158 posts tagged “local-llms”
LLMs that can run on consumer hardware like laptops or mobile phones.
2024
Llama 3.2. In further evidence that AI labs are terrible at naming things, Llama 3.2 is a huge upgrade to the Llama 3 series - they've released their first multi-modal vision models!
Today, we’re releasing Llama 3.2, which includes small and medium-sized vision LLMs (11B and 90B), and lightweight, text-only models (1B and 3B) that fit onto edge and mobile devices, including pre-trained and instruction-tuned versions.
The 1B and 3B text-only models are exciting too, with a 128,000 token context length and optimized for edge devices (Qualcomm and MediaTek hardware get called out specifically).
Meta partnered directly with Ollama to help with distribution, here's the Ollama blog post. They only support the two smaller text-only models at the moment - this command will get the 3B model (2GB):
ollama run llama3.2
And for the 1B model (a 1.3GB download):
ollama run llama3.2:1b
I had to first upgrade my Ollama by clicking on the icon in my macOS task tray and selecting "Restart to update".
The two vision models are coming to Ollama "very soon".
Once you have fetched the Ollama model you can access it from my LLM command-line tool like this:
pipx install llm
llm install llm-ollama
llm chat -m llama3.2:1b
I tried running my djp codebase through that tiny 1B model just now and got a surprisingly good result - by no means comprehensive, but way better than I would ever expect from a model of that size:
files-to-prompt **/*.py -c | llm -m llama3.2:1b --system 'describe this code'
Here's a portion of the output:
The first section defines several test functions using the
@djp.hookimpldecorator from the djp library. These hook implementations allow you to intercept and manipulate Django's behavior.
test_middleware_order: This function checks that the middleware order is correct by comparing theMIDDLEWAREsetting with a predefined list.test_middleware: This function tests various aspects of middleware:- It retrieves the response from the URL
/from-plugin/using theClientobject, which simulates a request to this view.- It checks that certain values are present in the response:
X-DJP-Middleware-AfterX-DJP-MiddlewareX-DJP-Middleware-Before[...]
I found the GGUF file that had been downloaded by Ollama in my ~/.ollama/models/blobs directory. The following command let me run that model directly in LLM using the llm-gguf plugin:
llm install llm-gguf
llm gguf register-model ~/.ollama/models/blobs/sha256-74701a8c35f6c8d9a4b91f3f3497643001d63e0c7a84e085bed452548fa88d45 -a llama321b
llm chat -m llama321b
Meta themselves claim impressive performance against other existing models:
