158 posts tagged “local-llms”
LLMs that can run on consumer hardware like laptops or mobile phones.
2025
Structured data extraction from unstructured content using LLM schemas
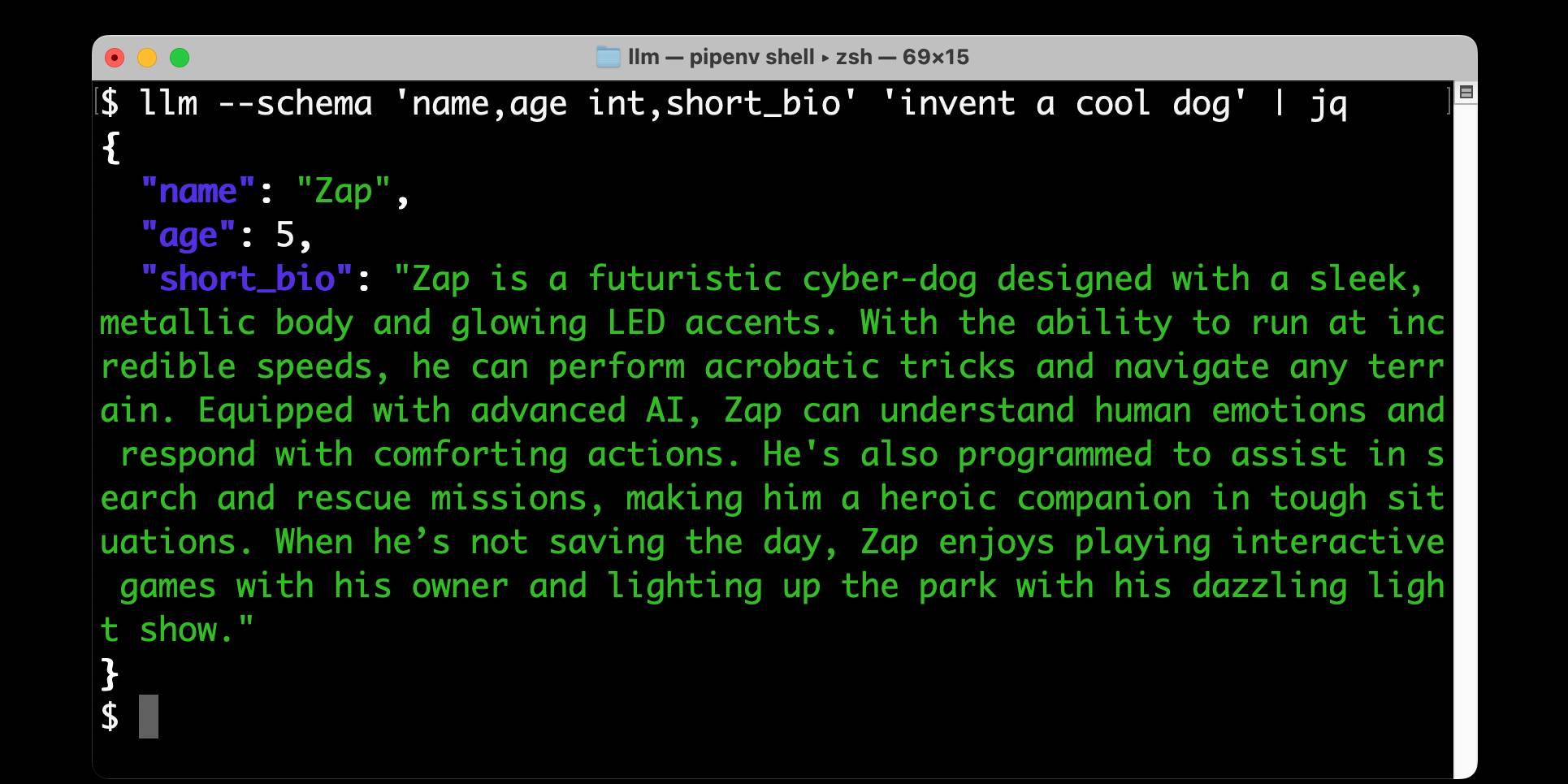
LLM 0.23 is out today, and the signature feature is support for schemas—a new way of providing structured output from a model that matches a specification provided by the user. I’ve also upgraded both the llm-anthropic and llm-gemini plugins to add support for schemas.
[... 2,601 words]olmOCR (via) New from Ai2 - olmOCR is "an open-source tool designed for high-throughput conversion of PDFs and other documents into plain text while preserving natural reading order".
At its core is allenai/olmOCR-7B-0225-preview, a Qwen2-VL-7B-Instruct variant trained on ~250,000 pages of diverse PDF content (both scanned and text-based) that were labelled using GPT-4o and made available as the olmOCR-mix-0225 dataset.
The olmocr Python library can run the model on any "recent NVIDIA GPU". I haven't managed to run it on my own Mac yet - there are GGUFs out there but it's not clear to me how to run vision prompts through them - but Ai2 offer an online demo which can handle up to ten pages for free.
Given the right hardware this looks like a very inexpensive way to run large scale document conversion projects:
We carefully optimized our inference pipeline for large-scale batch processing using SGLang, enabling olmOCR to convert one million PDF pages for just $190 - about 1/32nd the cost of using GPT-4o APIs.
The most interesting idea from the technical report (PDF) is something they call "document anchoring":
Document anchoring extracts coordinates of salient elements in each page (e.g., text blocks and images) and injects them alongside raw text extracted from the PDF binary file. [...]
Document anchoring processes PDF document pages via the PyPDF library to extract a representation of the page’s structure from the underlying PDF. All of the text blocks and images in the page are extracted, including position information. Starting with the most relevant text blocks and images, these are sampled and added to the prompt of the VLM, up to a defined maximum character limit. This extra information is then available to the model when processing the document.
![Left side shows a green-header interface with coordinates like [150x220]√3x−1+(1+x)², [150x180]Section 6, [150x50]Lorem ipsum dolor sit amet, [150x70]consectetur adipiscing elit, sed do, [150x90]eiusmod tempor incididunt ut, [150x110]labore et dolore magna aliqua, [100x280]Table 1, followed by grid coordinates with A, B, C, AA, BB, CC, AAA, BBB, CCC values. Right side shows the rendered document with equation, text and table.](https://static.simonwillison.net/static/2025/olmocr-document-anchoring.jpg)
The one limitation of olmOCR at the moment is that it doesn't appear to do anything with diagrams, figures or illustrations. Vision models are actually very good at interpreting these now, so my ideal OCR solution would include detailed automated descriptions of this kind of content in the resulting text.
Update: Jonathan Soma figured out how to run it on a Mac using LM Studio and the olmocr Python package.
