606 posts tagged “llm”
LLM is my command-line tool for running prompts against Large Language Models.
2025
Maybe Meta’s Llama claims to be open source because of the EU AI act

I encountered a theory a while ago that one of the reasons Meta insist on using the term “open source” for their Llama models despite the Llama license not actually conforming to the terms of the Open Source Definition is that the EU’s AI act includes special rules for open source models without requiring OSI compliance.
[... 852 words]Gemma 3 QAT Models. Interesting release from Google, as a follow-up to Gemma 3 from last month:
To make Gemma 3 even more accessible, we are announcing new versions optimized with Quantization-Aware Training (QAT) that dramatically reduces memory requirements while maintaining high quality. This enables you to run powerful models like Gemma 3 27B locally on consumer-grade GPUs like the NVIDIA RTX 3090.
I wasn't previously aware of Quantization-Aware Training but it turns out to be quite an established pattern now, supported in both Tensorflow and PyTorch.
Google report model size drops from BF16 to int4 for the following models:
- Gemma 3 27B: 54GB to 14.1GB
- Gemma 3 12B: 24GB to 6.6GB
- Gemma 3 4B: 8GB to 2.6GB
- Gemma 3 1B: 2GB to 0.5GB
They partnered with Ollama, LM Studio, MLX (here's their collection) and llama.cpp for this release - I'd love to see more AI labs following their example.
The Ollama model version picker currently hides them behind "View all" option, so here are the direct links:
- gemma3:1b-it-qat - 1GB
- gemma3:4b-it-qat - 4GB
- gemma3:12b-it-qat - 8.9GB
- gemma3:27b-it-qat - 18GB
I fetched that largest model with:
ollama pull gemma3:27b-it-qat
And now I'm trying it out with llm-ollama:
llm -m gemma3:27b-it-qat "impress me with some physics"
I got a pretty great response!
Update: Having spent a while putting it through its paces via Open WebUI and Tailscale to access my laptop from my phone I think this may be my new favorite general-purpose local model. Ollama appears to use 22GB of RAM while the model is running, which leaves plenty on my 64GB machine for other applications.
I've also tried it via llm-mlx like this (downloading 16GB):
llm install llm-mlx
llm mlx download-model mlx-community/gemma-3-27b-it-qat-4bit
llm chat -m mlx-community/gemma-3-27b-it-qat-4bit
It feels a little faster with MLX and uses 15GB of memory according to Activity Monitor.
Start building with Gemini 2.5 Flash
(via)
Google Gemini's latest model is Gemini 2.5 Flash, available in (paid) preview as gemini-2.5-flash-preview-04-17.
Building upon the popular foundation of 2.0 Flash, this new version delivers a major upgrade in reasoning capabilities, while still prioritizing speed and cost. Gemini 2.5 Flash is our first fully hybrid reasoning model, giving developers the ability to turn thinking on or off. The model also allows developers to set thinking budgets to find the right tradeoff between quality, cost, and latency.
Gemini AI Studio product lead Logan Kilpatrick says:
This is an early version of 2.5 Flash, but it already shows huge gains over 2.0 Flash.
You can fully turn off thinking if needed and use this model as a drop in replacement for 2.0 Flash.
I added support to the new model in llm-gemini 0.18. Here's how to try it out:
llm install -U llm-gemini
llm -m gemini-2.5-flash-preview-04-17 'Generate an SVG of a pelican riding a bicycle'
Here's that first pelican, using the default setting where Gemini Flash 2.5 makes its own decision in terms of how much "thinking" effort to apply:

Here's the transcript. This one used 11 input tokens, 4,266 output tokens and 2,702 "thinking" tokens.
I asked the model to "describe" that image and it could tell it was meant to be a pelican:
A simple illustration on a white background shows a stylized pelican riding a bicycle. The pelican is predominantly grey with a black eye and a prominent pink beak pouch. It is positioned on a black line-drawn bicycle with two wheels, a frame, handlebars, and pedals.
The way the model is priced is a little complicated. If you have thinking enabled, you get charged $0.15/million tokens for input and $3.50/million for output. With thinking disabled those output tokens drop to $0.60/million. I've added these to my pricing calculator.
