September 2024
131 posts: 10 entries, 49 links, 23 quotes, 49 beats
Sept. 24, 2024
XKCD 1425 (Tasks) turns ten years old today (via) One of the all-time great XKCDs. It's amazing that "check whether the photo is of a bird" has gone from PhD-level to trivially easy to solve (with a vision LLM, or CLIP, or ResNet+ImageNet among others).

The key idea still very much stands though. Understanding the difference between easy and hard challenges in software development continues to require an enormous depth of experience.
I'd argue that LLMs have made this even worse.
Understanding what kind of tasks LLMs can and cannot reliably solve remains incredibly difficult and unintuitive. They're computer systems that are terrible at maths and that can't reliably lookup facts!
On top of that, the rise of AI-assisted programming tools means more people than ever are beginning to create their own custom software.
These brand new AI-assisted proto-programmers are having a crash course in this easy-v.s.-hard problem.
I saw someone recently complaining that they couldn't build a Claude Artifact that could analyze images, even though they knew Claude itself could do that. Understanding why that's not possible involves understanding how the CSP headers that are used to serve Artifacts prevent the generated code from making its own API calls out to an LLM!
nanodjango. Richard Terry demonstrated this in a lightning talk at DjangoCon US today. It's the latest in a long line of attempts to get Django to work with a single file (I had a go at this problem 15 years ago with djng) but this one is really compelling.
I tried nanodjango out just now and it works exactly as advertised. First install it like this:
pip install nanodjango
Create a counter.py file:
from django.db import models from nanodjango import Django app = Django() @app.admin # Registers with the Django admin class CountLog(models.Model): timestamp = models.DateTimeField(auto_now_add=True) @app.route("/") def count(request): CountLog.objects.create() return f"<p>Number of page loads: {CountLog.objects.count()}</p>"
Then run it like this (it will run migrations and create a superuser as part of that first run):
nanodjango run counter.py
That's it! This gave me a fully configured Django application with models, migrations, the Django Admin configured and a bunch of other goodies such as Django Ninja for API endpoints.
Here's the full documentation.
Updated production-ready Gemini models.
Two new models from Google Gemini today: gemini-1.5-pro-002 and gemini-1.5-flash-002. Their -latest aliases will update to these new models in "the next few days", and new -001 suffixes can be used to stick with the older models. The new models benchmark slightly better in various ways and should respond faster.
Flash continues to have a 1,048,576 input token and 8,192 output token limit. Pro is 2,097,152 input tokens.
Google also announced a significant price reduction for Pro, effective on the 1st of October. Inputs less than 128,000 tokens drop from $3.50/million to $1.25/million (above 128,000 tokens it's dropping from $7 to $5) and output costs drop from $10.50/million to $2.50/million ($21 down to $10 for the >128,000 case).
For comparison, GPT-4o is currently $5/m input and $15/m output and Claude 3.5 Sonnet is $3/m input and $15/m output. Gemini 1.5 Pro was already the cheapest of the frontier models and now it's even cheaper.
Correction: I missed gpt-4o-2024-08-06 which is listed later on the OpenAI pricing page and priced at $2.50/m input and $10/m output. So the new Gemini 1.5 Pro prices are undercutting that.
Gemini has always offered finely grained safety filters - it sounds like those are now turned down to minimum by default, which is a welcome change:
For the models released today, the filters will not be applied by default so that developers can determine the configuration best suited for their use case.
Also interesting: they've tweaked the expected length of default responses:
For use cases like summarization, question answering, and extraction, the default output length of the updated models is ~5-20% shorter than previous models.
Sept. 25, 2024
DJP: A plugin system for Django
DJP is a new plugin mechanism for Django, built on top of Pluggy. I announced the first version of DJP during my talk yesterday at DjangoCon US 2024, How to design and implement extensible software with plugins. I’ll post a full write-up of that talk once the video becomes available—this post describes DJP and how to use what I’ve built so far.
[... 1,664 words]The Pragmatic Engineer Podcast: AI tools for software engineers, but without the hype – with Simon Willison. Gergely Orosz has a brand new podcast, and I was the guest for the first episode. We covered a bunch of ground, but my favorite topic was an exploration of the (very legitimate) reasons that many engineers are resistant to taking advantage of AI-assisted programming tools.