Run LLMs on macOS using llm-mlx and Apple’s MLX framework
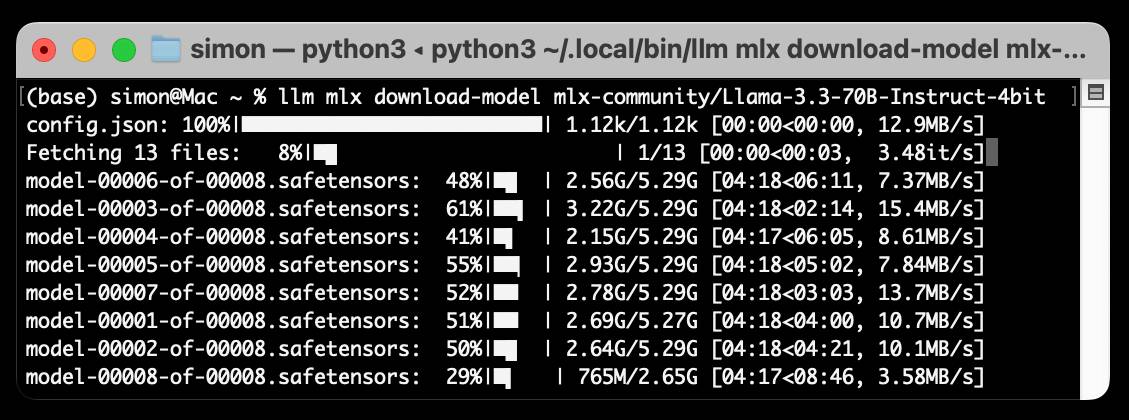
llm-mlx is a brand new plugin for my LLM Python Library and CLI utility which builds on top of Apple’s excellent MLX array framework library and mlx-lm package. If you’re a terminal user or Python developer with a Mac this may be the new easiest way to start exploring local Large Language Models.
[... 1,524 words]Using pip to install a Large Language Model that’s under 100MB
I just released llm-smollm2, a new plugin for LLM that bundles a quantized copy of the SmolLM2-135M-Instruct LLM inside of the Python package.
[... 1,553 words]S1: The $6 R1 Competitor? Tim Kellogg shares his notes on a new paper, s1: Simple test-time scaling, which describes an inference-scaling model fine-tuned on top of Qwen2.5-32B-Instruct for just $6 - the cost for 26 minutes on 16 NVIDIA H100 GPUs.
Tim highlight the most exciting result:
After sifting their dataset of 56K examples down to just the best 1K, they found that the core 1K is all that's needed to achieve o1-preview performance on a 32B model.
The paper describes a technique called "Budget forcing":
To enforce a minimum, we suppress the generation of the end-of-thinking token delimiter and optionally append the string “Wait” to the model’s current reasoning trace to encourage the model to reflect on its current generation
That's the same trick Theia Vogel described a few weeks ago.
Here's the s1-32B model on Hugging Face. I found a GGUF version of it at brittlewis12/s1-32B-GGUF, which I ran using Ollama like so:
ollama run hf.co/brittlewis12/s1-32B-GGUF:Q4_0
I also found those 1,000 samples on Hugging Face in the simplescaling/s1K data repository there.
I used DuckDB to convert the parquet file to CSV (and turn one VARCHAR[] column into JSON):
COPY (
SELECT
solution,
question,
cot_type,
source_type,
metadata,
cot,
json_array(thinking_trajectories) as thinking_trajectories,
attempt
FROM 's1k-00001.parquet'
) TO 'output.csv' (HEADER, DELIMITER ',');
Then I loaded that CSV into sqlite-utils so I could use the convert command to turn a Python data structure into JSON using json.dumps() and eval():
# Load into SQLite
sqlite-utils insert s1k.db s1k output.csv --csv
# Fix that column
sqlite-utils convert s1k.db s1u metadata 'json.dumps(eval(value))' --import json
# Dump that back out to CSV
sqlite-utils rows s1k.db s1k --csv > s1k.csv
Here's that CSV in a Gist, which means I can load it into Datasette Lite.
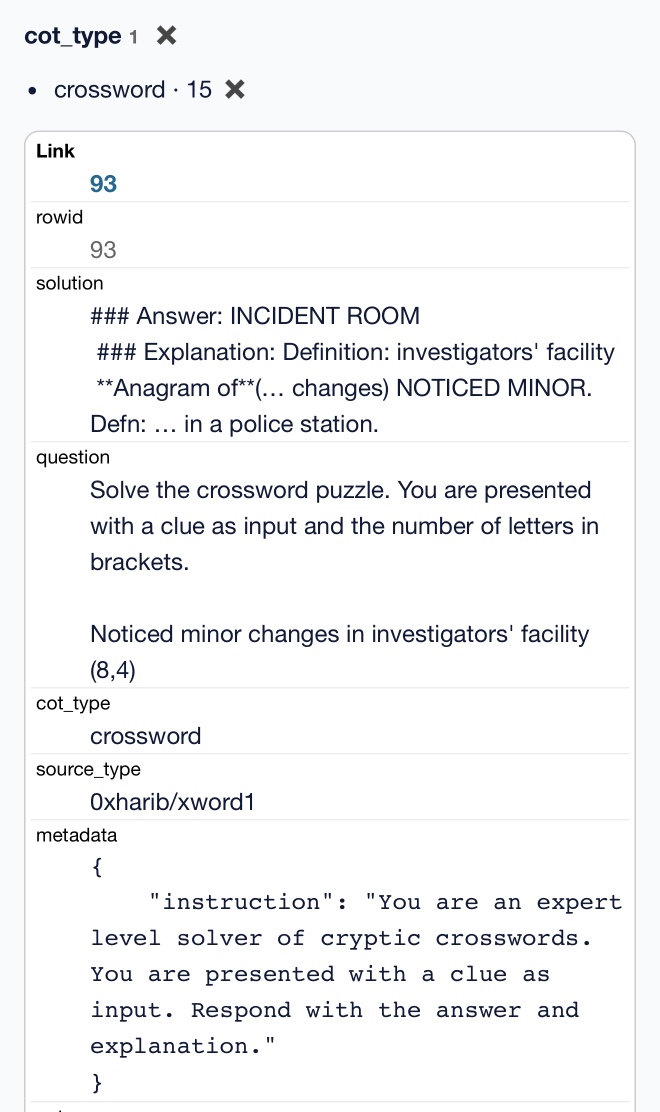
It really is a tiny amount of training data. It's mostly math and science, but there are also 15 cryptic crossword examples.
Mistral Small 3 (via) First model release of 2025 for French AI lab Mistral, who describe Mistral Small 3 as "a latency-optimized 24B-parameter model released under the Apache 2.0 license."
More notably, they claim the following:
Mistral Small 3 is competitive with larger models such as Llama 3.3 70B or Qwen 32B, and is an excellent open replacement for opaque proprietary models like GPT4o-mini. Mistral Small 3 is on par with Llama 3.3 70B instruct, while being more than 3x faster on the same hardware.
Llama 3.3 70B and Qwen 32B are two of my favourite models to run on my laptop - that ~20GB size turns out to be a great trade-off between memory usage and model utility. It's exciting to see a new entrant into that weight class.
The license is important: previous Mistral Small models used their Mistral Research License, which prohibited commercial deployments unless you negotiate a commercial license with them. They appear to be moving away from that, at least for their core models:
We’re renewing our commitment to using Apache 2.0 license for our general purpose models, as we progressively move away from MRL-licensed models. As with Mistral Small 3, model weights will be available to download and deploy locally, and free to modify and use in any capacity. […] Enterprises and developers that need specialized capabilities (increased speed and context, domain specific knowledge, task-specific models like code completion) can count on additional commercial models complementing what we contribute to the community.