Our evaluation suggests that the Llama 3.2 vision models are competitive with leading foundation models, Claude 3 Haiku and GPT4o-mini on image recognition and a range of visual understanding tasks. The 3B model outperforms the Gemma 2 2.6B and Phi 3.5-mini models on tasks such as following instructions, summarization, prompt rewriting, and tool-use, while the 1B is competitive with Gemma.
Here's the Llama 3.2 collection on Hugging Face. You need to accept the new Llama 3.2 Community License Agreement there in order to download those models.
You can try the four new models out via the Chatbot Arena - navigate to "Direct Chat" there and select them from the dropdown menu. You can upload images directly to the chat there to try out the vision features.
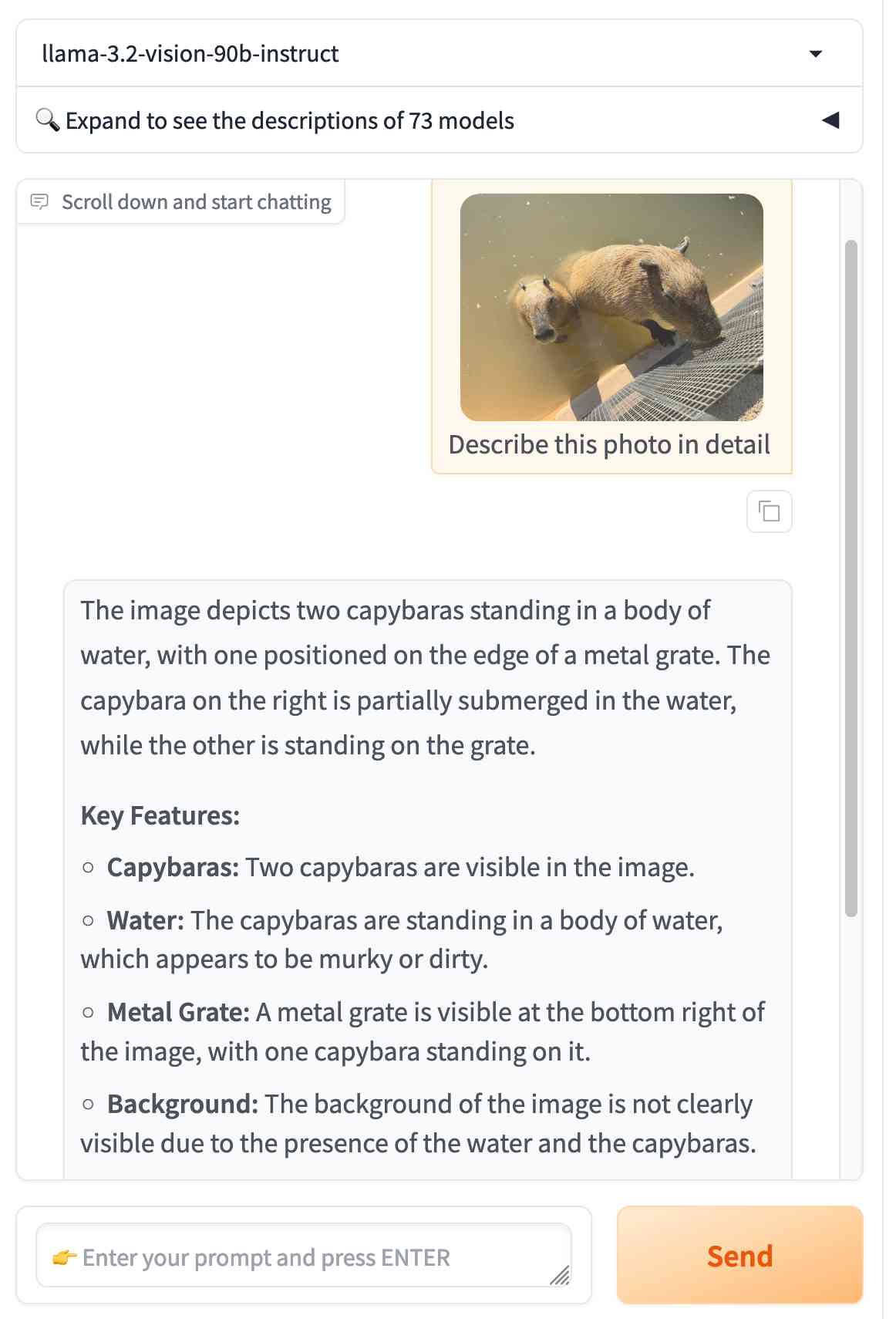
Pixtral 12B. Mistral finally have a multi-modal (image + text) vision LLM!
I linked to their tweet, but there’s not much to see there - in now classic Mistral style they released the new model with an otherwise unlabeled link to a torrent download. A more useful link is mistral-community/pixtral-12b-240910 on Hugging Face, a 25GB “Unofficial Mistral Community” copy of the weights.
Pixtral was announced at Mistral’s AI Summit event in San Francisco today. It has 128,000 token context, is Apache 2.0 licensed and handles 1024x1024 pixel images. They claim it’s particularly good for OCR and information extraction. It’s not available on their La Platforme hosted API yet, but that’s coming soon.
A few more details can be found in the release notes for mistral-common 1.4.0. That’s their open source library of code for working with the models - it doesn’t actually run inference, but it includes the all-important tokenizer, which now includes three new special tokens: [IMG], [IMG_BREAK] and [IMG_END].
Qwen2-VL: To See the World More Clearly. Qwen is Alibaba Cloud's organization training LLMs. Their latest model is Qwen2-VL - a vision LLM - and it's getting some really positive buzz. Here's a r/LocalLLaMA thread about the model.
The original Qwen models were licensed under their custom Tongyi Qianwen license, but starting with Qwen2 on June 7th 2024 they switched to Apache 2.0, at least for their smaller models:
While Qwen2-72B as well as its instruction-tuned models still uses the original Qianwen License, all other models, including Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, and Qwen2-57B-A14B, turn to adopt Apache 2.0
Here's where things get odd: shortly before I first published this post the Qwen GitHub organization, and their GitHub pages hosted blog, both disappeared and returned 404s pages. I asked on Twitter but nobody seems to know what's happened to them.
Update: this was accidental and was resolved on 5th September.
The Qwen Hugging Face page is still up - it's just the GitHub organization that has mysteriously vanished.