We used this model [periodically transmitting configuration to different hosts] to distribute translations, feature flags, configuration, search indexes, etc at Airbnb. But instead of SQLite we used Sparkey, a KV file format developed by Spotify. In early years there was a Cron job on every box that pulled that service’s thingies; then once we switched to Kubernetes we used a daemonset & host tagging (taints?) to pull a variety of thingies to each host and then ensure the services that use the thingies only ran on the hosts that had the thingies.
Solving a bug with o1-preview, files-to-prompt and LLM.
I added a new feature to DJP this morning: you can now have plugins specify their middleware in terms of how it should be positioned relative to other middleware - inserted directly before or directly after django.middleware.common.CommonMiddleware for example.
At one point I got stuck with a weird test failure, and after ten minutes of head scratching I decided to pipe the entire thing into OpenAI's o1-preview to see if it could spot the problem. I used files-to-prompt to gather the code and LLM to run the prompt:
files-to-prompt **/*.py -c | llm -m o1-preview "
The middleware test is failing showing all of these - why is MiddlewareAfter repeated so many times?
['MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware5', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware2', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware5', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware4', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware5', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware2', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware5', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware', 'MiddlewareBefore']"The model whirled away for a few seconds and spat out an explanation of the problem - one of my middleware classes was accidentally calling self.get_response(request) in two different places.
I did enjoy how o1 attempted to reference the relevant Django documentation and then half-repeated, half-hallucinated a quote from it:

This took 2,538 input tokens and 4,354 output tokens - by my calculations at $15/million input and $60/million output that prompt cost just under 30 cents.
Llama 3.2. In further evidence that AI labs are terrible at naming things, Llama 3.2 is a huge upgrade to the Llama 3 series - they've released their first multi-modal vision models!
Today, we’re releasing Llama 3.2, which includes small and medium-sized vision LLMs (11B and 90B), and lightweight, text-only models (1B and 3B) that fit onto edge and mobile devices, including pre-trained and instruction-tuned versions.
The 1B and 3B text-only models are exciting too, with a 128,000 token context length and optimized for edge devices (Qualcomm and MediaTek hardware get called out specifically).
