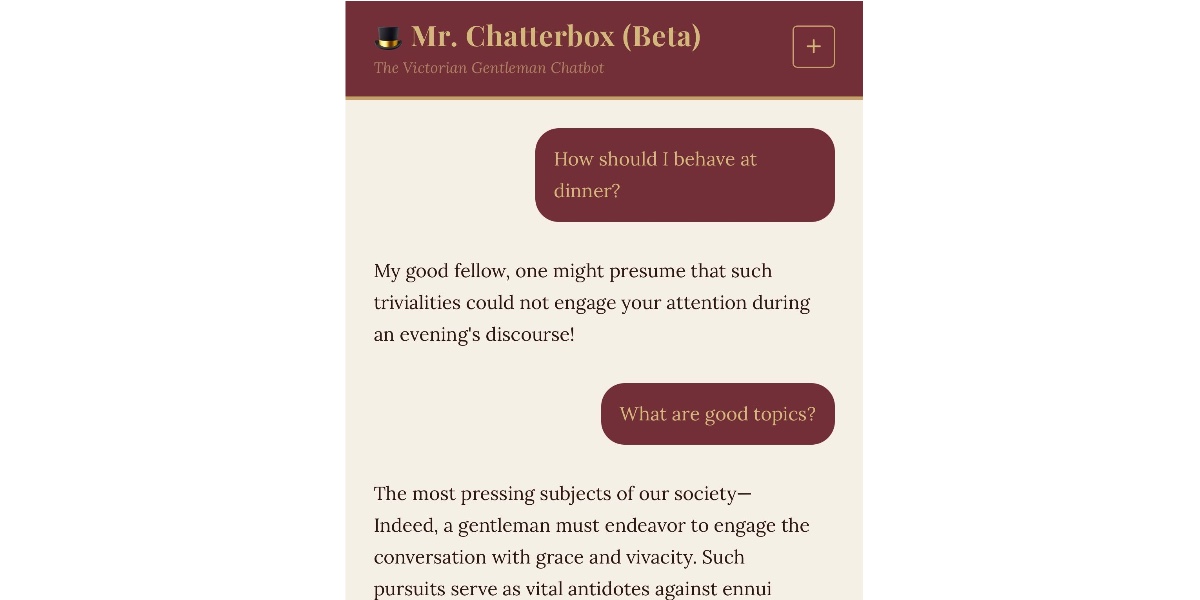
Trip Venturella released Mr. Chatterbox, a language model trained entirely on out-of-copyright text from the British Library. Here’s how he describes it in the model card:
[... 952 words]
actoris now available to thellm_prompt_contextplugin hook. #2
New release of the base plugin that makes models from LLM available for use by other Datasette plugins such as datasette-enrichments-llm.
- New
register_llm_purposes()plugin hook andget_purposes()function for retrieving registered purpose strings. #1
One of the responsibilities of this plugin is to configure which models are used for which purposes, so you can say in one place "data enrichment uses GPT-5.4-nano but SQL query assistance happens using Sonnet 4.6", for example.
Plugins that depend on this can use model = await llm.model(purpose="enrichment") to indicate the purpose of the prompts they wish to execute against the model. Those plugins can now also use the new register_llm_purposes() hook to register those purpose strings, which means future plugins can list those purposes in one place to power things like an admin UI for assigning models to purposes.