Inspired by Dylan Freedman I tried the model using GanymedeNil/Qwen2-VL-7B on Hugging Face Spaces, and found that it was exceptionally good at extracting text from unruly handwriting:
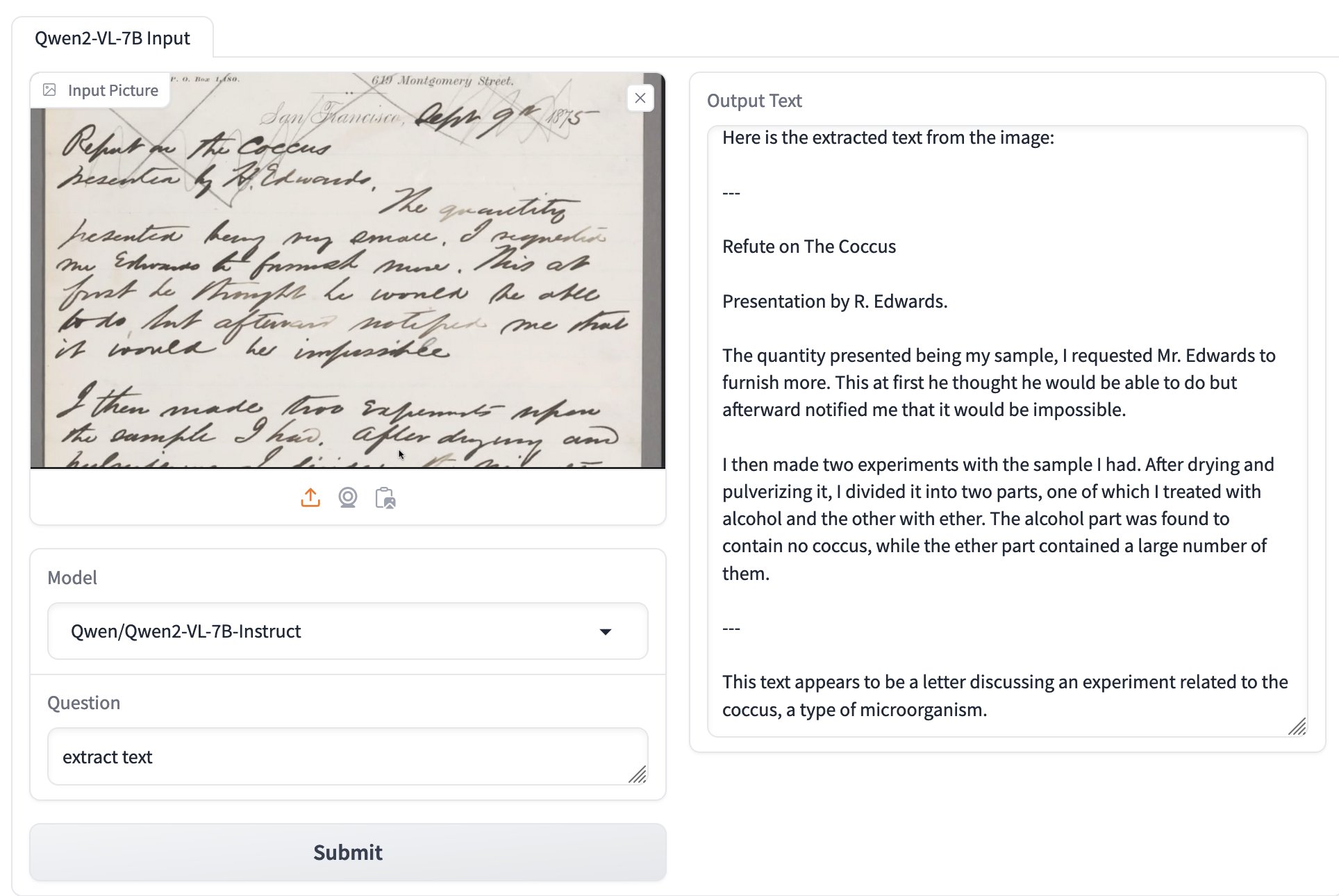
The model apparently runs great on NVIDIA GPUs, and very slowly using the MPS PyTorch backend on Apple Silicon. Qwen previously released MLX builds of their non-vision Qwen2 models, so hopefully there will be an Apple Silicon optimized MLX model for Qwen2-VL soon as well.
llamafile v0.8.13 (and whisperfile)
(via)
The latest release of llamafile (previously) adds support for Gemma 2B (pre-bundled llamafiles available here), significant performance improvements and new support for the Whisper speech-to-text model, based on whisper.cpp, Georgi Gerganov's C++ implementation of Whisper that pre-dates his work on llama.cpp.
I got whisperfile working locally by first downloading the cross-platform executable attached to the GitHub release and then grabbing a whisper-tiny.en-q5_1.bin model from Hugging Face:
wget -O whisper-tiny.en-q5_1.bin \
https://huggingface.co/ggerganov/whisper.cpp/resolve/main/ggml-tiny.en-q5_1.bin
Then I ran chmod 755 whisperfile-0.8.13 and then executed it against an example .wav file like this:
./whisperfile-0.8.13 -m whisper-tiny.en-q5_1.bin -f raven_poe_64kb.wav --no-prints
The --no-prints option suppresses the debug output, so you just get text that looks like this:
[00:00:00.000 --> 00:00:12.000] This is a LibraVox recording. All LibraVox recordings are in the public domain. For more information please visit LibraVox.org.
[00:00:12.000 --> 00:00:20.000] Today's reading The Raven by Edgar Allan Poe, read by Chris Scurringe.
[00:00:20.000 --> 00:00:40.000] Once upon a midnight dreary, while I pondered weak and weary, over many a quaint and curious volume of forgotten lore. While I nodded nearly napping, suddenly there came a tapping as of someone gently rapping, rapping at my chamber door.
