10 posts tagged “onnx”
The Open Neural Network Exchange file format.
2026
Porting the Moebius 0.2B image inpainting model to run in the browser with Claude Code

This morning on Hacker News I saw Moebius: 0.2B Lightweight Image Inpainting Framework with 10B-Level Performance, describing a small but effective inpainting model—a model where you can mark regions of an image to remove and the model imagines what should fill the space. The released model required PyTorch and NVIDIA CUDA, but since it described itself as 0.2B I decided to try and get it running using WebGPU in a browser. TL;DR: I got it working, and you can try the demo at simonw.github.io/moebius-web/. Read on for the details.
[... 1,764 words]2025
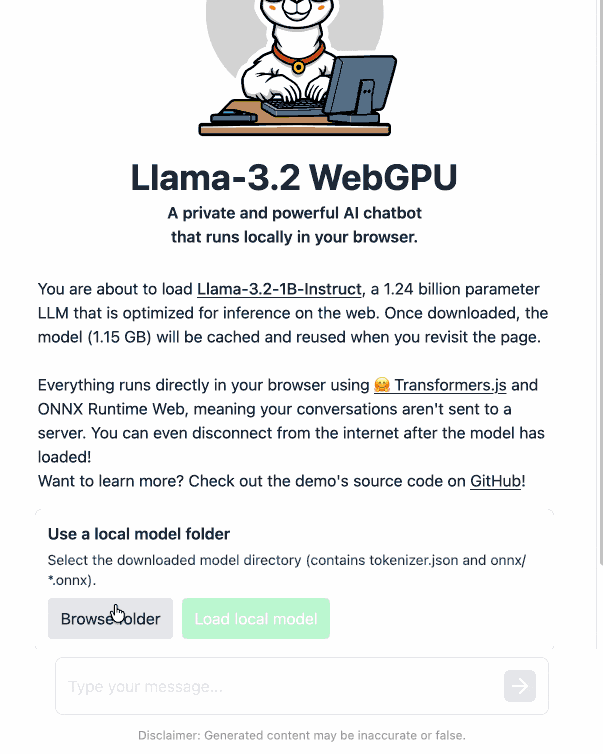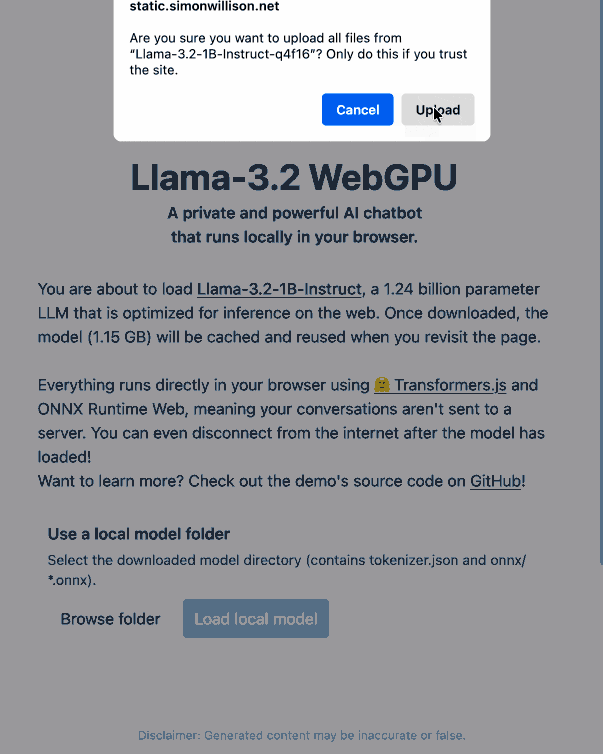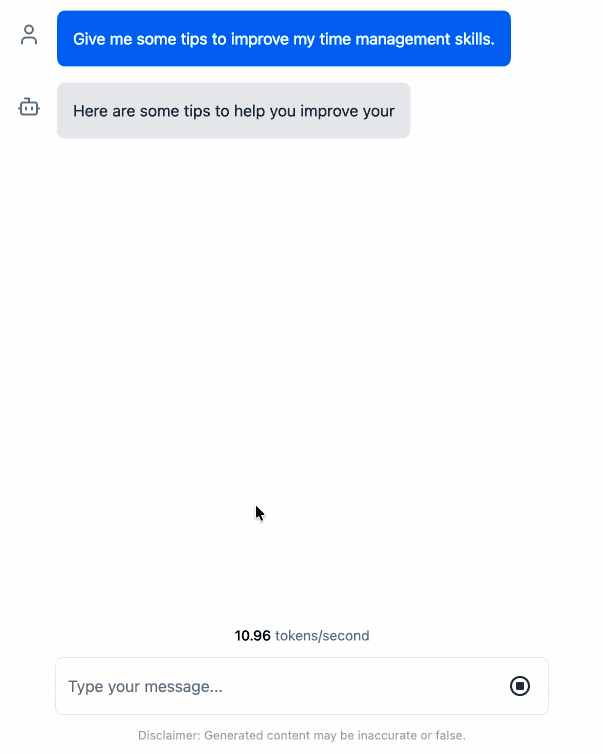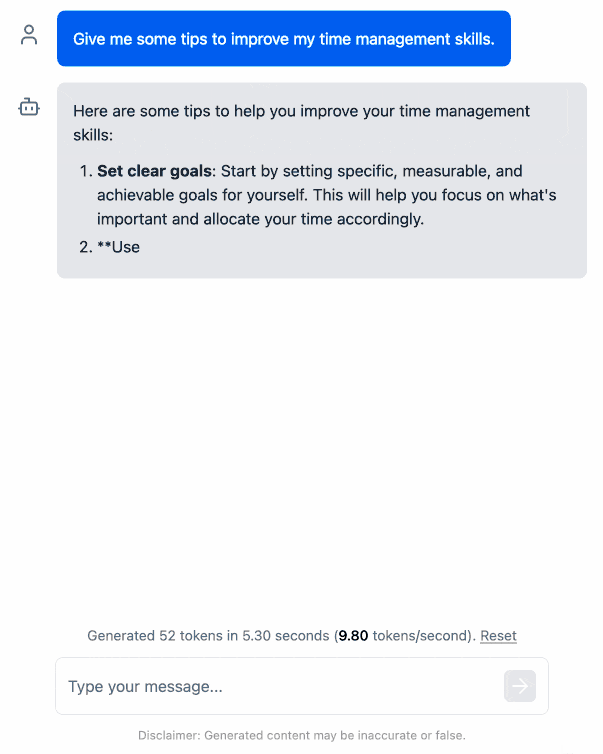
Load Llama-3.2 WebGPU in your browser from a local folder (via) Inspired by a comment on Hacker News I decided to see if it was possible to modify the transformers.js-examples/tree/main/llama-3.2-webgpu Llama 3.2 chat demo (online here, I wrote about it last November) to add an option to open a local model file directly from a folder on disk, rather than waiting for it to download over the network.
I posed the problem to OpenAI's GPT-5-enabled Codex CLI like this:
git clone https://github.com/huggingface/transformers.js-examples
cd transformers.js-examples/llama-3.2-webgpu
codex
Then this prompt:
Modify this application such that it offers the user a file browse button for selecting their own local copy of the model file instead of loading it over the network. Provide a "download model" option too.
Codex churned away for several minutes, even running commands like curl -sL https://raw.githubusercontent.com/huggingface/transformers.js/main/src/models.js | sed -n '1,200p' to inspect the source code of the underlying Transformers.js library.