Despite being called Mistral Small 3, this appears to be the fourth release of a model under that label. The Mistral API calls this one mistral-small-2501 - previous model IDs were mistral-small-2312, mistral-small-2402 and mistral-small-2409.
I've updated the llm-mistral plugin for talking directly to Mistral's La Plateforme API:
llm install -U llm-mistral
llm keys set mistral
# Paste key here
llm -m mistral/mistral-small-latest "tell me a joke about a badger and a puffin"
Sure, here's a light-hearted joke for you:
Why did the badger bring a puffin to the party?
Because he heard puffins make great party 'Puffins'!
(That's a play on the word "puffins" and the phrase "party people.")
API pricing is $0.10/million tokens of input, $0.30/million tokens of output - half the price of the previous Mistral Small API model ($0.20/$0.60). for comparison, GPT-4o mini is $0.15/$0.60.
Mistral also ensured that the new model was available on Ollama in time for their release announcement.
You can pull the model like this (fetching 14GB):
ollama run mistral-small:24b
The llm-ollama plugin will then let you prompt it like so:
llm install llm-ollama
llm -m mistral-small:24b "say hi"
Qwen2.5 VL! Qwen2.5 VL! Qwen2.5 VL! Hot on the heels of yesterday's Qwen2.5-1M, here's Qwen2.5 VL (with an excitable announcement title) - the latest in Qwen's series of vision LLMs.
They're releasing multiple versions: base models and instruction tuned models at 3B, 7B and 72B. There's a lot of additional information in their README.
The 72B model can be selected on Qwen's Qwen Chat interface. I gave it this image of our dog Cleo joy rolling on the beach:

And prompted:
Describe this image in detail, be flowery
(Since the Qwen team tends to use flowery language in their announcements.)
Here's what I got back:
In this enchanting tableau, a canine companion finds solace in the embrace of nature's softest bed. The sandy expanse stretches out like an endless canvas, its surface etched with the delicate imprints of countless wanderers who have come and gone, leaving behind a tapestry of footprints that whisper tales of joyous romps and serene strolls.
The dog, a vision of contentment, lies sprawled upon the sand, its dark fur gleaming under the gentle caress of the sun. Its body is relaxed, limbs splayed in abandon, as if it has surrendered to the soothing rhythm of the beach. A vibrant red collar adorns its neck, a splash of color against the muted tones of the surroundings, hinting at the care and love bestowed upon this cherished pet.
The sand itself is a work of art, its grains shimmering with a silvery sheen that catches the light. Here and there, small tufts of seaweed peek through, remnants of the ocean's bounty, adding a touch of wild beauty to the scene. The shadows cast by unseen objects dance across the sand, creating a play of light and dark that lends an air of mystery to the tranquil setting.
This moment, frozen in time, speaks of peace and harmony, where man's best friend finds respite in the simple pleasures of life. It is a scene that invites one to pause, breathe deeply, and revel in the serenity of nature's embrace.
I'm looking forward to trying out their smaller models - the 3B model in particular should be small enough to run comfortably even on an iPhone, so hopefully someone will wire up an example of that soon (maybe using MLX).
VB points out that the vision benchmarks for Qwen 2.5 VL 7B show it out-performing GPT-4o mini!
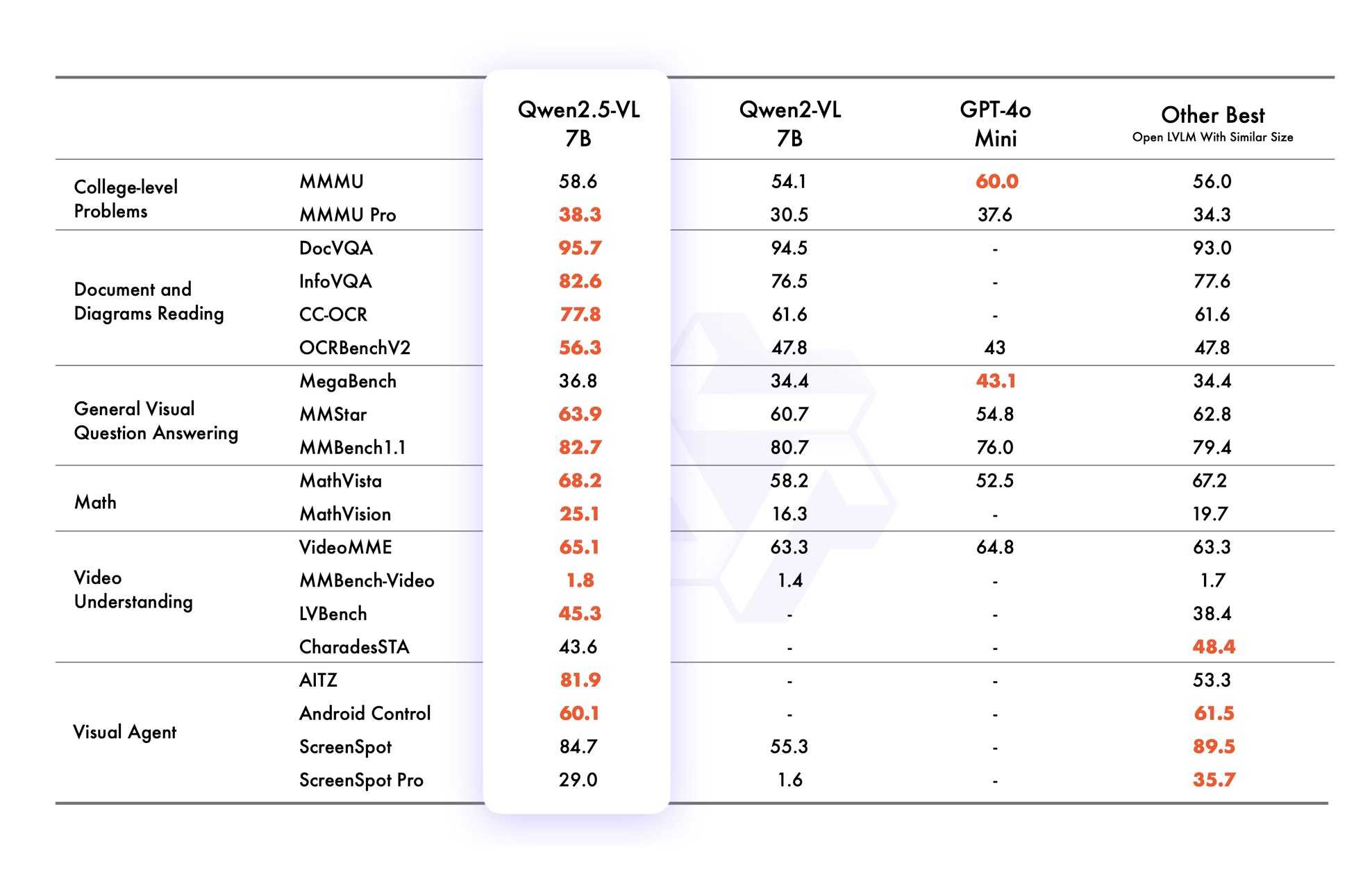
Qwen2.5 VL cookbooks
Qwen also just published a set of cookbook recipes:
- universal_recognition.ipynb demonstrates basic visual Q&A, including prompts like
Who are these in this picture? Please give their names in Chinese and Englishagainst photos of celebrities, an ability other models have deliberately suppressed. - spatial_understanding.ipynb demonstrates bounding box support, with prompts like
Locate the top right brown cake, output its bbox coordinates using JSON format. - video_understanding.ipynb breaks a video into individual frames and asks questions like
Could you go into detail about the content of this long video? - ocr.ipynb shows
Qwen2.5-VL-7B-Instructperforming OCR in multiple different languages. - document_parsing.ipynb uses Qwen to convert images of documents to HTML and other formats, and notes that "we introduce a unique Qwenvl HTML format that includes positional information for each component, enabling precise document reconstruction and manipulation."