There are quite a few undocumented options - to write out JSON to a file called transcript.json (example output):
./whisperfile-0.8.13 -m whisper-tiny.en-q5_1.bin -f /tmp/raven_poe_64kb.wav --no-prints --output-json --output-file transcript
I had to convert my own audio recordings to 16kHz .wav files in order to use them with whisperfile. I used ffmpeg to do this:
ffmpeg -i runthrough-26-oct-2023.wav -ar 16000 /tmp/out.wav
Then I could transcribe that like so:
./whisperfile-0.8.13 -m whisper-tiny.en-q5_1.bin -f /tmp/out.wav --no-prints
Update: Justine says:
I've just uploaded new whisperfiles to Hugging Face which use miniaudio.h to automatically resample and convert your mp3/ogg/flac/wav files to the appropriate format.
With that whisper-tiny model this took just 11s to transcribe a 10m41s audio file!
I also tried the much larger Whisper Medium model - I chose to use the 539MB ggml-medium-q5_0.bin quantized version of that from huggingface.co/ggerganov/whisper.cpp:
./whisperfile-0.8.13 -m ggml-medium-q5_0.bin -f out.wav --no-prints
This time it took 1m49s, using 761% of CPU according to Activity Monitor.
I tried adding --gpu auto to exercise the GPU on my M2 Max MacBook Pro:
./whisperfile-0.8.13 -m ggml-medium-q5_0.bin -f out.wav --no-prints --gpu auto
That used just 16.9% of CPU and 93% of GPU according to Activity Monitor, and finished in 1m08s.
I tried this with the tiny model too but the performance difference there was imperceptible.
Mistral Large 2 (via) The second release of a GPT-4 class open weights model in two days, after yesterday's Llama 3.1 405B.
The weights for this one are under Mistral's Research License, which "allows usage and modification for research and non-commercial usages" - so not as open as Llama 3.1. You can use it commercially via the Mistral paid API.
Mistral Large 2 is 123 billion parameters, "designed for single-node inference" (on a very expensive single-node!) and has a 128,000 token context window, the same size as Llama 3.1.
Notably, according to Mistral's own benchmarks it out-performs the much larger Llama 3.1 405B on their code and math benchmarks. They trained on a lot of code:
Following our experience with Codestral 22B and Codestral Mamba, we trained Mistral Large 2 on a very large proportion of code. Mistral Large 2 vastly outperforms the previous Mistral Large, and performs on par with leading models such as GPT-4o, Claude 3 Opus, and Llama 3 405B.
They also invested effort in tool usage, multilingual support (across English, French, German, Spanish, Italian, Portuguese, Dutch, Russian, Chinese, Japanese, Korean, Arabic, and Hindi) and reducing hallucinations:
One of the key focus areas during training was to minimize the model’s tendency to “hallucinate” or generate plausible-sounding but factually incorrect or irrelevant information. This was achieved by fine-tuning the model to be more cautious and discerning in its responses, ensuring that it provides reliable and accurate outputs.
Additionally, the new Mistral Large 2 is trained to acknowledge when it cannot find solutions or does not have sufficient information to provide a confident answer.
I went to update my llm-mistral plugin for LLM to support the new model and found that I didn't need to - that plugin already uses llm -m mistral-large to access the mistral-large-latest endpoint, and Mistral have updated that to point to the latest version of their Large model.
Ollama now have mistral-large quantized to 4 bit as a 69GB download.
Mistral NeMo. Released by Mistral today: "Our new best small model. A state-of-the-art 12B model with 128k context length, built in collaboration with NVIDIA, and released under the Apache 2.0 license."
Nice to see Mistral use Apache 2.0 for this, unlike their Codestral 22B release - though Codestral Mamba was Apache 2.0 as well.
Mistral's own benchmarks put NeMo slightly ahead of the smaller (but same general weight class) Gemma 2 9B and Llama 3 8B models.
It's both multi-lingual and trained for tool usage:
The model is designed for global, multilingual applications. It is trained on function calling, has a large context window, and is particularly strong in English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic, and Hindi.
Part of this is down to the new Tekken tokenizer, which is 30% more efficient at representing both source code and most of the above listed languages.
You can try it out via Mistral's API using llm-mistral like this:
pipx install llm
llm install llm-mistral
llm keys set mistral
# paste La Plateforme API key here
llm mistral refresh # if you installed the plugin before
llm -m mistral/open-mistral-nemo 'Rave about pelicans in French'
Codestral Mamba. New 7B parameter LLM from Mistral, released today. Codestral Mamba is "a Mamba2 language model specialised in code generation, available under an Apache 2.0 license".
This the first model from Mistral that uses the Mamba architecture, as opposed to the much more common Transformers architecture. Mistral say that Mamba can offer faster responses irrespective of input length which makes it ideal for code auto-completion, hence why they chose to specialise the model in code.