For comparison, Gemini 2.0 Flash is $0.10/million input and $0.40/million for output.
So my first prompt - 11 input and 4,266+2,702 =6,968 output (with thinking enabled), cost 2.439 cents.
Let's try 2.5 Flash again with thinking disabled:
llm -m gemini-2.5-flash-preview-04-17 'Generate an SVG of a pelican riding a bicycle' -o thinking_budget 0

11 input, 1705 output. That's 0.1025 cents. Transcript here - it still shows 25 thinking tokens even though I set the thinking budget to 0 - Logan confirms that this will still be billed at the lower rate:
In some rare cases, the model still thinks a little even with thinking budget = 0, we are hoping to fix this before we make this model stable and you won't be billed for thinking. The thinking budget = 0 is what triggers the billing switch.
Here's Gemini 2.5 Flash's self-description of that image:
A minimalist illustration shows a bright yellow bird riding a bicycle. The bird has a simple round body, small wings, a black eye, and an open orange beak. It sits atop a simple black bicycle frame with two large circular black wheels. The bicycle also has black handlebars and black and yellow pedals. The scene is set against a solid light blue background with a thick green stripe along the bottom, suggesting grass or ground.
And finally, let's ramp the thinking budget up to the maximum:
llm -m gemini-2.5-flash-preview-04-17 'Generate an SVG of a pelican riding a bicycle' -o thinking_budget 24576
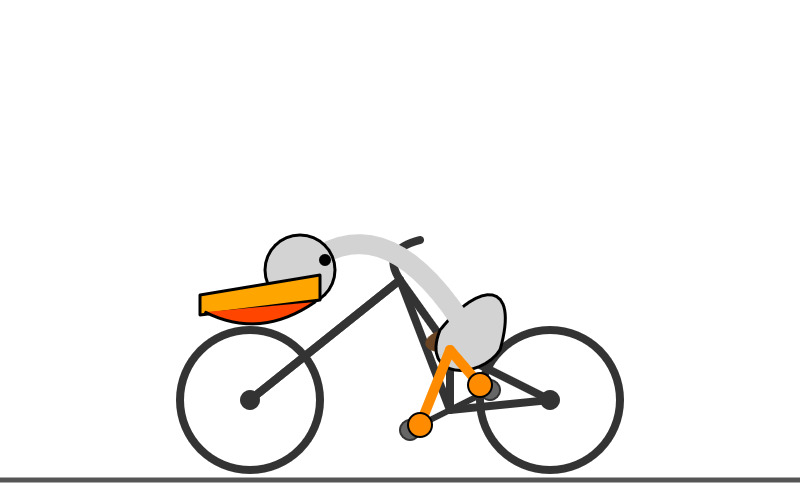
I think it over-thought this one. Transcript - 5,174 output tokens and 3,023 thinking tokens. A hefty 2.8691 cents!
A simple, cartoon-style drawing shows a bird-like figure riding a bicycle. The figure has a round gray head with a black eye and a large, flat orange beak with a yellow stripe on top. Its body is represented by a curved light gray shape extending from the head to a smaller gray shape representing the torso or rear. It has simple orange stick legs with round feet or connections at the pedals. The figure is bent forward over the handlebars in a cycling position. The bicycle is drawn with thick black outlines and has two large wheels, a frame, and pedals connected to the orange legs. The background is plain white, with a dark gray line at the bottom representing the ground.
One thing I really appreciate about Gemini 2.5 Flash's approach to SVGs is that it shows very good taste in CSS, comments and general SVG class structure. Here's a truncated extract - I run a lot of these SVG tests against different models and this one has a coding style that I particularly enjoy. (Gemini 2.5 Pro does this too).