- mobile_agent.ipynb runs Qwen with tool use against tools for controlling a mobile phone, similar to ChatGPT Operator or Claude Computer Use.
- computer_use.ipynb showcases "GUI grounding" - feeding in screenshots of a user's desktop and running tools for things like left clicking on a specific coordinate.
Running it with mlx-vlm
Update 30th January 2025: I got it working on my Mac using uv and mlx-vlm, with some hints from this issue. Here's the recipe that worked (downloading a 9GB model from mlx-community/Qwen2.5-VL-7B-Instruct-8bit):
uv run --with 'numpy<2' --with 'git+https://github.com/huggingface/transformers' \
--with mlx-vlm \
python -m mlx_vlm.generate \
--model mlx-community/Qwen2.5-VL-7B-Instruct-8bit \
--max-tokens 100 \
--temp 0.0 \
--prompt "Describe this image." \
--image path-to-image.pngI ran that against this image:
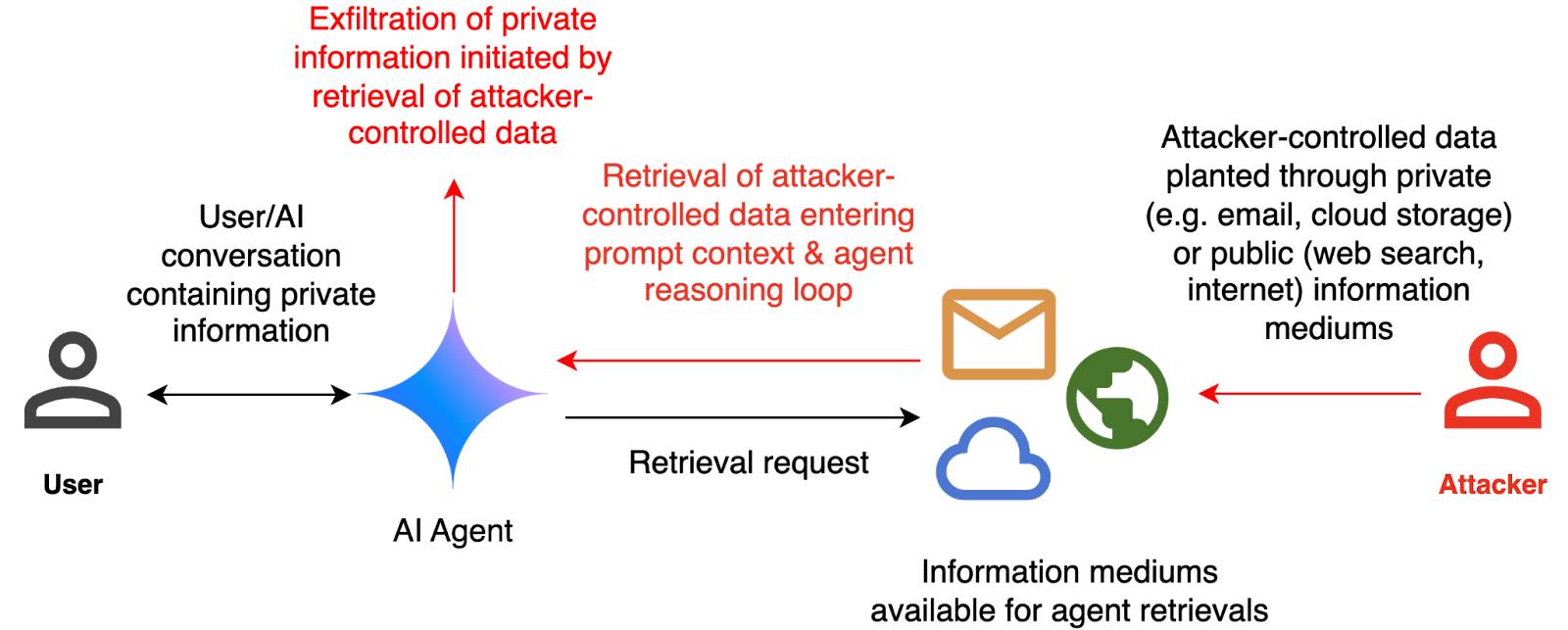
And got back this result:
The image appears to illustrate a flowchart or diagram related to a cybersecurity scenario. Here's a breakdown of the elements:
- User: Represented by a simple icon of a person.
- AI Agent: Represented by a blue diamond shape.
- Attacker: Represented by a red icon of a person.
- Cloud and Email Icons: Represented by a cloud and an envelope, indicating data or information being transferred.
- Text: The text
Qwen2.5-1M: Deploy Your Own Qwen with Context Length up to 1M Tokens (via) Very significant new release from Alibaba's Qwen team. Their openly licensed (sometimes Apache 2, sometimes Qwen license, I've had trouble keeping up) Qwen 2.5 LLM previously had an input token limit of 128,000 tokens. This new model increases that to 1 million, using a new technique called Dual Chunk Attention, first described in this paper from February 2024.
They've released two models on Hugging Face: Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M, both requiring CUDA and both under an Apache 2.0 license.
You'll need a lot of VRAM to run them at their full capacity:
VRAM Requirement for processing 1 million-token sequences:
- Qwen2.5-7B-Instruct-1M: At least 120GB VRAM (total across GPUs).
- Qwen2.5-14B-Instruct-1M: At least 320GB VRAM (total across GPUs).
If your GPUs do not have sufficient VRAM, you can still use Qwen2.5-1M models for shorter tasks.
Qwen recommend using their custom fork of vLLM to serve the models:
You can also use the previous framework that supports Qwen2.5 for inference, but accuracy degradation may occur for sequences exceeding 262,144 tokens.
GGUF quantized versions of the models are already starting to show up. LM Studio's "official model curator" Bartowski published lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF and lmstudio-community/Qwen2.5-14B-Instruct-1M-GGUF - sizes range from 4.09GB to 8.1GB for the 7B model and 7.92GB to 15.7GB for the 14B.
These might not work well yet with the full context lengths as the underlying llama.cpp library may need some changes.
I tried running the 8.1GB 7B model using Ollama on my Mac like this:
ollama run hf.co/lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF:Q8_0
Then with LLM:
llm install llm-ollama
llm models -q qwen # To search for the model ID
# I set a shorter q1m alias:
llm aliases set q1m hf.co/lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF:Q8_0
I tried piping a large prompt in using files-to-prompt like this:
files-to-prompt ~/Dropbox/Development/llm -e py -c | llm -m q1m 'describe this codebase in detail'
That should give me every Python file in my llm project. Piping that through ttok first told me this was 63,014 OpenAI tokens, I expect that count is similar for Qwen.