It's available to run locally with the mistral-inference GPU library, and Mistral say "For local inference, keep an eye out for support in llama.cpp" (relevant issue).
It's also available through Mistral's La Plateforme API. I just shipped llm-mistral 0.4 adding a llm -m codestral-mamba "prompt goes here" default alias for the new model.
Also released today: MathΣtral, a 7B Apache 2 licensed model "designed for math reasoning and scientific discovery", with a 32,000 context window. This one isn't available through their API yet, but the weights are available on Hugging Face.
gemma-2-27b-it-llamafile (via) Justine Tunney shipped llamafile packages of Google's new openly licensed (though definitely not open source) Gemma 2 27b model this morning.
I downloaded the gemma-2-27b-it.Q5_1.llamafile version (20.5GB) to my Mac, ran chmod 755 gemma-2-27b-it.Q5_1.llamafile and then ./gemma-2-27b-it.Q5_1.llamafile and now I'm trying it out through the llama.cpp default web UI in my browser. It works great.
It's a very capable model - currently sitting at position 12 on the LMSYS Arena making it the highest ranked open weights model - one position ahead of Llama-3-70b-Instruct and within striking distance of the GPT-4 class models.
Language models on the command-line
I gave a talk about accessing Large Language Models from the command-line last week as part of the Mastering LLMs: A Conference For Developers & Data Scientists six week long online conference. The talk focused on my LLM Python command-line utility and ways you can use it (and its plugins) to explore LLMs and use them for useful tasks.
[... 4,992 words]Introducing Apple’s On-Device and Server Foundation Models. Apple Intelligence uses both on-device and in-the-cloud models that were trained from scratch by Apple.
Their on-device model is a 3B model that "outperforms larger models including Phi-3-mini, Mistral-7B, and Gemma-7B", while the larger cloud model is comparable to GPT-3.5.
The language models were trained on unlicensed scraped data - I was hoping they might have managed to avoid that, but sadly not:
We train our foundation models on licensed data, including data selected to enhance specific features, as well as publicly available data collected by our web-crawler, AppleBot.
The most interesting thing here is the way they apply fine-tuning to the local model to specialize it for different tasks. Apple call these "adapters", and they use LoRA for this - a technique first published in 2021. This lets them run multiple on-device models based on a shared foundation, specializing in tasks such as summarization and proof-reading.
Here's the section of the Platforms State of the Union talk that talks about the foundation models and their fine-tuned variants.
As Hamel Husain says:
This talk from Apple is the best ad for fine tuning that probably exists.
The video also describes their approach to quantization:
The next step we took is compressing the model. We leveraged state-of-the-art quantization techniques to take a 16-bit per parameter model down to an average of less than 4 bits per parameter to fit on Apple Intelligence-supported devices, all while maintaining model quality.
Still no news on how their on-device image model was trained. I'd love to find out it was trained exclusively using licensed imagery - Apple struck a deal with Shutterstock a few months ago.
Ultravox (via) Ultravox is "a multimodal Speech LLM built around a pretrained Whisper and Llama 3 backbone". It's effectively an openly licensed version of half of the GPT-4o model OpenAI demoed (but did not fully release) a few weeks ago: Ultravox is multimodal for audio input, but still relies on a separate text-to-speech engine for audio output.
You can try it out directly in your browser through this page on AI.TOWN - hit the "Call" button to start an in-browser voice conversation with the model.
I found the demo extremely impressive - really low latency and it was fun and engaging to talk to. Try saying "pretend to be a wise and sarcastic old fox" to kick it into a different personality.
The GitHub repo includes code for both training and inference, and the full model is available from Hugging Face - about 30GB of .safetensors files.
Ultravox says it's licensed under MIT, but I would expect it to also have to inherit aspects of the Llama 3 license since it uses that as a base model.
PaliGemma model README (via) One of the more over-looked announcements from Google I/O yesterday was PaliGemma, an openly licensed VLM (Vision Language Model) in the Gemma family of models.
The model accepts an image and a text prompt. It outputs text, but that text can include special tokens representing regions on the image. This means it can return both bounding boxes and fuzzier segment outlines of detected objects, behavior that can be triggered using a prompt such as "segment puffins".
From the README:
PaliGemma uses the Gemma tokenizer with 256,000 tokens, but we further extend its vocabulary with 1024 entries that represent coordinates in normalized image-space (
<loc0000>...<loc1023>), and another with 128 entries (<seg000>...<seg127>) that are codewords used by a lightweight referring-expression segmentation vector-quantized variational auto-encoder (VQ-VAE) [...]
You can try it out on Hugging Face.
It's a 3B model, making it feasible to run on consumer hardware.
experimental-phi3-webgpu (via) Run Microsoft’s excellent Phi-3 model directly in your browser, using WebGPU so didn’t work in Firefox for me, just in Chrome.
It fetches around 2.1GB of data into the browser cache on first run, but then gave me decent quality responses to my prompts running at an impressive 21 tokens a second (M2, 64GB).