Meta partnered directly with Ollama to help with distribution, here's the Ollama blog post. They only support the two smaller text-only models at the moment - this command will get the 3B model (2GB):
ollama run llama3.2
And for the 1B model (a 1.3GB download):
ollama run llama3.2:1b
I had to first upgrade my Ollama by clicking on the icon in my macOS task tray and selecting "Restart to update".
The two vision models are coming to Ollama "very soon".
Once you have fetched the Ollama model you can access it from my LLM command-line tool like this:
pipx install llm
llm install llm-ollama
llm chat -m llama3.2:1b
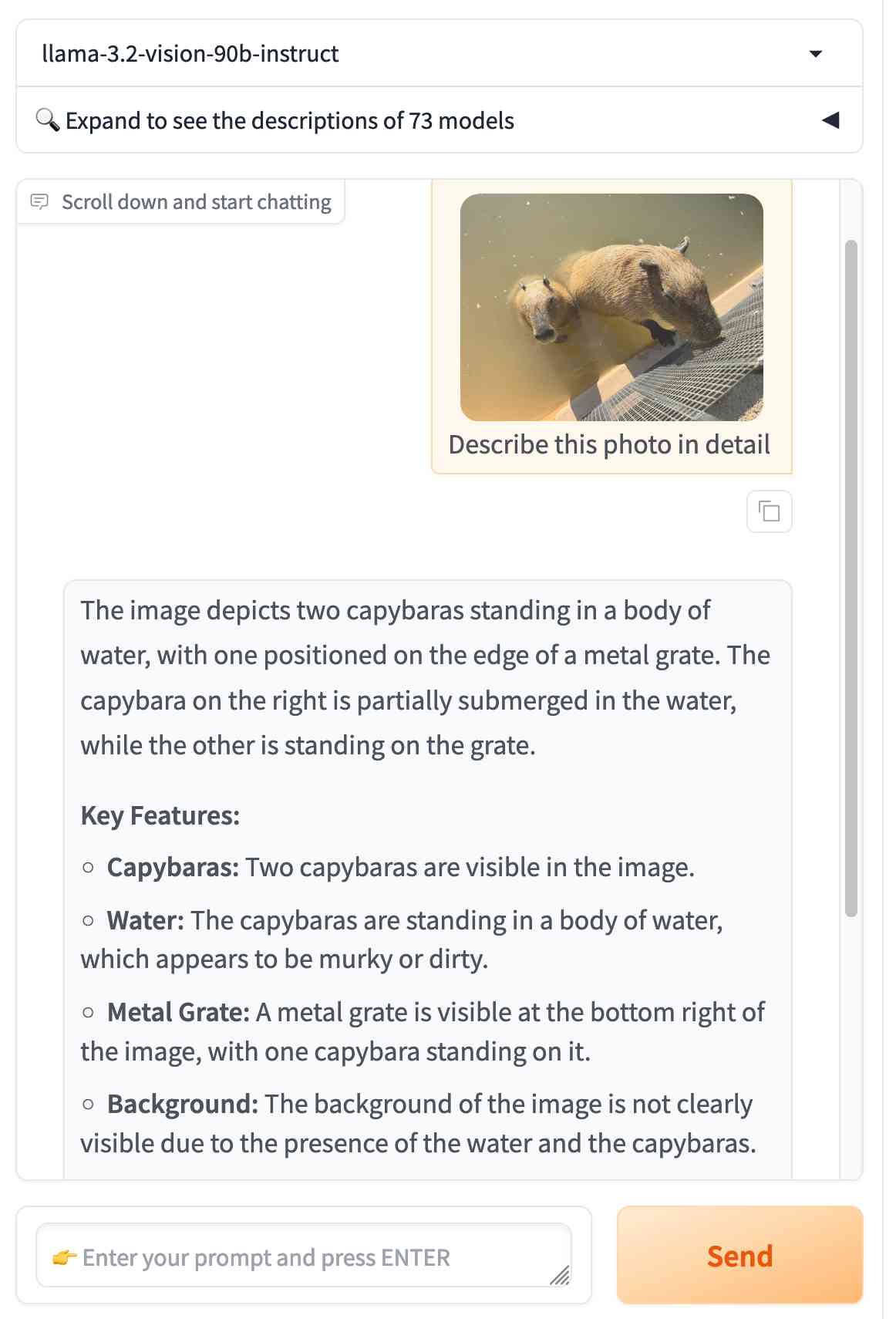
I tried running my djp codebase through that tiny 1B model just now and got a surprisingly good result - by no means comprehensive, but way better than I would ever expect from a model of that size:
files-to-prompt **/*.py -c | llm -m llama3.2:1b --system 'describe this code'
Here's a portion of the output:
The first section defines several test functions using the
@djp.hookimpldecorator from the djp library. These hook implementations allow you to intercept and manipulate Django's behavior.
test_middleware_order: This function checks that the middleware order is correct by comparing theMIDDLEWAREsetting with a predefined list.test_middleware: This function tests various aspects of middleware:- It retrieves the response from the URL
/from-plugin/using theClientobject, which simulates a request to this view.- It checks that certain values are present in the response:
X-DJP-Middleware-AfterX-DJP-MiddlewareX-DJP-Middleware-Before[...]
I found the GGUF file that had been downloaded by Ollama in my ~/.ollama/models/blobs directory. The following command let me run that model directly in LLM using the llm-gguf plugin:
llm install llm-gguf
llm gguf register-model ~/.ollama/models/blobs/sha256-74701a8c35f6c8d9a4b91f3f3497643001d63e0c7a84e085bed452548fa88d45 -a llama321b
llm chat -m llama321b
Meta themselves claim impressive performance against other existing models:
Our evaluation suggests that the Llama 3.2 vision models are competitive with leading foundation models, Claude 3 Haiku and GPT4o-mini on image recognition and a range of visual understanding tasks. The 3B model outperforms the Gemma 2 2.6B and Phi 3.5-mini models on tasks such as following instructions, summarization, prompt rewriting, and tool-use, while the 1B is competitive with Gemma.
Here's the Llama 3.2 collection on Hugging Face. You need to accept the new Llama 3.2 Community License Agreement there in order to download those models.
You can try the four new models out via the Chatbot Arena - navigate to "Direct Chat" there and select them from the dropdown menu. You can upload images directly to the chat there to try out the vision features.