The result was disappointing: it appeared to describe just the last Python file that stream. Then I noticed the token usage report:
2,048 input, 999 output
This suggests to me that something's not working right here - maybe the Ollama hosting framework is truncating the input, or maybe there's a problem with the GGUF I'm using?
I'll update this post when I figure out how to run longer prompts through the new Qwen model using GGUF weights on a Mac.
Update: It turns out Ollama has a num_ctx option which defaults to 2048, affecting the input context length. I tried this:
files-to-prompt \
~/Dropbox/Development/llm \
-e py -c | \
llm -m q1m 'describe this codebase in detail' \
-o num_ctx 80000
But I quickly ran out of RAM (I have 64GB but a lot of that was in use already) and hit Ctrl+C to avoid crashing my computer. I need to experiment a bit to figure out how much RAM is used for what context size.
Awni Hannun shared tips for running mlx-community/Qwen2.5-7B-Instruct-1M-4bit using MLX, which should work for up to 250,000 tokens. They ran 120,000 tokens and reported:
- Peak RAM for prompt filling was 22GB
- Peak RAM for generation 12GB
- Prompt filling took 350 seconds on an M2 Ultra
- Generation ran at 31 tokens-per-second on M2 Ultra
Run DeepSeek R1 or V3 with MLX Distributed (via) Handy detailed instructions from Awni Hannun on running the enormous DeepSeek R1 or v3 models on a cluster of Macs using the distributed communication feature of Apple's MLX library.
DeepSeek R1 quantized to 4-bit requires 450GB in aggregate RAM, which can be achieved by a cluster of three 192 GB M2 Ultras ($16,797 will buy you three 192GB Apple M2 Ultra Mac Studios at $5,599 each).
DeepSeek-R1 and exploring DeepSeek-R1-Distill-Llama-8B

DeepSeek are the Chinese AI lab who dropped the best currently available open weights LLM on Christmas day, DeepSeek v3. That model was trained in part using their unreleased R1 “reasoning” model. Today they’ve released R1 itself, along with a whole family of new models derived from that base.
[... 1,276 words]microsoft/phi-4. Here's the official release of Microsoft's Phi-4 LLM, now officially under an MIT license.
A few weeks ago I covered the earlier unofficial versions, where I talked about how the model used synthetic training data in some really interesting ways.
It benchmarks favorably compared to GPT-4o, suggesting this is yet another example of a GPT-4 class model that can run on a good laptop.
The model already has several available community quantizations. I ran the mlx-community/phi-4-4bit one (a 7.7GB download) using mlx-llm like this:
uv run --with 'numpy<2' --with mlx-lm python -c '
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/phi-4-4bit")
prompt = "Generate an SVG of a pelican riding a bicycle"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True, max_tokens=2048)
print(response)'

Update: The model is now available via Ollama, so you can fetch a 9.1GB model file using ollama run phi4, after which it becomes available via the llm-ollama plugin.
2024
Things we learned about LLMs in 2024
A lot has happened in the world of Large Language Models over the course of 2024. Here’s a review of things we figured out about the field in the past twelve months, plus my attempt at identifying key themes and pivotal moments.
[... 7,490 words]Open WebUI. I tried out this open source (MIT licensed, JavaScript and Python) localhost UI for accessing LLMs today for the first time. It's very nicely done.
I ran it with uvx like this:
uvx --python 3.11 open-webui serve
On first launch it installed a bunch of dependencies and then downloaded 903MB to ~/.cache/huggingface/hub/models--sentence-transformers--all-MiniLM-L6-v2 - a copy of the all-MiniLM-L6-v2 embedding model, presumably for its RAG feature.
It then presented me with a working Llama 3.2:3b chat interface, which surprised me because I hadn't spotted it downloading that model. It turns out that was because I have Ollama running on my laptop already (with several models, including Llama 3.2:3b, already installed) - and Open WebUI automatically detected Ollama and gave me access to a list of available models.
I found a "knowledge" section and added all of the Datasette documentation (by dropping in the .rst files from the docs) - and now I can type # in chat to search for a file, add that to the context and then ask questions about it directly.
I selected the spatialite.rst.txt file, prompted it with "How do I use SpatiaLite with Datasette" and got back this:
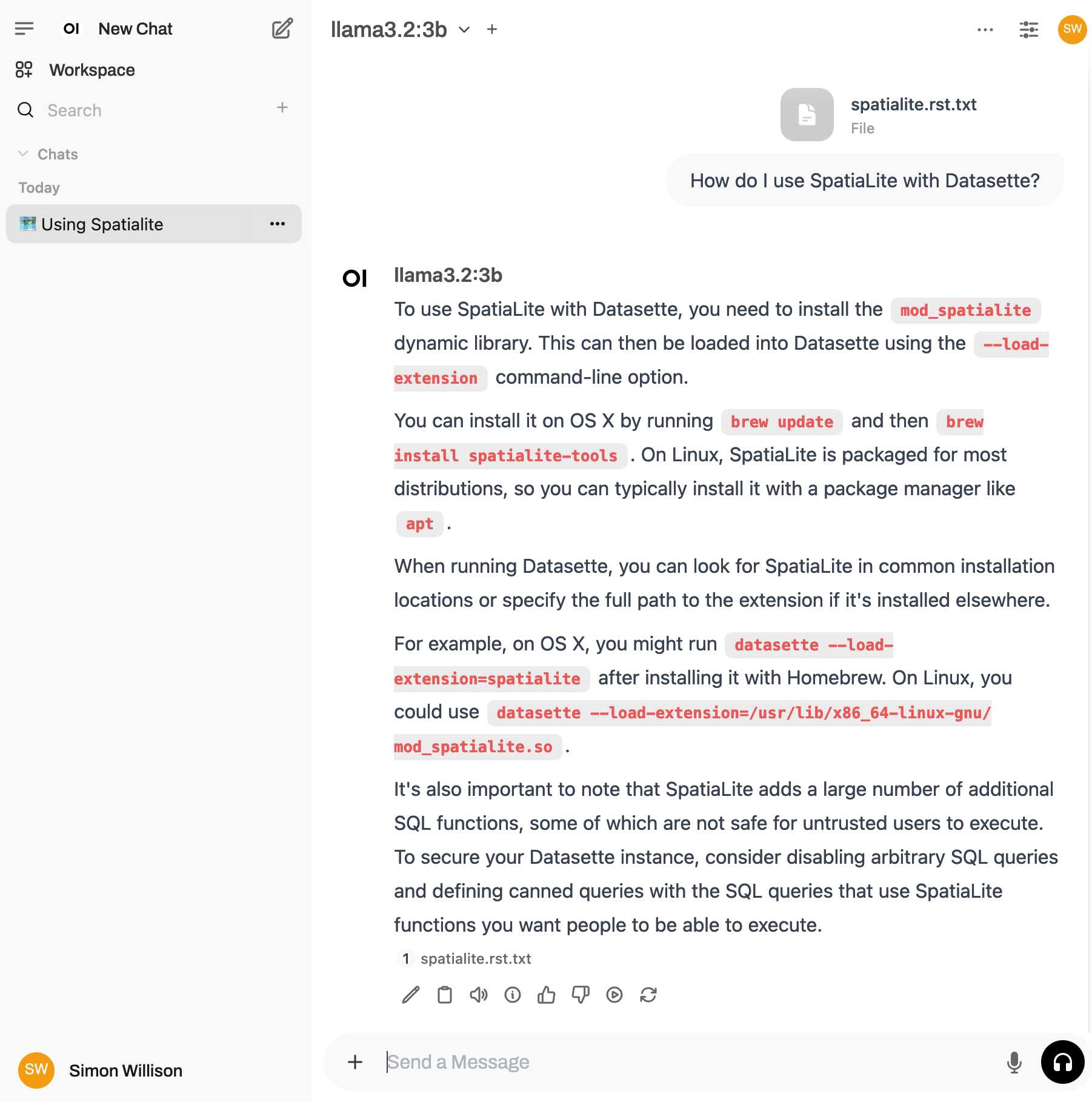
That's honestly a very solid answer, especially considering the Llama 3.2 3B model from Ollama is just a 1.9GB file! It's impressive how well that model can handle basic Q&A and summarization against text provided to it - it somehow has a 128,000 token context size.