I think Phi-3 is the highest quality model of this size, so it’s a really good fit for running in a browser like this.
microsoft/Phi-3-mini-4k-instruct-gguf (via) Microsoft’s Phi-3 LLM is out and it’s really impressive. This 4,000 token context GGUF model is just a 2.2GB (for the Q4 version) and ran on my Mac using the llamafile option described in the README. I could then run prompts through it using the llm-llamafile plugin.
The vibes are good! Initial test prompts I’ve tried feel similar to much larger 7B models, despite using just a few GBs of RAM. Tokens are returned fast too—it feels like the fastest model I’ve tried yet.
And it’s MIT licensed.
We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone.
Options for accessing Llama 3 from the terminal using LLM
Llama 3 was released on Thursday. Early indications are that it’s now the best available openly licensed model—Llama 3 70b Instruct has taken joint 5th place on the LMSYS arena leaderboard, behind only Claude 3 Opus and some GPT-4s and sharing 5th place with Gemini Pro and Claude 3 Sonnet. But unlike those other models Llama 3 70b is weights available and can even be run on a (high end) laptop!
[... 1,962 words]llm-gpt4all. New release of my LLM plugin which builds on Nomic's excellent gpt4all Python library. I've upgraded to their latest version which adds support for Llama 3 8B Instruct, so after a 4.4GB model download this works:
llm -m Meta-Llama-3-8B-Instruct "say hi in Spanish"
Mistral tweet a magnet link for mixtral-8x22b. Another open model release from Mistral using their now standard operating procedure of tweeting out a raw torrent link.
This one is an 8x22B Mixture of Experts model. Their previous most powerful openly licensed release was Mixtral 8x7B, so this one is a whole lot bigger (a 281GB download)—and apparently has a 65,536 context length, at least according to initial rumors on Twitter.
Gemma: Introducing new state-of-the-art open models. Google get in on the openly licensed LLM game: Gemma comes in two sizes, 2B and 7B, trained on 2 trillion and 6 trillion tokens respectively. The terms of use “permit responsible commercial usage”. In the benchmarks it appears to compare favorably to Mistral and Llama 2.
Something that caught my eye in the terms: “Google may update Gemma from time to time, and you must make reasonable efforts to use the latest version of Gemma.”
One of the biggest benefits of running your own model is that it can protect you from model updates that break your carefully tested prompts, so I’m not thrilled by that particular clause.
