7 posts tagged “prince-canuma”
2026
Qwen3-TTS Family is Now Open Sourced: Voice Design, Clone, and Generation (via) I haven't been paying much attention to the state-of-the-art in speech generation models other than noting that they've got really good, so I can't speak for how notable this new release from Qwen is.
From the accompanying paper:
In this report, we present the Qwen3-TTS series, a family of advanced multilingual, controllable, robust, and streaming text-to-speech models. Qwen3-TTS supports state-of- the-art 3-second voice cloning and description-based control, allowing both the creation of entirely novel voices and fine-grained manipulation over the output speech. Trained on over 5 million hours of speech data spanning 10 languages, Qwen3-TTS adopts a dual-track LM architecture for real-time synthesis [...]. Extensive experiments indicate state-of-the-art performance across diverse objective and subjective benchmark (e.g., TTS multilingual test set, InstructTTSEval, and our long speech test set). To facilitate community research and development, we release both tokenizers and models under the Apache 2.0 license.
To give an idea of size, Qwen/Qwen3-TTS-12Hz-1.7B-Base is 4.54GB on Hugging Face and Qwen/Qwen3-TTS-12Hz-0.6B-Base is 2.52GB.
The Hugging Face demo lets you try out the 0.6B and 1.7B models for free in your browser, including voice cloning:
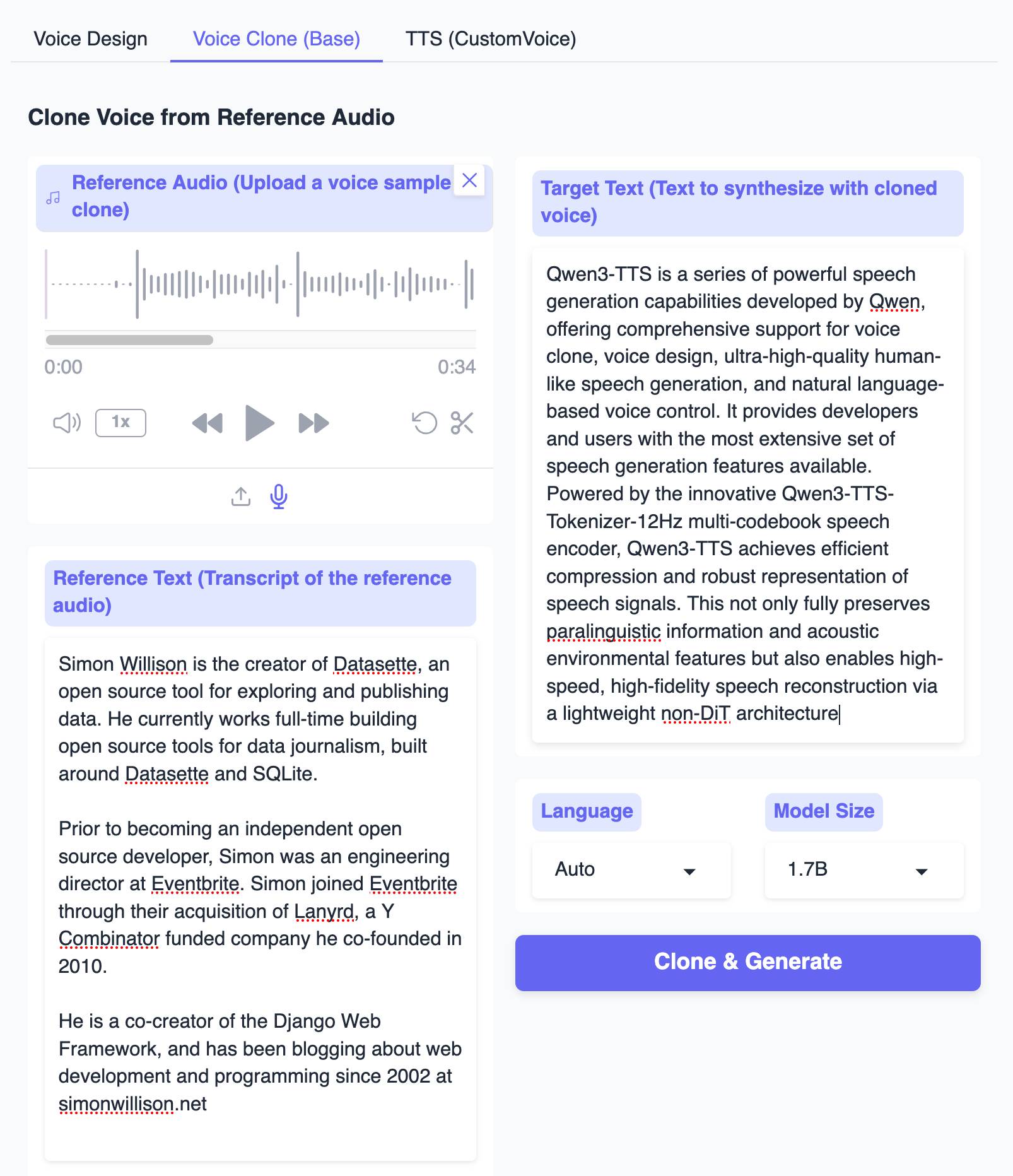
I tried this out by recording myself reading my about page and then having Qwen3-TTS generate audio of me reading the Qwen3-TTS announcement post. Here's the result:
It's important that everyone understands that voice cloning is now something that's available to anyone with a GPU and a few GBs of VRAM... or in this case a web browser that can access Hugging Face.
Update: Prince Canuma got this working with his mlx-audio library. I had Claude turn that into a CLI tool which you can run with uv ike this:
uv run https://tools.simonwillison.net/python/q3_tts.py \
'I am a pirate, give me your gold!' \