<svg width="800" height="500" viewBox="0 0 800 500" xmlns="http://www.w3.org/2000/svg"> <style> .bike-frame { fill: none; stroke: #333; stroke-width: 8; stroke-linecap: round; stroke-linejoin: round; } .wheel-rim { fill: none; stroke: #333; stroke-width: 8; } .wheel-hub { fill: #333; } /* ... */ .pelican-body { fill: #d3d3d3; stroke: black; stroke-width: 3; } .pelican-head { fill: #d3d3d3; stroke: black; stroke-width: 3; } /* ... */ </style> <!-- Ground Line --> <line x1="0" y1="480" x2="800" y2="480" stroke="#555" stroke-width="5"/> <!-- Bicycle --> <g id="bicycle"> <!-- Wheels --> <circle class="wheel-rim" cx="250" cy="400" r="70"/> <circle class="wheel-hub" cx="250" cy="400" r="10"/> <circle class="wheel-rim" cx="550" cy="400" r="70"/> <circle class="wheel-hub" cx="550" cy="400" r="10"/> <!-- ... --> </g> <!-- Pelican --> <g id="pelican"> <!-- Body --> <path class="pelican-body" d="M 440 330 C 480 280 520 280 500 350 C 480 380 420 380 440 330 Z"/> <!-- Neck --> <path class="pelican-neck" d="M 460 320 Q 380 200 300 270"/> <!-- Head --> <circle class="pelican-head" cx="300" cy="270" r="35"/> <!-- ... -->
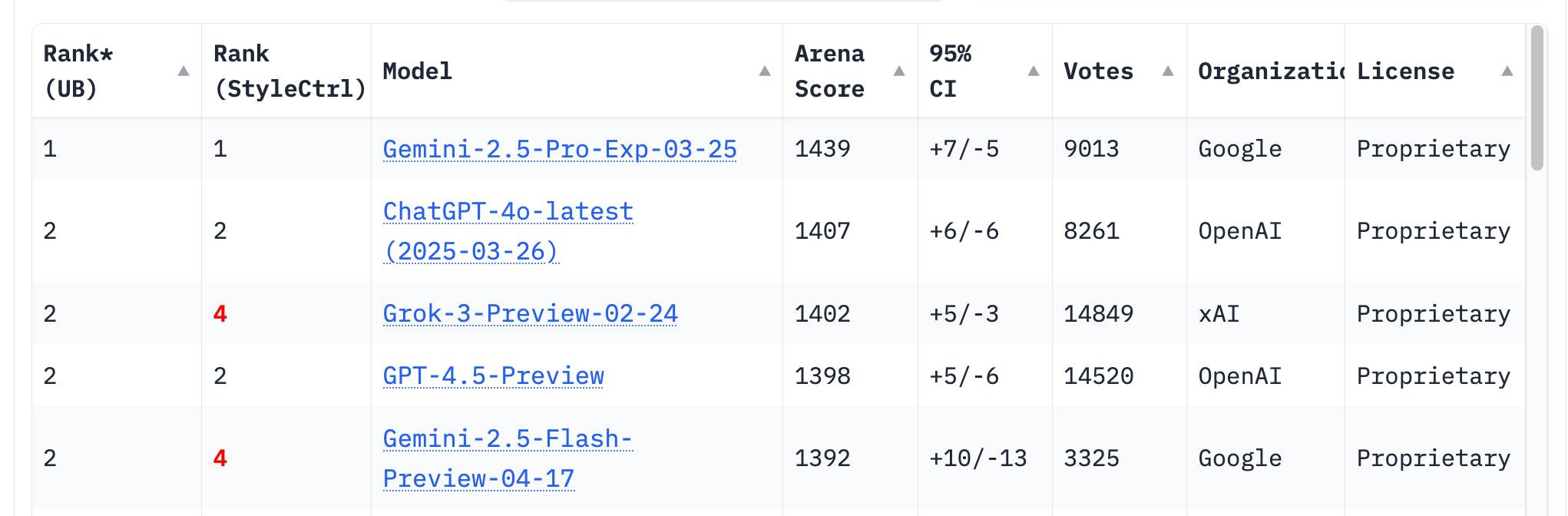
The LM Arena leaderboard now has Gemini 2.5 Flash in joint second place, just behind Gemini 2.5 Pro and tied with ChatGPT-4o-latest, Grok-3 and GPT-4.5 Preview.