UPDATE: It turns out that clause isn’t uncommon—the phrase “You shall undertake reasonable efforts to use the latest version of the Model” is present in both the Stable Diffusion and BigScience Open RAIL-M licenses.
Mixtral of Experts. The Mixtral paper is out, exactly a month after the release of the Mixtral 8x7B model itself. Thanks to the paper I now have a reasonable understanding of how a mixture of experts model works: each layer has 8 available blocks, but a router model selects two out of those eight for each token passing through that layer and combines their output. “As a result, each token has access to 47B parameters, but only uses 13B active parameters during inference.”
The Mixtral token context size is an impressive 32k, and it compares extremely well against the much larger Llama 70B across a whole array of benchmarks.
Unsurprising but disappointing: there’s nothing in the paper at all about what it was trained on.
2023
Many options for running Mistral models in your terminal using LLM
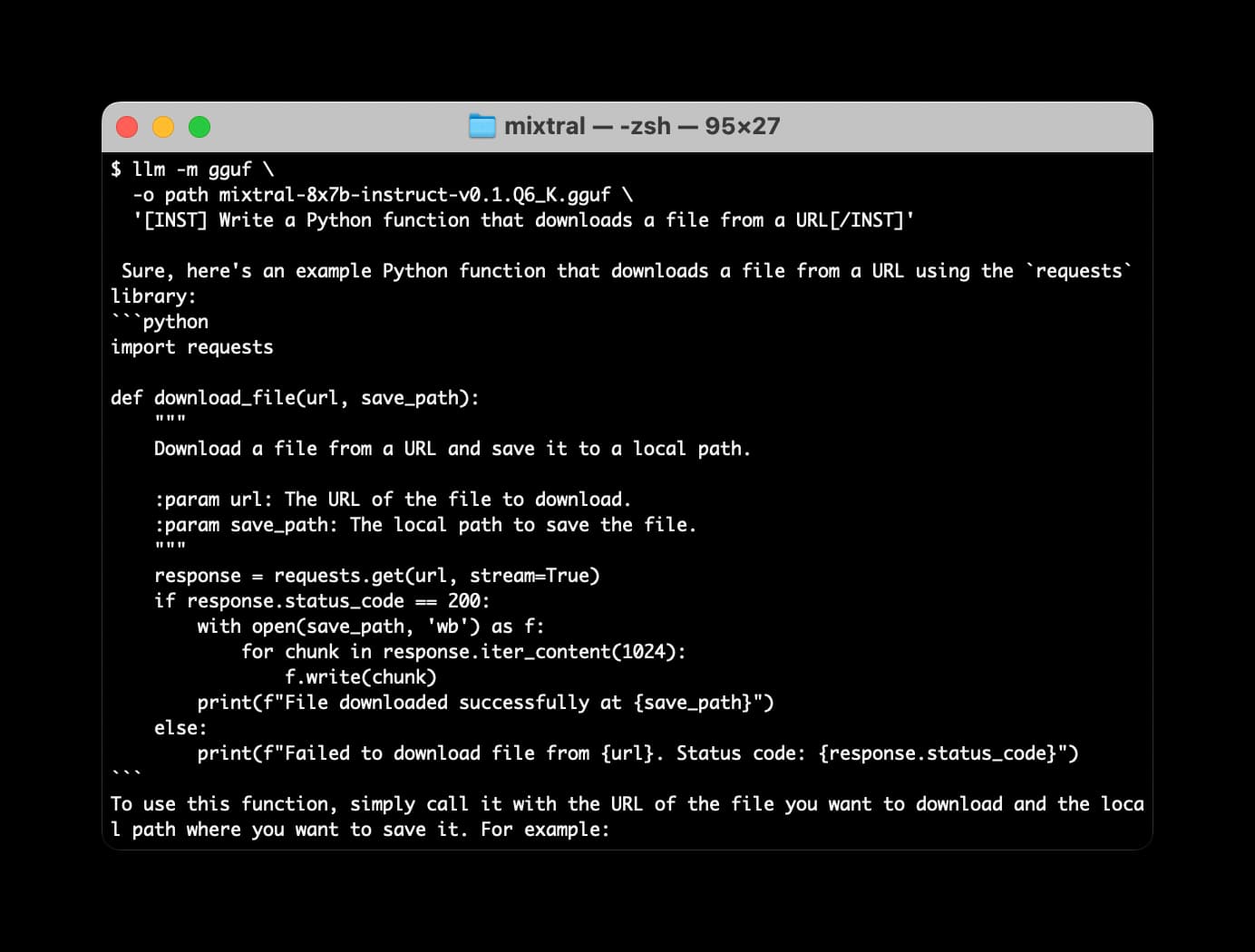
Mistral AI is the most exciting AI research lab at the moment. They’ve now released two extremely powerful smaller Large Language Models under an Apache 2 license, and have a third much larger one that’s available via their API.
[... 2,063 words]The AI trust crisis
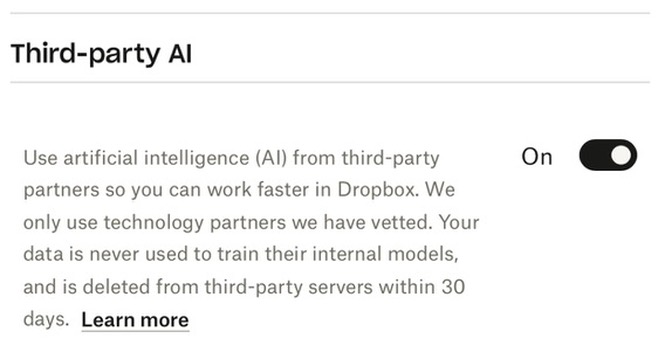
Dropbox added some new AI features. In the past couple of days these have attracted a firestorm of criticism. Benj Edwards rounds it up in Dropbox spooks users with new AI features that send data to OpenAI when used.
[... 1,733 words]Mixtral of experts (via) Mistral have firmly established themselves as the most exciting AI lab outside of OpenAI, arguably more exciting because much of their work is released under open licenses.
On December 8th they tweeted a link to a torrent, with no additional context (a neat marketing trick they’ve used in the past). The 87GB torrent contained a new model, Mixtral-8x7b-32kseqlen—a Mixture of Experts.
Three days later they published a full write-up, describing “Mixtral 8x7B, a high-quality sparse mixture of experts model (SMoE) with open weights”—licensed Apache 2.0.
They claim “Mixtral outperforms Llama 2 70B on most benchmarks with 6x faster inference”—and that it outperforms GPT-3.5 on most benchmarks too.
This isn’t even their current best model. The new Mistral API platform (currently on a waitlist) refers to Mixtral as “Mistral-small” (and their previous 7B model as “Mistral-tiny”—and also provides access to a currently closed model, “Mistral-medium”, which they claim to be competitive with GPT-4.