-i 'gruff voice' -o pirate.wav
The -i option lets you use a prompt to describe the voice it should use. On first run this downloads a 4.5GB model file from Hugging Face.
2025
Introducing Gemma 3n: The developer guide. Extremely consequential new open weights model release from Google today:
Multimodal by design: Gemma 3n natively supports image, audio, video, and text inputs and text outputs.
Optimized for on-device: Engineered with a focus on efficiency, Gemma 3n models are available in two sizes based on effective parameters: E2B and E4B. While their raw parameter count is 5B and 8B respectively, architectural innovations allow them to run with a memory footprint comparable to traditional 2B and 4B models, operating with as little as 2GB (E2B) and 3GB (E4B) of memory.
This is very exciting: a 2B and 4B model optimized for end-user devices which accepts text, images and audio as inputs!
Gemma 3n is also the most comprehensive day one launch I've seen for any model: Google partnered with "AMD, Axolotl, Docker, Hugging Face, llama.cpp, LMStudio, MLX, NVIDIA, Ollama, RedHat, SGLang, Unsloth, and vLLM" so there are dozens of ways to try this out right now.
So far I've run two variants on my Mac laptop. Ollama offer a 7.5GB version (full tag gemma3n:e4b-it-q4_K_M0) of the 4B model, which I ran like this:
ollama pull gemma3n
llm install llm-ollama
llm -m gemma3n:latest "Generate an SVG of a pelican riding a bicycle"
It drew me this:

The Ollama version doesn't appear to support image or audio input yet.
... but the mlx-vlm version does!
First I tried that on this WAV file like so (using a recipe adapted from Prince Canuma's video):
uv run --with mlx-vlm mlx_vlm.generate \
--model gg-hf-gm/gemma-3n-E4B-it \
--max-tokens 100 \
--temperature 0.7 \
--prompt "Transcribe the following speech segment in English:" \
--audio pelican-joke-request.wav
That downloaded a 15.74 GB bfloat16 version of the model and output the following correct transcription:
Tell me a joke about a pelican.