Introducing OpenAI o3 and o4-mini. OpenAI are really emphasizing tool use with these:
For the first time, our reasoning models can agentically use and combine every tool within ChatGPT—this includes searching the web, analyzing uploaded files and other data with Python, reasoning deeply about visual inputs, and even generating images. Critically, these models are trained to reason about when and how to use tools to produce detailed and thoughtful answers in the right output formats, typically in under a minute, to solve more complex problems.
I released llm-openai-plugin 0.3 adding support for the two new models:
llm install -U llm-openai-plugin
llm -m openai/o3 "say hi in five languages"
llm -m openai/o4-mini "say hi in five languages"
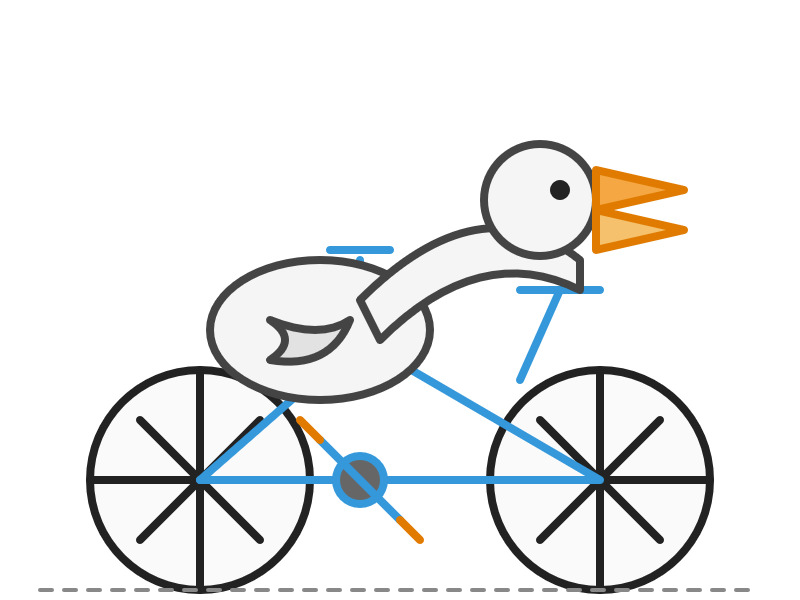
Here are the pelicans riding bicycles (prompt: Generate an SVG of a pelican riding a bicycle).
o3:
o4-mini:

Here are the full OpenAI model listings: o3 is $10/million input and $40/million for output, with a 75% discount on cached input tokens, 200,000 token context window, 100,000 max output tokens and a May 31st 2024 training cut-off (same as the GPT-4.1 models). It's a bit cheaper than o1 ($15/$60) and a lot cheaper than o1-pro ($150/$600).
o4-mini is priced the same as o3-mini: $1.10/million for input and $4.40/million for output, also with a 75% input caching discount. The size limits and training cut-off are the same as o3.
You can compare these prices with other models using the table on my updated LLM pricing calculator.
A new capability released today is that the OpenAI API can now optionally return reasoning summary text. I've been exploring that in this issue. I believe you have to verify your organization (which may involve a photo ID) in order to use this option - once you have access the easiest way to see the new tokens is using curl like this:
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(llm keys get openai)" \
-d '{
"model": "o3",
"input": "why is the sky blue?",
"reasoning": {"summary": "auto"},
"stream": true
}'
This produces a stream of events that includes this new event type:
event: response.reasoning_summary_text.delta
data: {"type": "response.reasoning_summary_text.delta","item_id": "rs_68004320496081918e1e75ddb550d56e0e9a94ce520f0206","output_index": 0,"summary_index": 0,"delta": "**Expl"}
Omit the "stream": true and the response is easier to read and contains this:
{
"output": [
{
"id": "rs_68004edd2150819183789a867a9de671069bc0c439268c95",
"type": "reasoning",
"summary": [
{
"type": "summary_text",
"text": "**Explaining the blue sky**\n\nThe user asks a classic question about why the sky is blue. I'll talk about Rayleigh scattering, where shorter wavelengths of light scatter more than longer ones. This explains how we see blue light spread across the sky! I wonder if the user wants a more scientific or simpler everyday explanation. I'll aim for a straightforward response while keeping it engaging and informative. So, let's break it down!"