llamafile is the new best way to run an LLM on your own computer
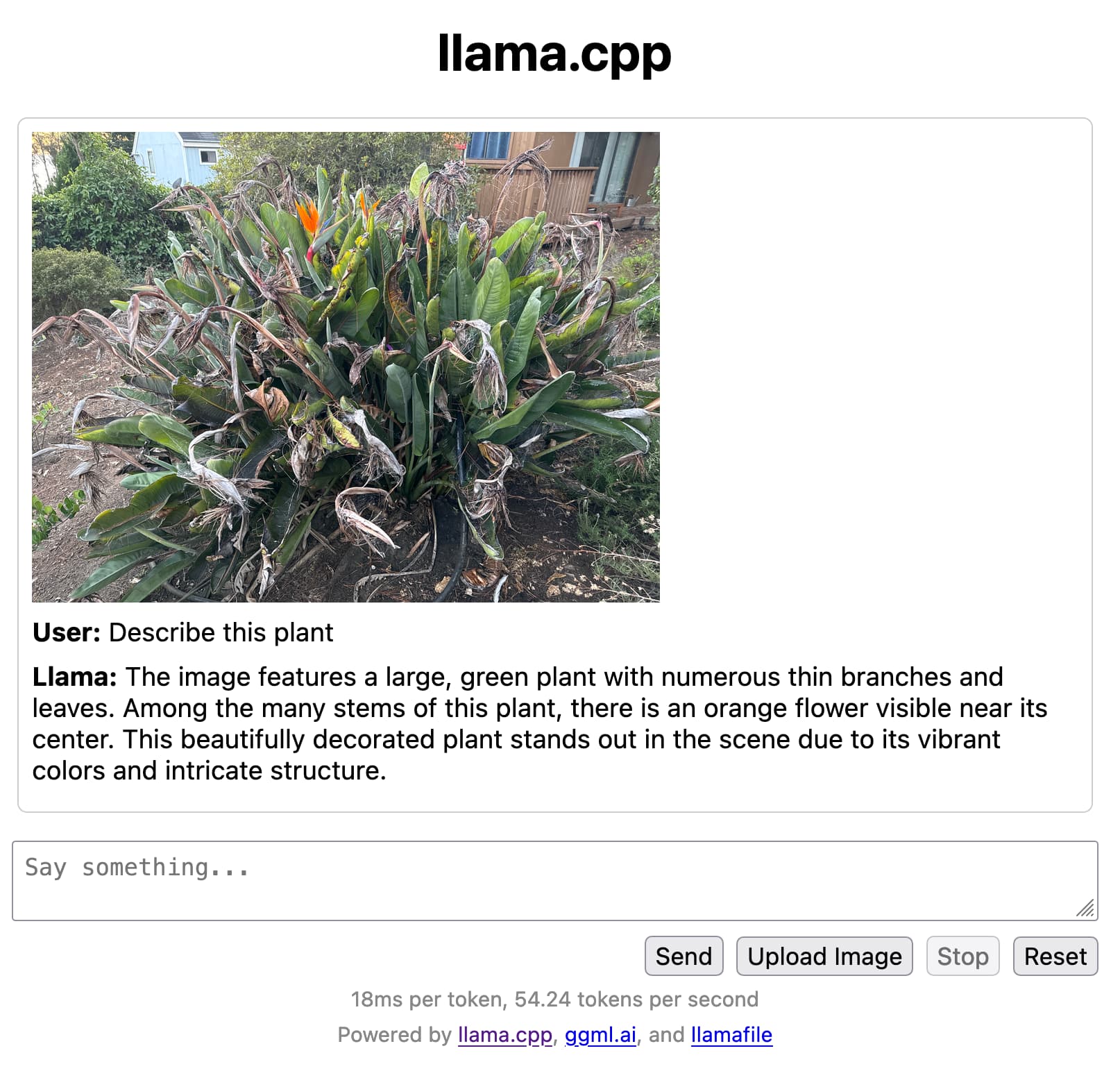
Mozilla’s innovation group and Justine Tunney just released llamafile, and I think it’s now the single best way to get started running Large Language Models (think your own local copy of ChatGPT) on your own computer.
[... 650 words]Build an image search engine with llm-clip, chat with models with llm chat

LLM is my combination CLI tool and Python library for working with Large Language Models. I just released LLM 0.10 with two significant new features: embedding support for binary files and the llm chat command.
Running my own LLM (via) Nelson Minar describes running LLMs on his own computer using my LLM tool and llm-gpt4all plugin, plus some notes on trying out some of the other plugins.
Run Llama 2 on your own Mac using LLM and Homebrew
Llama 2 is the latest commercially usable openly licensed Large Language Model, released by Meta AI a few weeks ago. I just released a new plugin for my LLM utility that adds support for Llama 2 and many other llama-cpp compatible models.
[... 1,423 words]Llama 2: The New Open LLM SOTA. I’m in this Latent Space podcast, recorded yesterday, talking about the Llama 2 release.
llama2-mac-gpu.sh (via) Adrien Brault provided this recipe for compiling llama.cpp on macOS with GPU support enabled (“LLAMA_METAL=1 make”) and then downloading and running a GGML build of Llama 2 13B.
Ollama (via) This tool for running LLMs on your own laptop directly includes an installer for macOS (Apple Silicon) and provides a terminal chat interface for interacting with models. They already have Llama 2 support working, with a model that downloads directly from their own registry service without need to register for an account or work your way through a waiting list.