Open WebUI has a lot of other tricks up its sleeve: it can talk to API models such as OpenAI directly, has optional integrations with web search and custom tools and logs every interaction to a SQLite database. It also comes with extensive documentation.
Trying out QvQ—Qwen’s new visual reasoning model

I thought we were done for major model releases in 2024, but apparently not: Alibaba’s Qwen team just dropped the Apache 2.0 licensed Qwen licensed (the license changed) QvQ-72B-Preview, “an experimental research model focusing on enhancing visual reasoning capabilities”.
I can now run a GPT-4 class model on my laptop

Meta’s new Llama 3.3 70B is a genuinely GPT-4 class Large Language Model that runs on my laptop.
[... 2,905 words]Meta AI release Llama 3.3. This new Llama-3.3-70B-Instruct model from Meta AI makes some bold claims:
This model delivers similar performance to Llama 3.1 405B with cost effective inference that’s feasible to run locally on common developer workstations.
I have 64GB of RAM in my M2 MacBook Pro, so I'm looking forward to trying a slightly quantized GGUF of this model to see if I can run it while still leaving some memory free for other applications.
Update: Ollama have a 43GB GGUF available now. And here's an MLX 8bit version and other MLX quantizations.
Llama 3.3 has 70B parameters, a 128,000 token context length and was trained to support English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
The model card says that the training data was "A new mix of publicly available online data" - 15 trillion tokens with a December 2023 cut-off.
They used "39.3M GPU hours of computation on H100-80GB (TDP of 700W) type hardware" which they calculate as 11,390 tons CO2eq. I believe that's equivalent to around 20 fully loaded passenger flights from New York to London (at ~550 tons per flight).
Update 19th January 2025: On further consideration I no longer trust my estimate here: it's surprisingly hard to track down reliable numbers but I think the total CO2 used by those flights may be more in the order of 200-400 tons, so my estimate for Llama 3.3 70B should have been more in the order of between 28 and 56 flights. Don't trust those numbers either though!
SmolVLM—small yet mighty Vision Language Model. I've been having fun playing with this new vision model from the Hugging Face team behind SmolLM. They describe it as:
[...] a 2B VLM, SOTA for its memory footprint. SmolVLM is small, fast, memory-efficient, and fully open-source. All model checkpoints, VLM datasets, training recipes and tools are released under the Apache 2.0 license.
I've tried it in a few flavours but my favourite so far is the mlx-vlm approach, via mlx-vlm author Prince Canuma. Here's the uv recipe I'm using to run it:
uv run \
--with mlx-vlm \
--with torch \
python -m mlx_vlm.generate \
--model mlx-community/SmolVLM-Instruct-bf16 \
--max-tokens 500 \
--temp 0.5 \
--prompt "Describe this image in detail" \
--image IMG_4414.JPG
If you run into an error using Python 3.13 (torch compatibility) try uv run --python 3.11 instead.
This one-liner installs the necessary dependencies, downloads the model (about 4.2GB, saved to ~/.cache/huggingface/hub/models--mlx-community--SmolVLM-Instruct-bf16) and executes the prompt and displays the result.
I ran that against this Pelican photo:

The model replied:
In the foreground of this photograph, a pelican is perched on a pile of rocks. The pelican’s wings are spread out, and its beak is open. There is a small bird standing on the rocks in front of the pelican. The bird has its head cocked to one side, and it seems to be looking at the pelican. To the left of the pelican is another bird, and behind the pelican are some other birds. The rocks in the background of the image are gray, and they are covered with a variety of textures. The rocks in the background appear to be wet from either rain or sea spray.
There are a few spatial mistakes in that description but the vibes are generally in the right direction.
On my 64GB M2 MacBook pro it read the prompt at 7.831 tokens/second and generated that response at an impressive 74.765 tokens/second.
QwQ: Reflect Deeply on the Boundaries of the Unknown. Brand new openly licensed (Apache 2) model from Alibaba Cloud's Qwen team, this time clearly inspired by OpenAI's work on reasoning in o1.
I love the flowery language they use to introduce the new model:
Through deep exploration and countless trials, we discovered something profound: when given time to ponder, to question, and to reflect, the model’s understanding of mathematics and programming blossoms like a flower opening to the sun. Just as a student grows wiser by carefully examining their work and learning from mistakes, our model achieves deeper insight through patient, thoughtful analysis.
It's already available through Ollama as a 20GB download. I initially ran it like this:
ollama run qwq
This downloaded the model and started an interactive chat session. I tried the classic "how many rs in strawberry?" and got this lengthy but correct answer, which concluded:
Wait, but maybe I miscounted. Let's list them: 1. s 2. t 3. r 4. a 5. w 6. b 7. e 8. r 9. r 10. y Yes, definitely three "r"s. So, the word "strawberry" contains three "r"s.
Then I switched to using LLM and the llm-ollama plugin. I tried prompting it for Python that imports CSV into SQLite:
Write a Python function import_csv(conn, url, table_name) which acceopts a connection to a SQLite databse and a URL to a CSV file and the name of a table - it then creates that table with the right columns and imports the CSV data from that URL
It thought through the different steps in detail and produced some decent looking code.
Finally, I tried this:
llm -m qwq 'Generate an SVG of a pelican riding a bicycle'
For some reason it answered in Simplified Chinese. It opened with this:
生成一个SVG图像,内容是一只鹈鹕骑着一辆自行车。这听起来挺有趣的!我需要先了解一下什么是SVG,以及如何创建这样的图像。
Which translates (using Google Translate) to:
Generate an SVG image of a pelican riding a bicycle. This sounds interesting! I need to first understand what SVG is and how to create an image like this.
It then produced a lengthy essay discussing the many aspects that go into constructing a pelican on a bicycle - full transcript here. After a full 227 seconds of constant output it produced this as the final result.

I think that's pretty good!
Quantization matters (via) What impact does quantization have on the performance of an LLM? been wondering about this for quite a while, now here are numbers from Paul Gauthier.
He ran differently quantized versions of Qwen 2.5 32B Instruct through his Aider code editing benchmark and saw a range of scores.
The original released weights (BF16) scored highest at 71.4%, with Ollama's qwen2.5-coder:32b-instruct-fp16 (a 66GB download) achieving the same score.
