80 posts tagged “llama”
The Llama family of open weight LLMs from Meta/Facebook AI research.
2026
Taalas serves Llama 3.1 8B at 17,000 tokens/second (via) This new Canadian hardware startup just announced their first product - a custom hardware implementation of the Llama 3.1 8B model (from July 2024) that can run at a staggering 17,000 tokens/second.
I was going to include a video of their demo but it's so fast it would look more like a screenshot. You can try it out at chatjimmy.ai.
They describe their Silicon Llama as “aggressively quantized, combining 3-bit and 6-bit parameters.” Their next generation will use 4-bit - presumably they have quite a long lead time for baking out new models!
ggml.ai joins Hugging Face to ensure the long-term progress of Local AI (via) I don't normally cover acquisition news like this, but I have some thoughts.
It's hard to overstate the impact Georgi Gerganov has had on the local model space. Back in March 2023 his release of llama.cpp made it possible to run a local LLM on consumer hardware. The original README said:
The main goal is to run the model using 4-bit quantization on a MacBook. [...] This was hacked in an evening - I have no idea if it works correctly.
I wrote about trying llama.cpp out at the time in Large language models are having their Stable Diffusion moment:
I used it to run the 7B LLaMA model on my laptop last night, and then this morning upgraded to the 13B model—the one that Facebook claim is competitive with GPT-3.
Meta's original LLaMA release depended on PyTorch and their FairScale PyTorch extension for running on multiple GPUs, and required CUDA and NVIDIA hardware. Georgi's work opened that up to a much wider range of hardware and kicked off the local model movement that has continued to grow since then.
Hugging Face are already responsible for the incredibly influential Transformers library used by the majority of LLM releases today. They've proven themselves a good steward for that open source project, which makes me optimistic for the future of llama.cpp and related projects.
This section from the announcement looks particularly promising:
Going forward, our joint efforts will be geared towards the following objectives:
- Towards seamless "single-click" integration with the transformers library. The
transformersframework has established itself as the 'source of truth' for AI model definitions. Improving the compatibility between the transformers and the ggml ecosystems is essential for wider model support and quality control.- Better packaging and user experience of ggml-based software. As we enter the phase in which local inference becomes a meaningful and competitive alternative to cloud inference, it is crucial to improve and simplify the way in which casual users deploy and access local models. We will work towards making llama.cpp ubiquitous and readily available everywhere, and continue partnering with great downstream projects.
Given the influence of Transformers, this closer integration could lead to model releases that are compatible with the GGML ecosystem out of the box. That would be a big win for the local model ecosystem.
I'm also excited to see investment in "packaging and user experience of ggml-based software". This has mostly been left to tools like Ollama and LM Studio. ggml-org released LlamaBarn last year - "a macOS menu bar app for running local LLMs" - and I'm hopeful that further investment in this area will result in more high quality open source tools for running local models from the team best placed to deliver them.
2025
Load Llama-3.2 WebGPU in your browser from a local folder (via) Inspired by a comment on Hacker News I decided to see if it was possible to modify the transformers.js-examples/tree/main/llama-3.2-webgpu Llama 3.2 chat demo (online here, I wrote about it last November) to add an option to open a local model file directly from a folder on disk, rather than waiting for it to download over the network.
I posed the problem to OpenAI's GPT-5-enabled Codex CLI like this:
git clone https://github.com/huggingface/transformers.js-examples
cd transformers.js-examples/llama-3.2-webgpu
codex
Then this prompt:
Modify this application such that it offers the user a file browse button for selecting their own local copy of the model file instead of loading it over the network. Provide a "download model" option too.
Codex churned away for several minutes, even running commands like curl -sL https://raw.githubusercontent.com/huggingface/transformers.js/main/src/models.js | sed -n '1,200p' to inspect the source code of the underlying Transformers.js library.
After four prompts total (shown here) it built something which worked!