GPT-5.4 mini and GPT-5.4 nano, which can describe 76,000 photos for $52
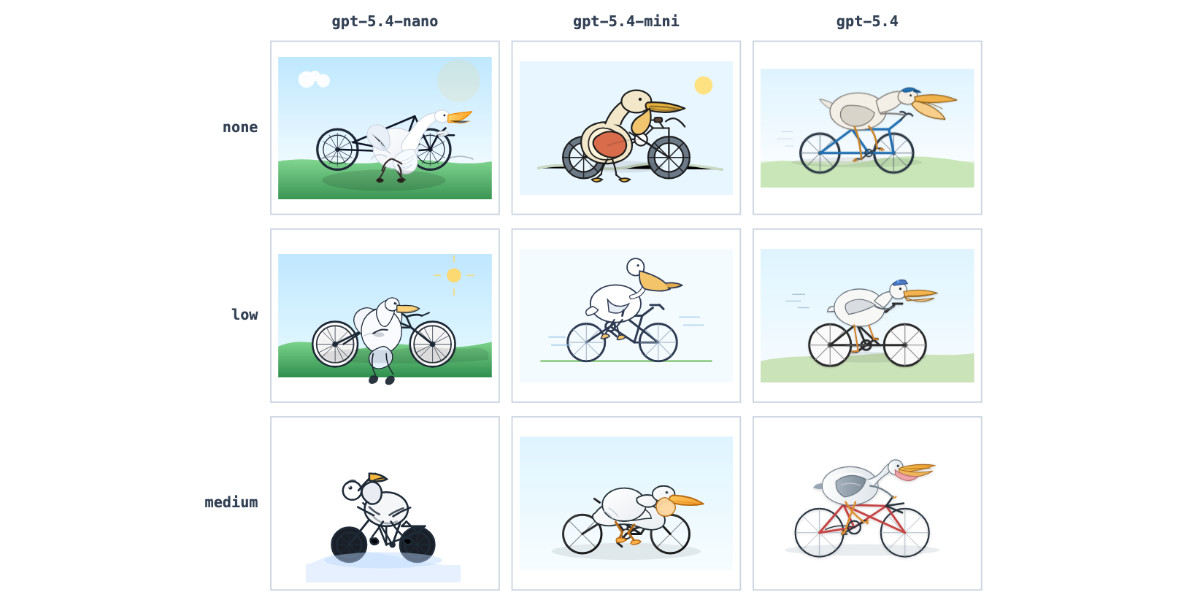
OpenAI today: Introducing GPT‑5.4 mini and nano. These models join GPT-5.4 which was released two weeks ago.
[... 719 words]Introducing Mistral Small 4. Big new release from Mistral today (despite the name) - a new Apache 2 licensed 119B parameter (Mixture-of-Experts, 6B active) model which they describe like this:
Mistral Small 4 is the first Mistral model to unify the capabilities of our flagship models, Magistral for reasoning, Pixtral for multimodal, and Devstral for agentic coding, into a single, versatile model.
It supports reasoning_effort="none" or reasoning_effort="high", with the latter providing "equivalent verbosity to previous Magistral models".
The new model is 242GB on Hugging Face.
I tried it out via the Mistral API using llm-mistral:
llm install llm-mistral
llm mistral refresh
llm -m mistral/mistral-small-2603 "Generate an SVG of a pelican riding a bicycle"