Then I had it draw me a pelican for good measure:
uv run --with mlx-vlm mlx_vlm.generate \
--model gg-hf-gm/gemma-3n-E4B-it \
--max-tokens 100 \
--temperature 0.7 \
--prompt "Generate an SVG of a pelican riding a bicycle"
I quite like this one:
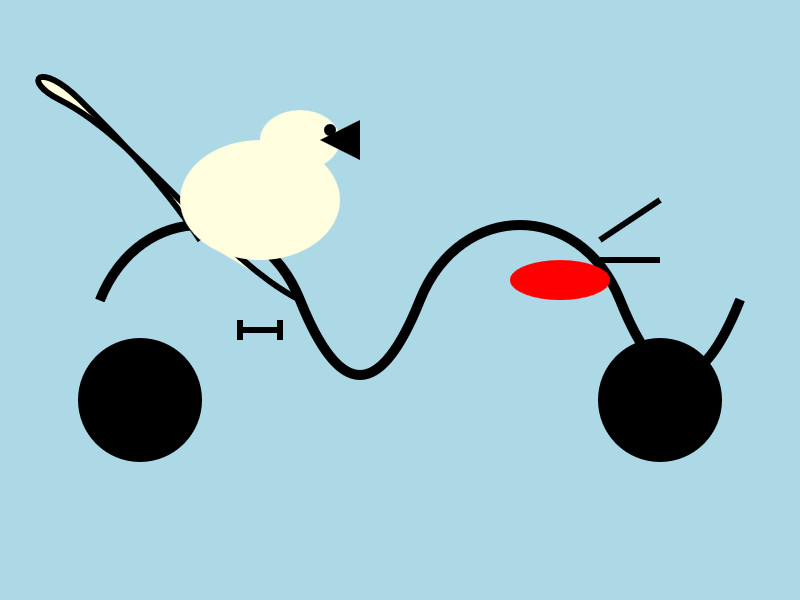
It's interesting to see such a striking visual difference between those 7.5GB and 15GB model quantizations.
Finally, I had it describe the image it had just created:
uv run --with mlx-vlm mlx_vlm.generate \
--model gg-hf-gm/gemma-3n-E4B-it \
--max-tokens 1000 \
--prompt "Describe image" \
--image gemma3n-mlx-vlm.jpg
Here's what I got back - it thought this was a chemical diagram!
The image is a cartoon-style illustration depicting a molecular structure against a light blue background. The structure is composed of several differently colored and shaped elements connected by curved black lines.
Here's a breakdown of the elements:
- Large Black Circles: There are two large, solid black circles, likely representing larger molecules or components.
- Cream-Colored Oval: A prominent cream-colored oval shape is centrally located and connected to other elements. It has a smaller, darker cream-colored sphere attached to its left side.
- Red Oval: A smaller, solid red oval is positioned near one of the black circles and connected to the cream-colored oval.
- Black Lines: These lines act as bonds, connecting the various molecular components. They are curved and dynamic, suggesting movement or interaction.
- Triangular Shape: A small black triangle is attached to the smaller cream-colored sphere.
- Letter "I": The letter "I" appears twice, likely labeling specific parts of the molecule.
The overall impression is of a simplified representation of a biological molecule, possibly a protein or a complex organic compound. The use of different colors helps to distinguish the various components within the structure.
Qwen2.5-VL-32B: Smarter and Lighter. The second big open weight LLM release from China today - the first being DeepSeek v3-0324.
Qwen's previous vision model was Qwen2.5 VL, released in January in 3B, 7B and 72B sizes.
Today's Apache 2.0 licensed release is a 32B model, which is quickly becoming my personal favourite model size - large enough to have GPT-4-class capabilities, but small enough that on my 64GB Mac there's still enough RAM for me to run other memory-hungry applications like Firefox and VS Code.
Qwen claim that the new model (when compared to their previous 2.5 VL family) can "align more closely with human preferences", is better at "mathematical reasoning" and provides "enhanced accuracy and detailed analysis in tasks such as image parsing, content recognition, and visual logic deduction".
They also offer some presumably carefully selected benchmark results showing it out-performing Gemma 3-27B, Mistral Small 3.1 24B and GPT-4o-0513 (there have been two more recent GPT-4o releases since that one, 2024-08-16 and 2024-11-20).
As usual, Prince Canuma had MLX versions of the models live within hours of the release, in 4 bit, 6 bit, 8 bit, and bf16 variants.