After four prompts total (shown here) it built something which worked!
To try it out you'll need your own local copy of the Llama 3.2 ONNX model. You can get that (a ~1.2GB) download) like so:
git lfs install
git clone https://huggingface.co/onnx-community/Llama-3.2-1B-Instruct-q4f16
Then visit my llama-3.2-webgpu page in Chrome or Firefox Nightly (since WebGPU is required), click "Browse folder", select that folder you just cloned, agree to the "Upload" confirmation (confusing since nothing is uploaded from your browser, the model file is opened locally on your machine) and click "Load local model".
Here's an animated demo (recorded in real-time, I didn't speed this up):
I pushed a branch with those changes here. The next step would be to modify this to support other models in addition to the Llama 3.2 demo, but I'm pleased to have got to this proof of concept with so little work beyond throwing some prompts at Codex to see if it could figure it out.
According to the Codex /status command this used 169,818 input tokens, 17,112 output tokens and 1,176,320 cached input tokens. At current GPT-5 token pricing ($1.25/million input, $0.125/million cached input, $10/million output) that would cost 53.942 cents, but Codex CLI hooks into my existing $20/month ChatGPT Plus plan so this was bundled into that.
2024
llama-3.2-webgpu (via) Llama 3.2 1B is a really interesting models, given its 128,000 token input and its tiny size (barely more than a GB).
This page loads a 1.24GB q4f16 ONNX build of the Llama-3.2-1B-Instruct model and runs it with a React-powered chat interface directly in the browser, using Transformers.js and WebGPU. Source code for the demo is here.
It worked for me just now in Chrome; in Firefox and Safari I got a “WebGPU is not supported by this browser” error message.