To try it out you'll need your own local copy of the Llama 3.2 ONNX model. You can get that (a ~1.2GB) download) like so:
git lfs install
git clone https://huggingface.co/onnx-community/Llama-3.2-1B-Instruct-q4f16
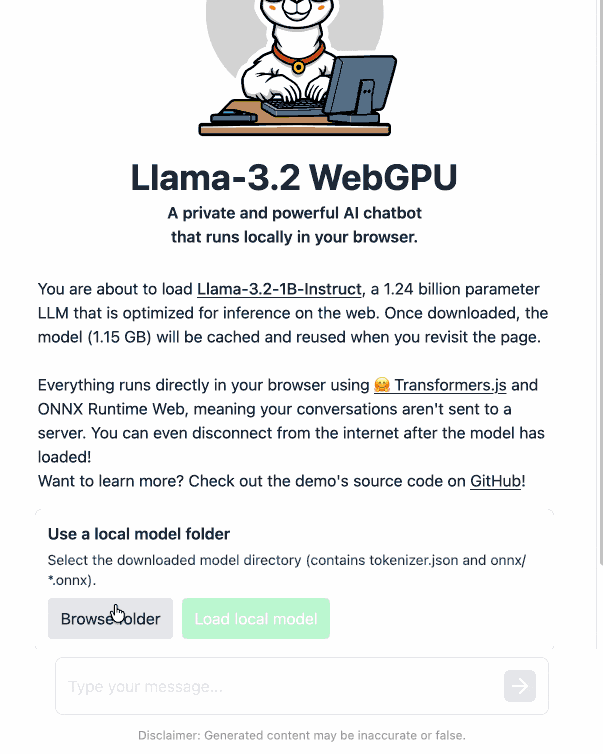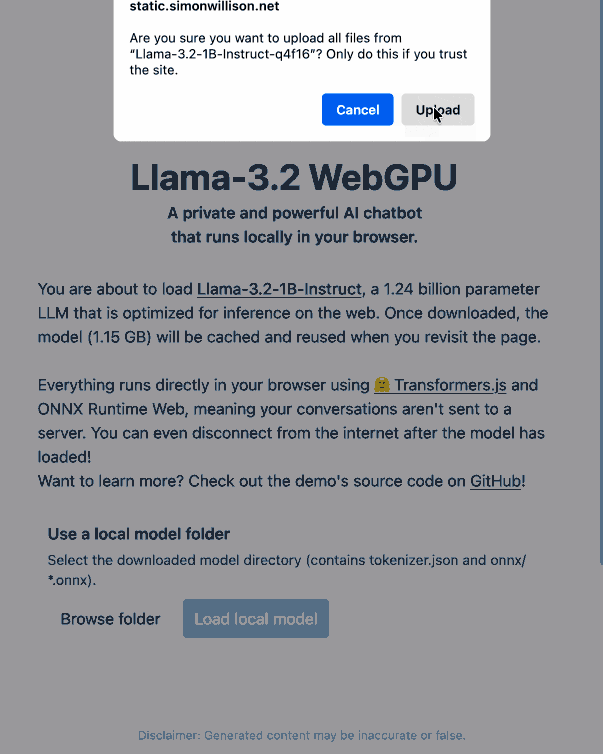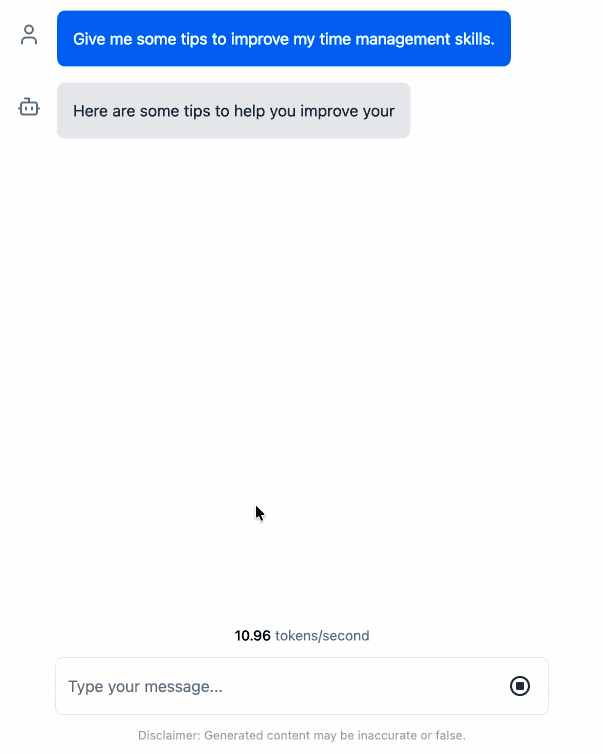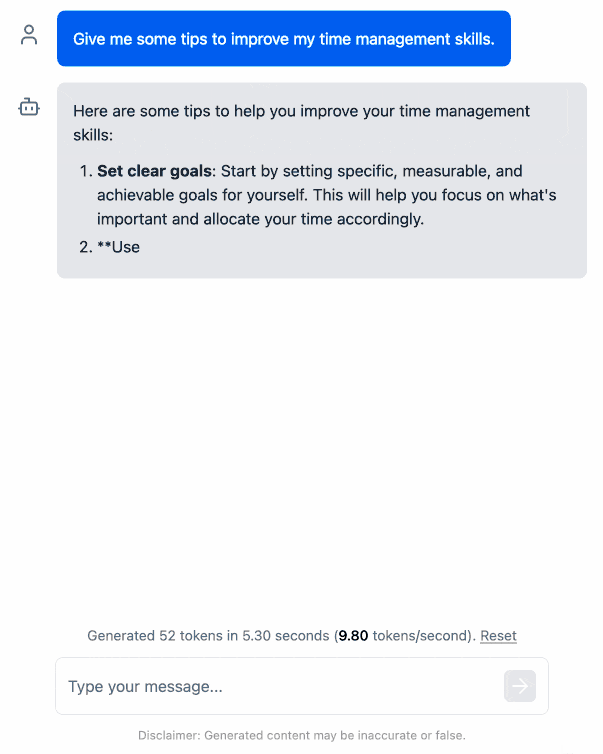
Then visit my llama-3.2-webgpu page in Chrome or Firefox Nightly (since WebGPU is required), click "Browse folder", select that folder you just cloned, agree to the "Upload" confirmation (confusing since nothing is uploaded from your browser, the model file is opened locally on your machine) and click "Load local model".