I ran the 4bit version (a 18GB model download) using uv and Prince's mlx-vlm like this:
uv run --with 'numpy<2' --with mlx-vlm \
python -m mlx_vlm.generate \
--model mlx-community/Qwen2.5-VL-32B-Instruct-4bit \
--max-tokens 1000 \
--temperature 0.0 \
--prompt "Describe this image." \
--image Mpaboundrycdfw-1.pngHere's the image:
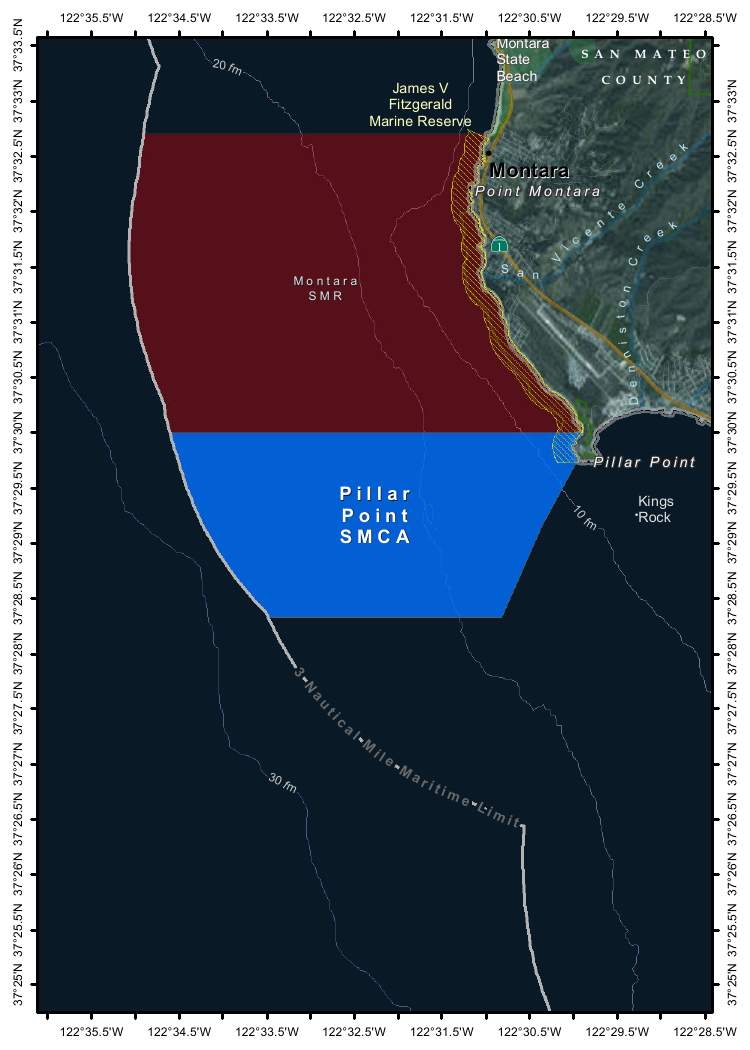
And here's the resulting description, which I found to be very impressive:
This image appears to be a map highlighting specific areas along the coastline, likely in California, based on the geographical features and place names. Here is a detailed description of the image:
Geographic Features:
- The map shows a section of the coastline, with land on the right and the sea on the left.
- The land area includes parts of SanMateo County, as noted in the top-right corner.
- The coastline features several named locations, including:
- Point Montara
- Pillar Point
- Kings Rock
- VicenteCreek
- DennistonCreek
- State Beach
Highlighted Areas:
- The map contains two distinct areas marked with different colors:
- Red Area (Top Section)
- Labeled as "MONTARA" and "MONTARA M R" (possibly referring to a "Marine Reserves" or similar protected area).
- This area is marked with a dark red color and extends from the coastline inland.
- Blue Area (Bottom Section)
- Labeled as "PILLAR" and "PILLAR P O I N T" along with "SMCA" (Special Management Area).
- This area is marked with a blue color and is located closer to the coastline, including the area around "Pillar Point."
Depth Contours:
- The map includes depth markings in the sea, indicating the bathymetrical features:
- 20 fathom (fm) line is marked in the upper-left part of the sea.
- 10 fathom (fm) line is marked closer to the coastline.
- 30 fathom (fm) line is marked further out to sea.
Other Features:
- State Beach: Marked near the top-right, indicating a protected recreational area.