}
]
},
{
"id": "msg_68004edf9f5c819188a71a2c40fb9265069bc0c439268c95",
"type": "message",
"status": "completed",
"content": [
{
"type": "output_text",
"annotations": [],
"text": "The short answer ..."
}
]
}
]
}
GPT-4.1: Three new million token input models from OpenAI, including their cheapest model yet

OpenAI introduced three new models this morning: GPT-4.1, GPT-4.1 mini and GPT-4.1 nano. These are API-only models right now, not available through the ChatGPT interface (though you can try them out in OpenAI’s API playground). All three models can handle 1,047,576 tokens of input and 32,768 tokens of output, and all three have a May 31, 2024 cut-off date (their previous models were mostly September 2023).
[... 1,124 words]llm-fragments-rust
(via)
Inspired by Filippo Valsorda's llm-fragments-go, Francois Garillot created llm-fragments-rust, an LLM fragments plugin that lets you pull documentation for any Rust crate directly into a prompt to LLM.
I really like this example, which uses two fragments to load documentation for two crates at once:
llm -f rust:rand@0.8.5 -f rust:tokio "How do I generate random numbers asynchronously?"
The code uses some neat tricks: it creates a new Rust project in a temporary directory (similar to how llm-fragments-go works), adds the crates and uses cargo doc --no-deps --document-private-items to generate documentation. Then it runs cargo tree --edges features to add dependency information, and cargo metadata --format-version=1 to include additional metadata about the crate.
llm-docsmith (via) Matheus Pedroni released this neat plugin for LLM for adding docstrings to existing Python code. You can run it like this:
llm install llm-docsmith
llm docsmith ./scripts/main.py -o
The -o option previews the changes that will be made - without -o it edits the files directly.
It also accepts a -m claude-3.7-sonnet parameter for using an alternative model from the default (GPT-4o mini).
The implementation uses the Python libcst "Concrete Syntax Tree" package to manipulate the code, which means there's no chance of it making edits to anything other than the docstrings.
Here's the full system prompt it uses.
One neat trick is at the end of the system prompt it says:
You will receive a JSON template. Fill the slots marked with <SLOT> with the appropriate description. Return as JSON.
That template is actually provided JSON generated using these Pydantic classes:
class Argument(BaseModel): name: str description: str annotation: str | None = None default: str | None = None class Return(BaseModel): description: str annotation: str | None class Docstring(BaseModel): node_type: Literal["class", "function"] name: str docstring: str args: list[Argument] | None = None ret: Return | None = None class Documentation(BaseModel): entries: list[Docstring]
The code adds <SLOT> notes to that in various places, so the template included in the prompt ends up looking like this:
{
"entries": [
{
"node_type": "function",
"name": "create_docstring_node",
"docstring": "<SLOT>",
"args": [
{
"name": "docstring_text",
"description": "<SLOT>",
"annotation": "str",
"default": null
},
{
"name": "indent",
"description": "<SLOT>",
"annotation": "str",
"default": null
}
],
"ret": {
"description": "<SLOT>",
"annotation": "cst.BaseStatement"
}
}
]
}
llm-fragments-go (via) Filippo Valsorda released the first plugin by someone other than me that uses LLM's new register_fragment_loaders() plugin hook I announced the other day.
Install with llm install llm-fragments-go and then:
You can feed the docs of a Go package into LLM using the
go:fragment with the package name, optionally followed by a version suffix.
llm -f go:golang.org/x/mod/sumdb/note@v0.23.0 "Write a single file command that generates a key, prints the verifier key, signs an example message, and prints the signed note."
The implementation is just 33 lines of Python and works by running these commands in a temporary directory:
go mod init llm_fragments_go
go get golang.org/x/mod/sumdb/note@v0.23.0
go doc -all golang.org/x/mod/sumdb/note
An LLM Query Understanding Service (via) Doug Turnbull recently wrote about how all search is structured now:
Many times, even a small open source LLM will be able to turn a search query into reasonable structure at relatively low cost.
In this follow-up tutorial he demonstrates Qwen 2-7B running in a GPU-enabled Google Kubernetes Engine container to turn user search queries like "red loveseat" into structured filters like {"item_type": "loveseat", "color": "red"}.