Here's an animated demo (recorded in real-time, I didn't speed this up):
I pushed a branch with those changes here. The next step would be to modify this to support other models in addition to the Llama 3.2 demo, but I'm pleased to have got to this proof of concept with so little work beyond throwing some prompts at Codex to see if it could figure it out.
According to the Codex /status command this used 169,818 input tokens, 17,112 output tokens and 1,176,320 cached input tokens. At current GPT-5 token pricing ($1.25/million input, $0.125/million cached input, $10/million output) that would cost 53.942 cents, but Codex CLI hooks into my existing $20/month ChatGPT Plus plan so this was bundled into that.
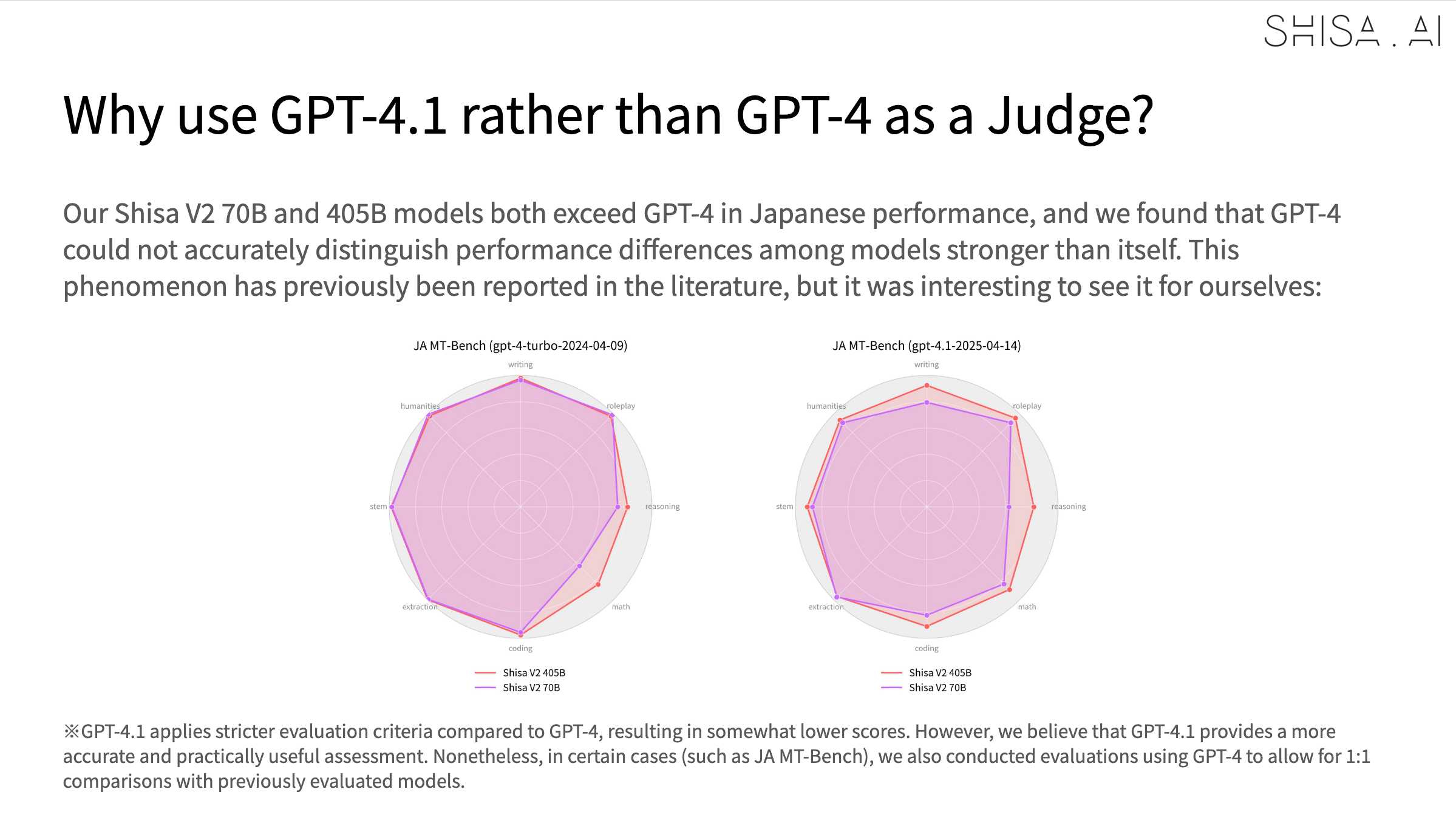
Shisa V2 405B: Japan’s Highest Performing LLM. Leonard Lin and Adam Lensenmayer have been working on Shisa for a while. They describe their latest release as "Japan's Highest Performing LLM".