Sept. 26, 2024
I think individual creators or publishers tend to overestimate the value of their specific content in the grand scheme of [AI training]. […]
We pay for content when it’s valuable to people. We’re just not going to pay for content when it’s not valuable to people. I think that you’ll probably see a similar dynamic with AI, which my guess is that there are going to be certain partnerships that get made when content is really important and valuable. I’d guess that there are probably a lot of people who have a concern about the feel of it, like you’re saying. But then, when push comes to shove, if they demanded that we don’t use their content, then we just wouldn’t use their content. It’s not like that’s going to change the outcome of this stuff that much.
django-plugin-datasette. I did some more work on my DJP plugin mechanism for Django at the DjangoCon US sprints today. I added a new plugin hook, asgi_wrapper(), released in DJP 0.3 and inspired by the similar hook in Datasette.
The hook only works for Django apps that are served using ASGI. It allows plugins to add their own wrapping ASGI middleware around the Django app itself, which means they can do things like attach entirely separate ASGI-compatible applications outside of the regular Django request/response cycle.
Datasette is one of those ASGI-compatible applications!
django-plugin-datasette uses that new hook to configure a new URL, /-/datasette/, which serves a full Datasette instance that scans through Django’s settings.DATABASES dictionary and serves an explore interface on top of any SQLite databases it finds there.
It doesn’t support authentication yet, so this will expose your entire database contents - probably best used as a local debugging tool only.
I did borrow some code from the datasette-mask-columns plugin to ensure that the password column in the auth_user column is reliably redacted. That column contains a heavily salted hashed password so exposing it isn’t necessarily a disaster, but I like to default to keeping hashes safe.
Sept. 27, 2024
Consumer products have had growth hackers for many years optimizing every part of the onboarding funnel. Dev tools should do the same. Getting started shouldn't be an afterthought after you built the product. Getting started is the product!
And I mean this to the point where I think it's worth restructuring your entire product to enable fast onboarding. Get rid of mandatory config. Make it absurdly easy to set up API tokens. Remove all the friction. Make it possible for users to use your product on their laptop in a couple of minutes, tops.

Vincent Simonetti collected his first historic tuba - a ~1910 Cerveny BB-flat Helicon - in Boston in 1965, while playing tuba on tour with the Moyseev Ballet Company. Today the collection has grown to more than 350 tubas, and is now the largest private collection in the world that is dedicated exclusively to members of the tuba family.
Niche Museums: The Vincent and Ethel Simonetti Historic Tuba Collection. DjangoCon was in Durham, North Carolina this year and thanks to Atlas Obscura I found out about the fabulous Vincent and Ethel Simonetti Historic Tuba Collection. We got together a group of five for a visit and had a wonderful time being shown around the collection by curator Vincent Simonetti. This is my first update to Niche Museums in quite a while, it's nice to get that project rolling again.

Themes from DjangoCon US 2024
I just arrived home from a trip to Durham, North Carolina for DjangoCon US 2024. I’ve already written about my talk where I announced a new plugin system for Django; here are my notes on some of the other themes that resonated with me during the conference.
[... 1,470 words]Some Go web dev notes. Julia Evans on writing small, self-contained web applications in Go:
In general everything about it feels like it makes projects easy to work on for 5 days, abandon for 2 years, and then get back into writing code without a lot of problems.
Go 1.22 introduced HTTP routing in February of this year, making it even more practical to build a web application using just the Go standard library.
Sept. 28, 2024
DjangoTV (via) Brand new site by Jeff Triplett gathering together videos from Django conferences around the world. Here's Jeff's blog post introducing the project.
OpenFreeMap (via) New free map tile hosting service from Zsolt Ero:
OpenFreeMap lets you display custom maps on your website and apps for free. […] Using our public instance is completely free: there are no limits on the number of map views or requests. There’s no registration, no user database, no API keys, and no cookies. We aim to cover the running costs of our public instance through donations.
The site serves static vector tiles that work with MapLibre GL. It deliberately doesn’t offer any other services such as search or routing.
From the project README looks like it’s hosted on two Hetzner machines. I don’t think the public server is behind a CDN.
Part of the trick to serving the tiles efficiently is the way it takes advantage of Btrfs:
Production-quality hosting of 300 million tiny files is hard. The average file size is just 450 byte. Dozens of tile servers have been written to tackle this problem, but they all have their limitations.
The original idea of this project is to avoid using tile servers altogether. Instead, the tiles are directly served from Btrfs partition images + hard links using an optimised nginx config.