The quantized Ollama qwen2.5-coder:32b-instruct-q4_K_M (a 20GB download) saw a massive drop in quality, scoring just 53.4% on the same benchmark.
TextSynth Server (via) I'd missed this: Fabrice Bellard (yes, that Fabrice Bellard) has a project called TextSynth Server which he describes like this:
ts_server is a web server proposing a REST API to large language models. They can be used for example for text completion, question answering, classification, chat, translation, image generation, ...
It has the following characteristics:
- All is included in a single binary. Very few external dependencies (Python is not needed) so installation is easy.
- Supports many Transformer variants (GPT-J, GPT-NeoX, GPT-Neo, OPT, Fairseq GPT, M2M100, CodeGen, GPT2, T5, RWKV, LLAMA, Falcon, MPT, Llama 3.2, Mistral, Mixtral, Qwen2, Phi3, Whisper) and Stable Diffusion.
- [...]
Unlike many of his other notable projects (such as FFmpeg, QEMU, QuickJS) this isn't open source - in fact it's not even source available, you instead can download compiled binaries for Linux or Windows that are available for non-commercial use only.
Commercial terms are available, or you can visit textsynth.com and pre-pay for API credits which can then be used with the hosted REST API there.
This is not a new project: the earliest evidence I could find of it was this July 2019 page in the Internet Archive, which said:
Text Synth is build using the GPT-2 language model released by OpenAI. [...] This implementation is original because instead of using a GPU, it runs using only 4 cores of a Xeon E5-2640 v3 CPU at 2.60GHz. With a single user, it generates 40 words per second. It is programmed in plain C using the LibNC library.
NuExtract 1.5. Structured extraction - where an LLM helps turn unstructured text (or image content) into structured data - remains one of the most directly useful applications of LLMs.
NuExtract is a family of small models directly trained for this purpose (though text only at the moment) and released under the MIT license.
It comes in a variety of shapes and sizes:
- NuExtract-v1.5 is a 3.8B parameter model fine-tuned on Phi-3.5-mini instruct. You can try this one out in this playground.
- NuExtract-tiny-v1.5 is 494M parameters, fine-tuned on Qwen2.5-0.5B.
- NuExtract-1.5-smol is 1.7B parameters, fine-tuned on SmolLM2-1.7B.
All three models were fine-tuned on NuMind's "private high-quality dataset". It's interesting to see a model family that uses one fine-tuning set against three completely different base models.
Useful tip from Steffen Röcker:
Make sure to use it with low temperature, I've uploaded NuExtract-tiny-v1.5 to Ollama and set it to 0. With the Ollama default of 0.7 it started repeating the input text. It works really well despite being so smol.
Ollama: Llama 3.2 Vision. Ollama released version 0.4 last week with support for Meta's first Llama vision model, Llama 3.2.
If you have Ollama installed you can fetch the 11B model (7.9 GB) like this:
ollama pull llama3.2-vision
Or the larger 90B model (55GB download, likely needs ~88GB of RAM) like this:
ollama pull llama3.2-vision:90b
I was delighted to learn that Sukhbinder Singh had already contributed support for LLM attachments to Sergey Alexandrov's llm-ollama plugin, which means the following works once you've pulled the models:
llm install --upgrade llm-ollama
llm -m llama3.2-vision:latest 'describe' \
-a https://static.simonwillison.net/static/2024/pelican.jpg
This image features a brown pelican standing on rocks, facing the camera and positioned to the left of center. The bird's long beak is a light brown color with a darker tip, while its white neck is adorned with gray feathers that continue down to its body. Its legs are also gray.
In the background, out-of-focus boats and water are visible, providing context for the pelican's environment.

That's not a bad description of this image, especially for a 7.9GB model that runs happily on my MacBook Pro.
Qwen2.5-Coder-32B is an LLM that can code well that runs on my Mac
There’s a whole lot of buzz around the new Qwen2.5-Coder Series of open source (Apache 2.0 licensed) LLM releases from Alibaba’s Qwen research team. On first impression it looks like the buzz is well deserved.
[... 697 words]Everything I’ve learned so far about running local LLMs (via) Chris Wellons shares detailed notes on his experience running local LLMs on Windows - though most of these tips apply to other operating systems as well.
This is great, there's a ton of detail here and the root recommendations are very solid: Use llama-server from llama.cpp and try ~8B models first (Chris likes Llama 3.1 8B Instruct at Q4_K_M as a first model), anything over 10B probably won't run well on a CPU so you'll need to consider your available GPU VRAM.
This is neat:
Just for fun, I ported llama.cpp to Windows XP and ran a 360M model on a 2008-era laptop. It was magical to load that old laptop with technology that, at the time it was new, would have been worth billions of dollars.
I need to spend more time with Chris's favourite models, Mistral-Nemo-2407 (12B) and Qwen2.5-14B/72B.
Chris also built illume, a Go CLI tool for interacting with models that looks similar to my own LLM project.
Nous Hermes 3. The Nous Hermes family of fine-tuned models have a solid reputation. Their most recent release came out in August, based on Meta's Llama 3.1:
Our training data aggressively encourages the model to follow the system and instruction prompts exactly and in an adaptive manner. Hermes 3 was created by fine-tuning Llama 3.1 8B, 70B and 405B, and training on a dataset of primarily synthetically generated responses. The model boasts comparable and superior performance to Llama 3.1 while unlocking deeper capabilities in reasoning and creativity.
The model weights are on Hugging Face, including GGUF versions of the 70B and 8B models. Here's how to try the 8B model (a 4.58GB download) using the llm-gguf plugin:
llm install llm-gguf
llm gguf download-model 'https://huggingface.co/NousResearch/Hermes-3-Llama-3.1-8B-GGUF/resolve/main/Hermes-3-Llama-3.1-8B.Q4_K_M.gguf' -a Hermes-3-Llama-3.1-8B
llm -m Hermes-3-Llama-3.1-8B 'hello in spanish'
Nous Research partnered with Lambda Labs to provide inference APIs. It turns out Lambda host quite a few models now, currently providing free inference to users with an API key.
I just released the first alpha of a llm-lambda-labs plugin. You can use that to try the larger 405b model (very hard to run on a consumer device) like this:
llm install llm-lambda-labs
llm keys set lambdalabs
# Paste key here
llm -m lambdalabs/hermes3-405b 'short poem about a pelican with a twist'
Here's the source code for the new plugin, which I based on llm-mistral. The plugin uses httpx-sse to consume the stream of tokens from the API.
SmolLM2 (via) New from Loubna Ben Allal and her research team at Hugging Face:
SmolLM2 is a family of compact language models available in three size: 135M, 360M, and 1.7B parameters. They are capable of solving a wide range of tasks while being lightweight enough to run on-device. [...]
It was trained on 11 trillion tokens using a diverse dataset combination: FineWeb-Edu, DCLM, The Stack, along with new mathematics and coding datasets that we curated and will release soon.
The model weights are released under an Apache 2 license. I've been trying these out using my llm-gguf plugin for LLM and my first impressions are really positive.