- Kings Rock: A prominent feature near the coastline, likely a rocky outcropping.
- Creeks: The map shows several creeks, including VicenteCreek and DennistonCreek, which flow into the sea.
Protected Areas:
- The map highlights specific protected areas:
- Marine Reserves:
- "MONTARA M R" (Marine Reserves) in red.
- Special Management Area (SMCA)
- "PILLAR P O I N T" in blue, indicating a Special Management Area.
Grid and Coordinates:
- The map includes a grid with latitude and longitude markings:
- Latitude ranges from approximately 37°25'N to 37°35'N.
- Longitude ranges from approximately 122°22.5'W to 122°35.5'W.
Topography:
- The land area shows topographic features, including elevations and vegetation, with green areas indicating higher elevations or vegetated land.
Other Labels:
- "SMR": Likely stands for "State Managed Reserves."
- "SMCA": Likely stands for "Special Management Control Area."
In summary, this map highlights specific protected areas along the coastline, including a red "Marine Reserves" area and a blue "Special Management Area" near "Pillar Point." The map also includes depth markings, geographical features, and place names, providing a detailed view of the region's natural and protected areas.
It included the following runtime statistics:
Prompt: 1051 tokens, 111.985 tokens-per-sec
Generation: 760 tokens, 17.328 tokens-per-sec
Peak memory: 21.110 GB
Run LLMs on macOS using llm-mlx and Apple’s MLX framework
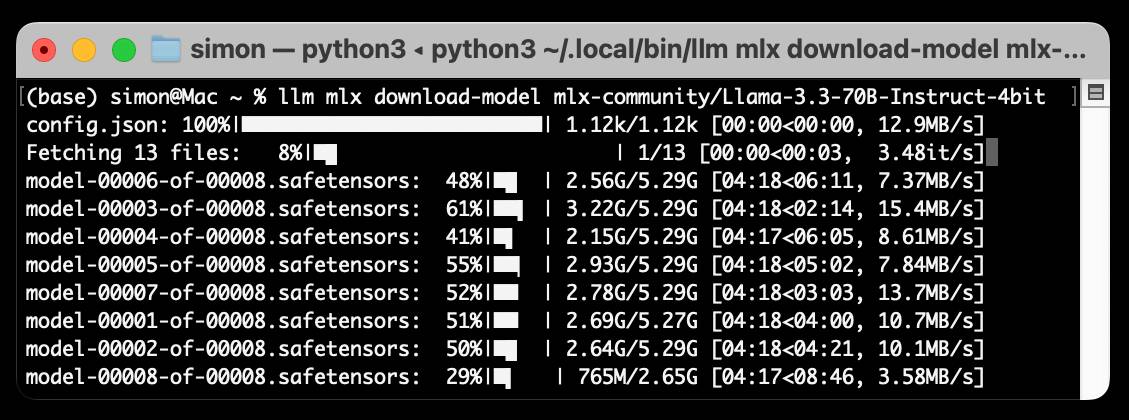
llm-mlx is a brand new plugin for my LLM Python Library and CLI utility which builds on top of Apple’s excellent MLX array framework library and mlx-lm package. If you’re a terminal user or Python developer with a Mac this may be the new easiest way to start exploring local Large Language Models.
[... 1,524 words]2024
Trying out QvQ—Qwen’s new visual reasoning model

I thought we were done for major model releases in 2024, but apparently not: Alibaba’s Qwen team just dropped the Apache 2.0 licensed Qwen licensed (the license changed) QvQ-72B-Preview, “an experimental research model focusing on enhancing visual reasoning capabilities”.
SmolVLM—small yet mighty Vision Language Model. I've been having fun playing with this new vision model from the Hugging Face team behind SmolLM. They describe it as:
[...] a 2B VLM, SOTA for its memory footprint. SmolVLM is small, fast, memory-efficient, and fully open-source. All model checkpoints, VLM datasets, training recipes and tools are released under the Apache 2.0 license.