The self-hosting guide describes the scripts that are provided for downloading their pre-built tiles (needing a fresh Ubuntu server with 300GB of SSD and 4GB of RAM) or building the tiles yourself using Planetiler (needs 500GB of disk and 64GB of RAM).
Getting started is delightfully straightforward:
const map = new maplibregl.Map({
style: 'https://tiles.openfreemap.org/styles/liberty',
center: [13.388, 52.517],
zoom: 9.5,
container: 'map',
})
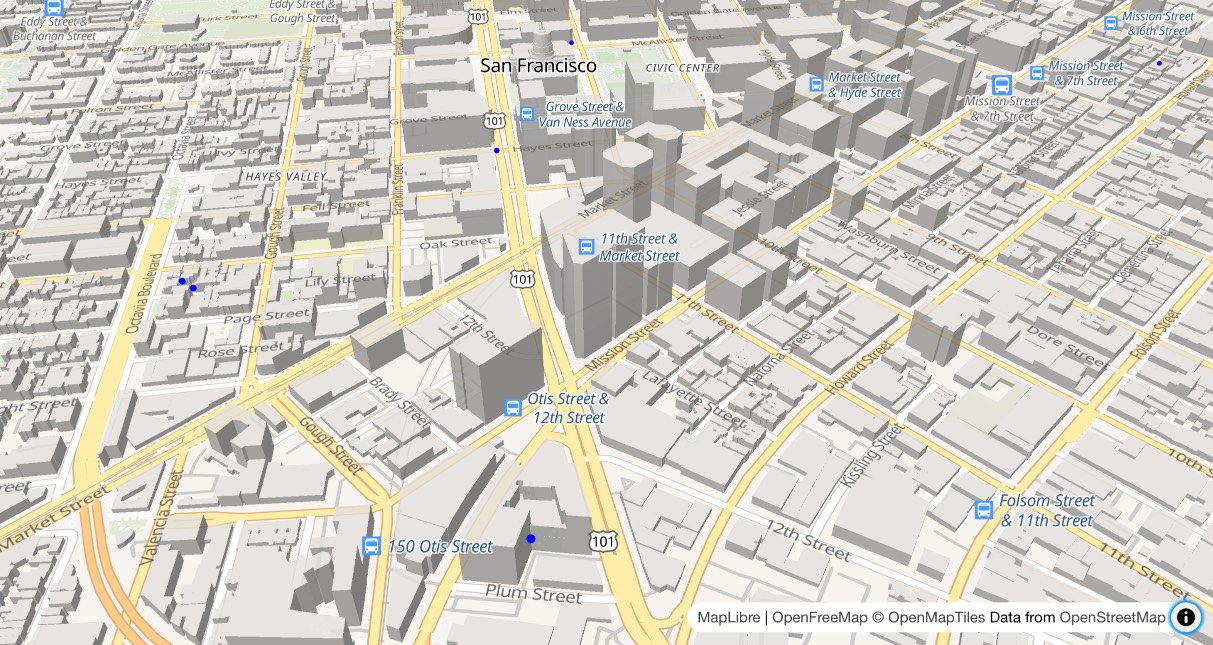
I got Claude to help build this demo showing a thousand random markers dotted around San Francisco. The 3D tiles even include building shapes!
Zsolt built OpenFreeMap based on his experience running MapHub over the last 9 years. Here’s a 2018 interview about that project.
It’s pretty incredible that the OpenStreetMap and open geospatial stack has evolved to the point now where it’s economically feasible for an individual to offer a service like this. I hope this turns out to be sustainable. Hetzner charge just €1 per TB for bandwidth (S3 can cost $90/TB) which should help a lot.
OpenAI’s revenue in August more than tripled from a year ago, according to the documents, and about 350 million people — up from around 100 million in March — used its services each month as of June. […]
Roughly 10 million ChatGPT users pay the company a $20 monthly fee, according to the documents. OpenAI expects to raise that price by $2 by the end of the year, and will aggressively raise it to $44 over the next five years, the documents said.
Sept. 29, 2024
If you use a JavaScript framework you should:
- be able to justify with evidence, how using JavaScript would benefit users
- be aware of any negative impacts and be able to mitigate them
- consider whether the benefits of using it outweigh the potential problems
- only use the framework for parts of the user interface that cannot be built using HTML and CSS alone
- design each part of the user interface as a separate component
Having separate components means that if the JavaScript fails to load, it will only be that single component that fails. The rest of the page will load as normal.