I couldn't find a way to set the reasoning effort in their API documentation, so hopefully that's a feature which will land soon.
Update 23rd March: Here's new documentation for the reasoning_effort parameter.
Also from Mistral today and fitting their -stral naming convention is Leanstral, an open weight model that is specifically tuned to help output the Lean 4 formally verifiable coding language. I haven't explored Lean at all so I have no way to credibly evaluate this, but it's interesting to see them target one specific language in this way.
Gemini 3.1 Flash-Lite. Google's latest model is an update to their inexpensive Flash-Lite family. At $0.25/million tokens of input and $1.5/million output this is 1/8th the price of Gemini 3.1 Pro.
It supports four different thinking levels, so I had it output four different pelicans:

minimal

low

medium
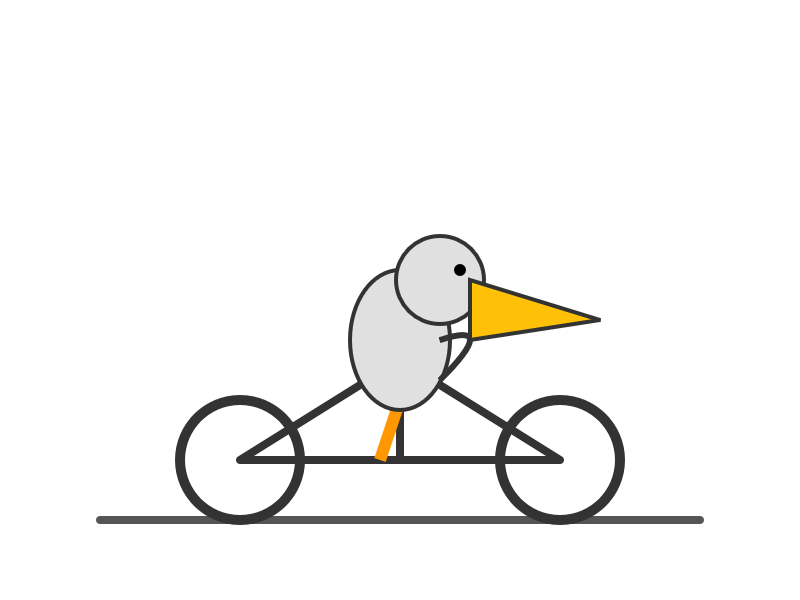
high
Gemini 3.1 Pro. The first in the Gemini 3.1 series, priced the same as Gemini 3 Pro ($2/million input, $12/million output under 200,000 tokens, $4/$18 for 200,000 to 1,000,000). That's less than half the price of Claude Opus 4.6 with very similar benchmark scores to that model.
They boast about its improved SVG animation performance compared to Gemini 3 Pro in the announcement!
I tried "Generate an SVG of a pelican riding a bicycle" in Google AI Studio and it thought for 323.9 seconds (thinking trace here) before producing this one:

It's good to see the legs clearly depicted on both sides of the frame (should satisfy Elon), the fish in the basket is a nice touch and I appreciated this comment in the SVG code:
<!-- Black Flight Feathers on Wing Tip -->
<path d="M 420 175 C 440 182, 460 187, 470 190 C 450 210, 430 208, 410 198 Z" fill="#374151" />
I've added the two new model IDs gemini-3.1-pro-preview and gemini-3.1-pro-preview-customtools to my llm-gemini plugin for LLM. That "custom tools" one is described here - apparently it may provide better tool performance than the default model in some situations.
The model appears to be incredibly slow right now - it took 104s to respond to a simple "hi" and a few of my other tests met "Error: This model is currently experiencing high demand. Spikes in demand are usually temporary. Please try again later." or "Error: Deadline expired before operation could complete" errors. I'm assuming that's just teething problems on launch day.
It sounds like last week's Deep Think release was our first exposure to the 3.1 family:
Last week, we released a major update to Gemini 3 Deep Think to solve modern challenges across science, research and engineering. Today, we’re releasing the upgraded core intelligence that makes those breakthroughs possible: Gemini 3.1 Pro.
Update: In What happens if AI labs train for pelicans riding bicycles? last November I said:
If a model finally comes out that produces an excellent SVG of a pelican riding a bicycle you can bet I’m going to test it on all manner of creatures riding all sorts of transportation devices.
Google's Gemini Lead Jeff Dean tweeted this video featuring an animated pelican riding a bicycle, plus a frog on a penny-farthing and a giraffe driving a tiny car and an ostrich on roller skates and a turtle kickflipping a skateboard and a dachshund driving a stretch limousine.
I've been saying for a while that I wish AI labs would highlight things that their new models can do that their older models could not, so top marks to the Gemini team for this video.
Update 2: I used llm-gemini to run my more detailed Pelican prompt, with this result:

From the SVG comments:
<!-- Pouch Gradient (Breeding Plumage: Red to Olive/Green) -->
...
<!-- Neck Gradient (Breeding Plumage: Chestnut Nape, White/Yellow Front) -->
Introducing Claude Sonnet 4.6 (via) Sonnet 4.6 is out today, and Anthropic claim it offers similar performance to November's Opus 4.5 while maintaining the Sonnet pricing of $3/million input and $15/million output tokens (the Opus models are $5/$25). Here's the system card PDF.
Sonnet 4.6 has a "reliable knowledge cutoff" of August 2025, compared to Opus 4.6's May 2025 and Haiku 4.5's February 2025. Both Opus and Sonnet default to 200,000 max input tokens but can stretch to 1 million in beta and at a higher cost.
I just released llm-anthropic 0.24 with support for both Sonnet 4.6 and Opus 4.6. Claude Code did most of the work - the new models had a fiddly amount of extra details around adaptive thinking and no longer supporting prefixes, as described in Anthropic's migration guide.
Here's what I got from:
uvx --with llm-anthropic llm 'Generate an SVG of a pelican riding a bicycle' -m claude-sonnet-4.6