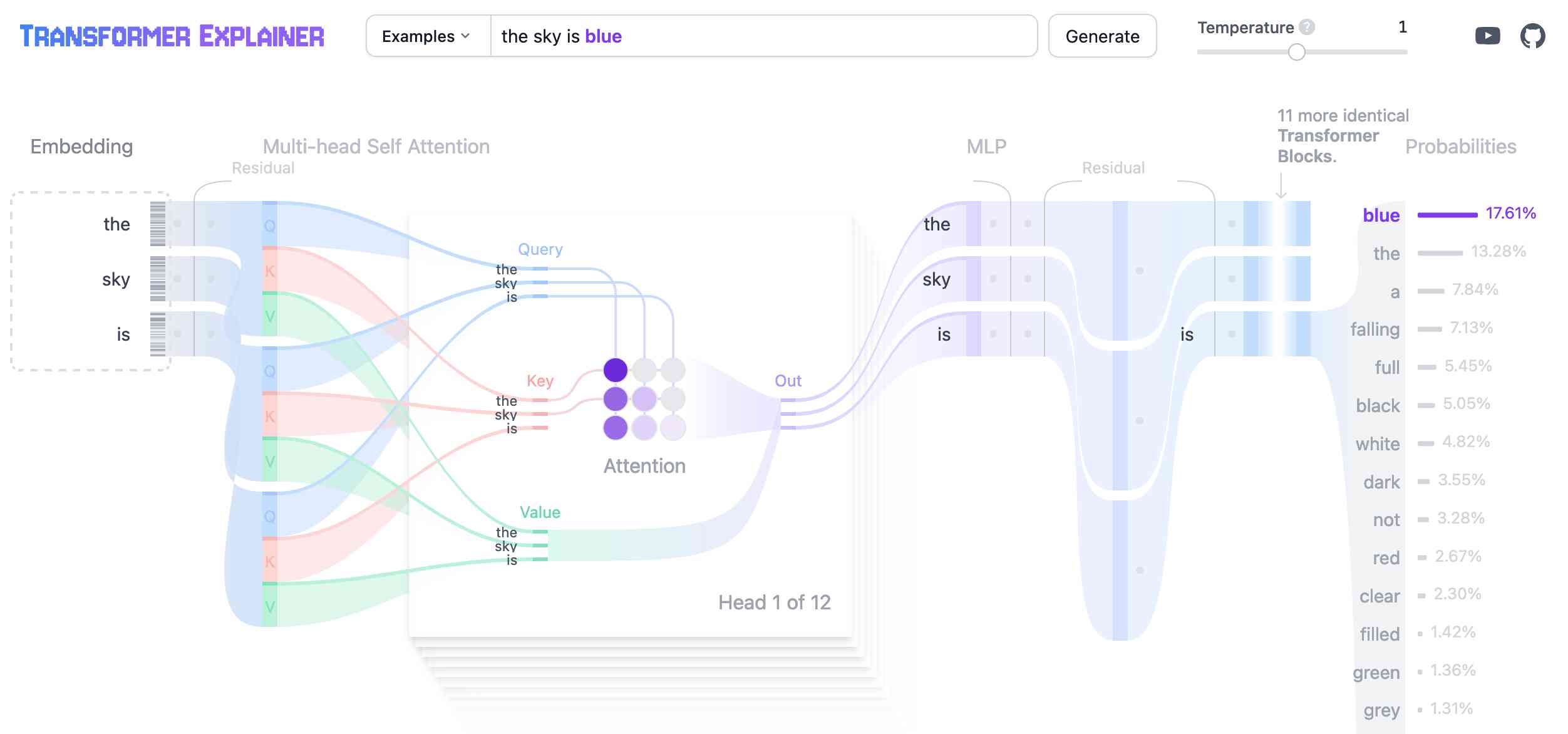
Transformer Explainer. This is a very neat interactive visualization (with accompanying essay and video - scroll down for those) that explains the Transformer architecture for LLMs, using a GPT-2 model running directly in the browser using the ONNX runtime and Andrej Karpathy's nanoGPT project.
Experimenting with local alt text generation in Firefox Nightly (via) The PDF editor in Firefox (confession: I did not know Firefox ships with a PDF editor) is getting an experimental feature that can help suggest alt text for images for the human editor to then adapt and improve on.
This is a great application of AI, made all the more interesting here because Firefox will run a local model on-device for this, using a custom trained model they describe as "our 182M parameters model using a Distilled version of GPT-2 alongside a Vision Transformer (ViT) image encoder".
The model uses WebAssembly with ONNX running in Transfomers.js, and will be downloaded the first time the feature is put to use.
unstructured. Relatively new but impressively capable Python library (Apache 2 licensed) for extracting information from unstructured documents, such as PDFs, images, Word documents and many other formats.
I got some good initial results against a PDF by running “pip install ’unstructured[pdf]’” and then using the “unstructured.partition.pdf.partition_pdf(filename)” function.
There are a lot of moving parts under the hood: pytesseract, OpenCV, various PDF libraries, even an ONNX model—but it installed cleanly for me on macOS and worked out of the box.
llm-embed-onnx. I wrote a new plugin for LLM that acts as a thin wrapper around onnx_embedding_models by Benjamin Anderson, providing access to seven embedding models that can run on the ONNX model framework.
The actual plugin is around 50 lines of code, which makes for a nice example of how thin a plugin wrapper can be that adds new models to my LLM tool.
2023
Perplexity: interactive LLM visualization (via) I linked to a video of Linus Lee's GPT visualization tool the other day. Today he's released a new version of it that people can actually play with: it runs entirely in a browser, powered by a 120MB version of the GPT-2 ONNX model loaded using the brilliant Transformers.js JavaScript library.
Wikipedia search-by-vibes through millions of pages offline (via) Really cool demo by Lee Butterman, who built embeddings of 2 million Wikipedia pages and figured out how to serve them directly to the browser, where they are used to implement “vibes based” similarity search returning results in 250ms. Lots of interesting details about how he pulled this off, using Arrow as the file format and ONNX to run the model in the browser.