Here's the prompt he uses.
Respond with a single line of JSON:
{"item_type": "sofa", "material": "wood", "color": "red"}
Omit any other information. Do not include any
other text in your response. Omit a value if the
user did not specify it. For example, if the user
said "red sofa", you would respond with:
{"item_type": "sofa", "color": "red"}
Here is the search query: blue armchair
Out of curiosity, I tried running his prompt against some other models using LLM:
gemini-1.5-flash-8b, the cheapest of the Gemini models, handled it well and cost $0.000011 - or 0.0011 cents.llama3.2:3bworked too - that's a very small 2GB model which I ran using Ollama.deepseek-r1:1.5b- a tiny 1.1GB model, again via Ollama, amusingly failed by interpreting "red loveseat" as{"item_type": "sofa", "material": null, "color": "red"}after thinking very hard about the problem!
Mistral Small 3.1 on Ollama. Mistral Small 3.1 (previously) is now available through Ollama, providing an easy way to run this multi-modal (vision) model on a Mac (and other platforms, though I haven't tried those myself).
I had to upgrade Ollama to the most recent version to get it to work - prior to that I got a Error: unable to load model message. Upgrades can be accessed through the Ollama macOS system tray icon.
I fetched the 15GB model by running:
ollama pull mistral-small3.1
Then used llm-ollama to run prompts through it, including one to describe this image:
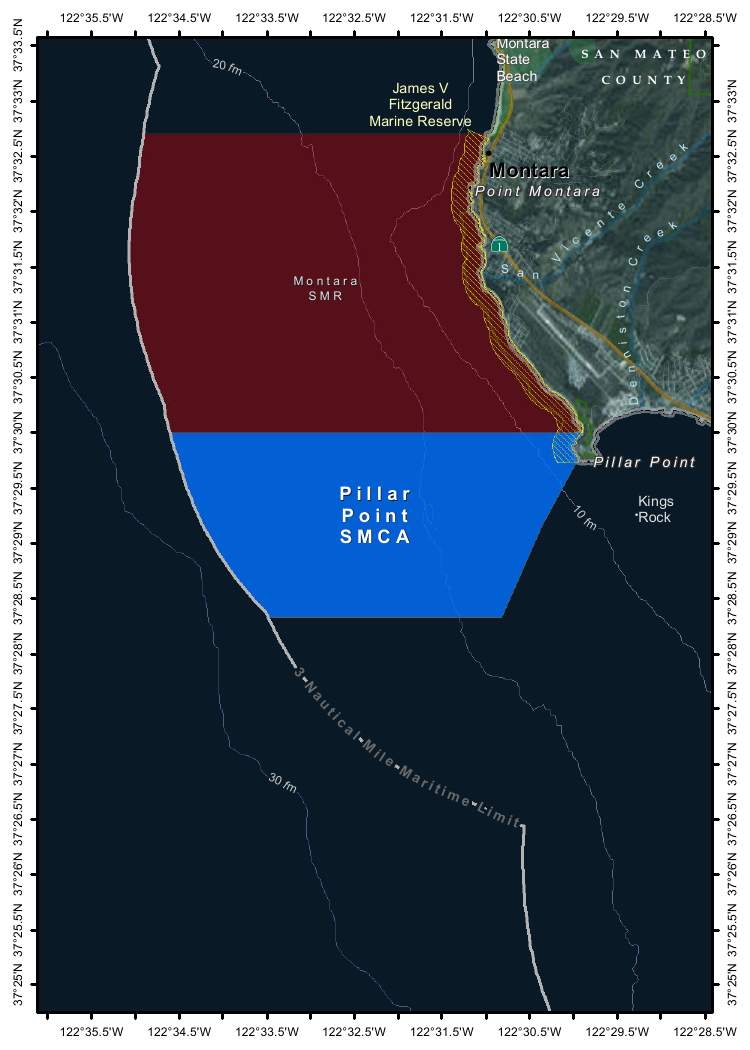{kind=link}
llm install llm-ollama
llm -m mistral-small3.1 'describe this image' -a https://static.simonwillison.net/static/2025/Mpaboundrycdfw-1.png
Here's the output. It's good, though not quite as impressive as the description I got from the slightly larger Qwen2.5-VL-32B.