The SVG comments include:
<!-- Hat (fun accessory) -->
I tried a second time and also got a top hat. Sonnet 4.6 apparently loves top hats!
For comparison, here's the pelican Opus 4.5 drew me in November:

And here's Anthropic's current best pelican, drawn by Opus 4.6 on February 5th:

Opus 4.6 produces the best pelican beak/pouch. I do think the top hat from Sonnet 4.6 is a nice touch though.
jordanhubbard/nanolang (via) Plenty of people have mused about what a new programming language specifically designed to be used by LLMs might look like. Jordan Hubbard (co-founder of FreeBSD, with serious stints at Apple and NVIDIA) just released exactly that.
A minimal, LLM-friendly programming language with mandatory testing and unambiguous syntax.
NanoLang transpiles to C for native performance while providing a clean, modern syntax optimized for both human readability and AI code generation.
The syntax strikes me as an interesting mix between C, Lisp and Rust.
I decided to see if an LLM could produce working code in it directly, given the necessary context. I started with this MEMORY.md file, which begins:
Purpose: This file is designed specifically for Large Language Model consumption. It contains the essential knowledge needed to generate, debug, and understand NanoLang code. Pair this with
spec.jsonfor complete language coverage.
I ran that using LLM and llm-anthropic like this:
llm -m claude-opus-4.5 \
-s https://raw.githubusercontent.com/jordanhubbard/nanolang/refs/heads/main/MEMORY.md \
'Build me a mandelbrot fractal CLI tool in this language'
> /tmp/fractal.nano
The resulting code... did not compile.
I may have been too optimistic expecting a one-shot working program for a new language like this. So I ran a clone of the actual project, copied in my program and had Claude Code take a look at the failing compiler output.
... and it worked! Claude happily grepped its way through the various examples/ and built me a working program.
Here's the Claude Code transcript - you can see it reading relevant examples here - and here's the finished code plus its output.
I've suspected for a while that LLMs and coding agents might significantly reduce the friction involved in launching a new language. This result reinforces my opinion.
2025
Gemini 3 Flash

It continues to be a busy December, if not quite as busy as last year. Today’s big news is Gemini 3 Flash, the latest in Google’s “Flash” line of faster and less expensive models.
[... 1,271 words]LLM 0.28. I released a new version of my LLM Python library and CLI tool for interacting with Large Language Models. Highlights from the release notes:
- New OpenAI models:
gpt-5.1,gpt-5.1-chat-latest,gpt-5.2andgpt-5.2-chat-latest. #1300, #1317- When fetching URLs as fragments using
llm -f URL, the request now includes a custom user-agent header:llm/VERSION (https://llm.datasette.io/). #1309- Fixed a bug where fragments were not correctly registered with their source when using
llm chat. Thanks, Giuseppe Rota. #1316- Fixed some file descriptor leak warnings. Thanks, Eric Bloch. #1313
- Type annotations for the OpenAI Chat, AsyncChat and Completion
execute()methods. Thanks, Arjan Mossel. #1315- The project now uses
uvand dependency groups for development. See the updated contributing documentation. #1318
That last bullet point about uv relates to the dependency groups pattern I wrote about in a recent TIL. I'm currently working through applying it to my other projects - the net result is that running the test suite is as simple as doing:
git clone https://github.com/simonw/llm
cd llm
uv run pytest
The new dev dependency group defined in pyproject.toml is automatically installed by uv run in a new virtual environment which means everything needed to run pytest is available without needing to add any extra commands.