Here's a recipe to run a 1.7GB Q8 quantized model from lmstudio-community:
llm install llm-gguf
llm gguf download-model https://huggingface.co/lmstudio-community/SmolLM2-1.7B-Instruct-GGUF/resolve/main/SmolLM2-1.7B-Instruct-Q8_0.gguf -a smol17
llm chat -m smol17
Or at the other end of the scale, here's how to run the 138MB Q8 quantized 135M model:
llm gguf download-model https://huggingface.co/lmstudio-community/SmolLM2-135M-Instruct-GGUF/resolve/main/SmolLM2-135M-Instruct-Q8_0.gguf' -a smol135m
llm chat -m smol135m
The blog entry to accompany SmolLM2 should be coming soon, but in the meantime here's the entry from July introducing the first version: SmolLM - blazingly fast and remarkably powerful .
You can now run prompts against images, audio and video in your terminal using LLM
I released LLM 0.17 last night, the latest version of my combined CLI tool and Python library for interacting with hundreds of different Large Language Models such as GPT-4o, Llama, Claude and Gemini.
[... 1,399 words]Running Llama 3.2 Vision and Phi-3.5 Vision on a Mac with mistral.rs
mistral.rs is an LLM inference library written in Rust by Eric Buehler. Today I figured out how to use it to run the Llama 3.2 Vision and Phi-3.5 Vision models on my Mac.
[... 1,231 words]Un Ministral, des Ministraux (via) Two new models from Mistral: Ministral 3B and Ministral 8B - joining Mixtral, Pixtral, Codestral and Mathstral as weird naming variants on the Mistral theme.
These models set a new frontier in knowledge, commonsense, reasoning, function-calling, and efficiency in the sub-10B category, and can be used or tuned to a variety of uses, from orchestrating agentic workflows to creating specialist task workers. Both models support up to 128k context length (currently 32k on vLLM) and Ministral 8B has a special interleaved sliding-window attention pattern for faster and memory-efficient inference.
Mistral's own benchmarks look impressive, but it's hard to get excited about small on-device models with a non-commercial Mistral Research License (for the 8B) and a contact-us-for-pricing Mistral Commercial License (for the 8B and 3B), given the existence of the extremely high quality Llama 3.1 and 3.2 series of models.
These new models are also available through Mistral's la Plateforme API, priced at $0.1/million tokens (input and output) for the 8B and $0.04/million tokens for the 3B.
The latest release of my llm-mistral plugin for LLM adds aliases for the new models. Previously you could access them like this:
llm mistral refresh # To fetch new models
llm -m mistral/ministral-3b-latest "a poem about pelicans at the park"
llm -m mistral/ministral-8b-latest "a poem about a pelican in french"
With the latest plugin version you can do this:
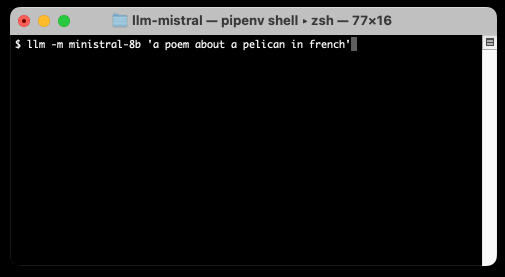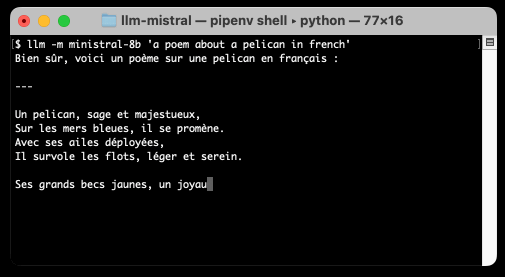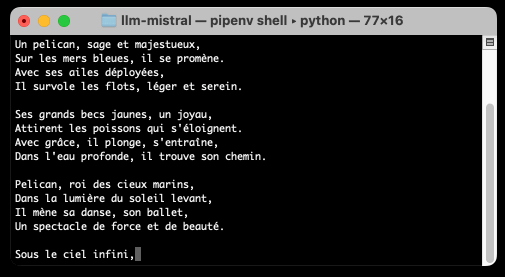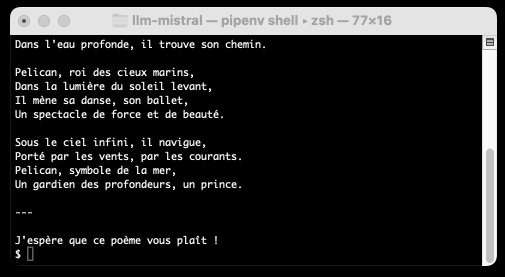
llm install -U llm-mistral
llm -m ministral-8b "a poem about a pelican in french"
mlx-vlm (via) The MLX ecosystem of libraries for running machine learning models on Apple Silicon continues to expand. Prince Canuma is actively developing this library for running vision models such as Qwen-2 VL and Pixtral and LLaVA using Python running on a Mac.
I used uv to run it against this image with this shell one-liner:
uv run --with mlx-vlm \
python -m mlx_vlm.generate \
--model Qwen/Qwen2-VL-2B-Instruct \
--max-tokens 1000 \
--temp 0.0 \
--image https://static.simonwillison.net/static/2024/django-roadmap.png \
--prompt "Describe image in detail, include all text"
The --image option works equally well with a URL or a path to a local file on disk.
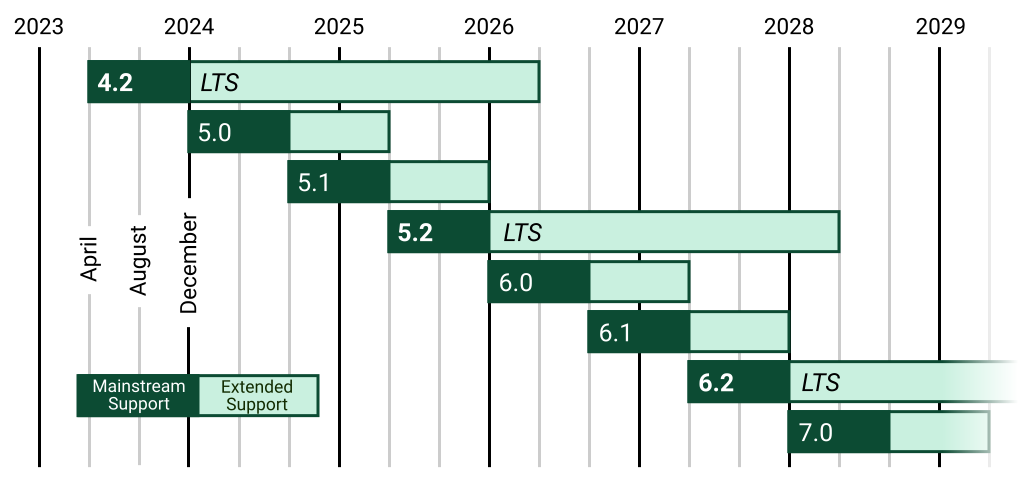
This first downloaded 4.1GB to my ~/.cache/huggingface/hub/models--Qwen--Qwen2-VL-2B-Instruct folder and then output this result, which starts:
The image is a horizontal timeline chart that represents the release dates of various software versions. The timeline is divided into years from 2023 to 2029, with each year represented by a vertical line. The chart includes a legend at the bottom, which distinguishes between different types of software versions.
Legend
Mainstream Support:
- 4.2 (2023)
- 5.0 (2024)
- 5.1 (2025)
- 5.2 (2026)
- 6.0 (2027) [...]