I also tried it on a scanned (private) PDF of hand-written text with very good results, though it did misread one of the hand-written numbers.
llm-hacker-news. I built this new plugin to exercise the new register_fragment_loaders() plugin hook I added to LLM 0.24. It's the plugin equivalent of the Bash script I've been using to summarize Hacker News conversations for the past 18 months.
You can use it like this:
llm install llm-hacker-news
llm -f hn:43615912 'summary with illustrative direct quotes'
You can see the output in this issue.
The plugin registers a hn: prefix - combine that with the ID of a Hacker News conversation to pull that conversation into the context.
It uses the Algolia Hacker News API which returns JSON like this. Rather than feed the JSON directly to the LLM it instead converts it to a hopefully more LLM-friendly format that looks like this example from the plugin's test:
[1] BeakMaster: Fish Spotting Techniques
[1.1] CoastalFlyer: The dive technique works best when hunting in shallow waters.
[1.1.1] PouchBill: Agreed. Have you tried the hover method near the pier?
[1.1.2] WingSpan22: My bill gets too wet with that approach.
[1.1.2.1] CoastalFlyer: Try tilting at a 40° angle like our Australian cousins.
[1.2] BrownFeathers: Anyone spotted those "silver fish" near the rocks?
[1.2.1] GulfGlider: Yes! They're best caught at dawn.
Just remember: swoop > grab > lift
That format was suggested by Claude, which then wrote most of the plugin implementation for me. Here's that Claude transcript.
Long context support in LLM 0.24 using fragments and template plugins
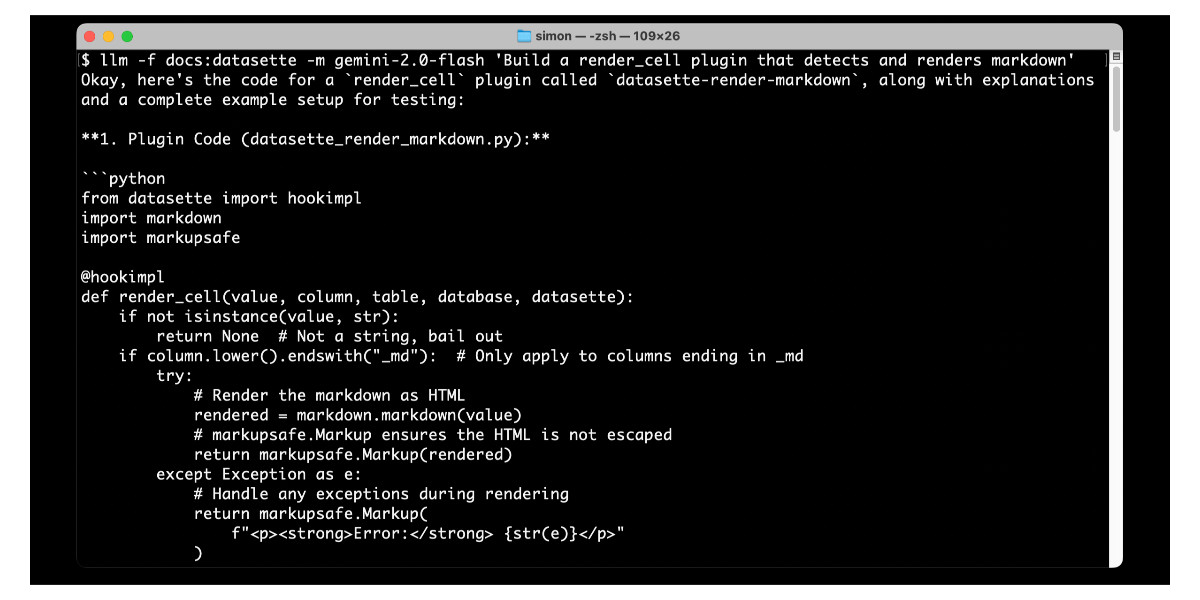
LLM 0.24 is now available with new features to help take advantage of the increasingly long input context supported by modern LLMs.
[... 1,896 words]