I've tried it in a few flavours but my favourite so far is the mlx-vlm approach, via mlx-vlm author Prince Canuma. Here's the uv recipe I'm using to run it:
uv run \
--with mlx-vlm \
--with torch \
python -m mlx_vlm.generate \
--model mlx-community/SmolVLM-Instruct-bf16 \
--max-tokens 500 \
--temp 0.5 \
--prompt "Describe this image in detail" \
--image IMG_4414.JPG
If you run into an error using Python 3.13 (torch compatibility) try uv run --python 3.11 instead.
This one-liner installs the necessary dependencies, downloads the model (about 4.2GB, saved to ~/.cache/huggingface/hub/models--mlx-community--SmolVLM-Instruct-bf16) and executes the prompt and displays the result.
I ran that against this Pelican photo:

The model replied:
In the foreground of this photograph, a pelican is perched on a pile of rocks. The pelican’s wings are spread out, and its beak is open. There is a small bird standing on the rocks in front of the pelican. The bird has its head cocked to one side, and it seems to be looking at the pelican. To the left of the pelican is another bird, and behind the pelican are some other birds. The rocks in the background of the image are gray, and they are covered with a variety of textures. The rocks in the background appear to be wet from either rain or sea spray.
There are a few spatial mistakes in that description but the vibes are generally in the right direction.
On my 64GB M2 MacBook pro it read the prompt at 7.831 tokens/second and generated that response at an impressive 74.765 tokens/second.
mlx-vlm (via) The MLX ecosystem of libraries for running machine learning models on Apple Silicon continues to expand. Prince Canuma is actively developing this library for running vision models such as Qwen-2 VL and Pixtral and LLaVA using Python running on a Mac.
I used uv to run it against this image with this shell one-liner:
uv run --with mlx-vlm \
python -m mlx_vlm.generate \
--model Qwen/Qwen2-VL-2B-Instruct \
--max-tokens 1000 \
--temp 0.0 \
--image https://static.simonwillison.net/static/2024/django-roadmap.png \
--prompt "Describe image in detail, include all text"
The --image option works equally well with a URL or a path to a local file on disk.
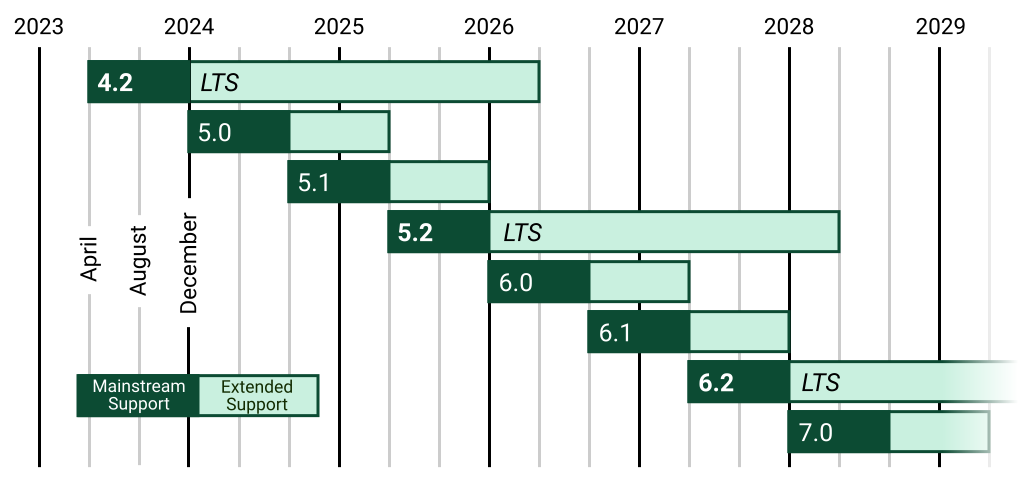
This first downloaded 4.1GB to my ~/.cache/huggingface/hub/models--Qwen--Qwen2-VL-2B-Instruct folder and then output this result, which starts:
The image is a horizontal timeline chart that represents the release dates of various software versions. The timeline is divided into years from 2023 to 2029, with each year represented by a vertical line. The chart includes a legend at the bottom, which distinguishes between different types of software versions.
Legend
Mainstream Support:
- 4.2 (2023)
- 5.0 (2024)
- 5.1 (2025)
- 5.2 (2026)
- 6.0 (2027) [...]