Shisa V2 405B is the highest-performing LLM ever developed in Japan, and surpasses GPT-4 (0603) and GPT-4 Turbo (2024-04-09) in our eval battery. (It also goes toe-to-toe with GPT-4o (2024-11-20) and DeepSeek-V3 (0324) on Japanese MT-Bench!)
This 405B release is a follow-up to the six smaller Shisa v2 models they released back in April, which took a similar approach to DeepSeek-R1 in producing different models that each extended different existing base model from Llama, Qwen, Mistral and Phi-4.
The new 405B model uses Llama 3.1 405B Instruct as a base, and is available under the Llama 3.1 community license.
Shisa is a prominent example of Sovereign AI - the ability for nations to build models that reflect their own language and culture:
We strongly believe that it’s important for homegrown AI to be developed both in Japan (and globally!), and not just for the sake of cultural diversity and linguistic preservation, but also for data privacy and security, geopolitical resilience, and ultimately, independence.
We believe the open-source approach is the only realistic way to achieve sovereignty in AI, not just for Japan, or even for nation states, but for the global community at large.
The accompanying overview report has some fascinating details:
Training the 405B model was extremely difficult. Only three other groups that we know of: Nous Research, Bllossom, and AI2 have published Llama 405B full fine-tunes. [...] We implemented every optimization at our disposal including: DeepSpeed ZeRO-3 parameter and activation offloading, gradient accumulation, 8-bit paged optimizer, and sequence parallelism. Even so, the 405B model still barely fit within the H100’s memory limits
In addition to the new model the Shisa team have published shisa-ai/shisa-v2-sharegpt, 180,000 records which they describe as "a best-in-class synthetic dataset, freely available for use to improve the Japanese capabilities of any model. Licensed under Apache 2.0".
An interesting note is that they found that since Shisa out-performs GPT-4 at Japanese that model was no longer able to help with evaluation, so they had to upgrade to GPT-4.1:
You also mentioned the whole Chatbot Arena thing, which I think is interesting and points to the challenge around how you do benchmarking. How do you know what models are good for which things?
One of the things we've generally tried to do over the last year is anchor more of our models in our Meta AI product north star use cases. The issue with open source benchmarks, and any given thing like the LM Arena stuff, is that they’re often skewed toward a very specific set of uses cases, which are often not actually what any normal person does in your product. [...]
So we're trying to anchor our north star on the product value that people report to us, what they say that they want, and what their revealed preferences are, and using the experiences that we have. Sometimes these benchmarks just don't quite line up. I think a lot of them are quite easily gameable.
On the Arena you'll see stuff like Sonnet 3.7, which is a great model, and it's not near the top. It was relatively easy for our team to tune a version of Llama 4 Maverick that could be way at the top. But the version we released, the pure model, actually has no tuning for that at all, so it's further down. So you just need to be careful with some of these benchmarks. We're going to index primarily on the products.
— Mark Zuckerberg, on Dwarkesh Patel's podcast
Now that Llama has very real competition in open weight models (Gemma 3, latest Mistrals, DeepSeek, Qwen) I think their janky license is becoming much more of a liability for them. It's just limiting enough that it could be the deciding factor for using something else.
Maybe Meta’s Llama claims to be open source because of the EU AI act

I encountered a theory a while ago that one of the reasons Meta insist on using the term “open source” for their Llama models despite the Llama license not actually conforming to the terms of the Open Source Definition is that the EU’s AI act includes special rules for open source models without requiring OSI compliance.
[... 852 words]We've seen questions from the community about the latest release of Llama-4 on Arena. To ensure full transparency, we're releasing 2,000+ head-to-head battle results for public review. [...]
In addition, we're also adding the HF version of Llama-4-Maverick to Arena, with leaderboard results published shortly. Meta’s interpretation of our policy did not match what we expect from model providers. Meta should have made it clearer that “Llama-4-Maverick-03-26-Experimental” was a customized model to optimize for human preference. As a result of that we are updating our leaderboard policies to reinforce our commitment to fair, reproducible evaluations so this confusion doesn’t occur in the future.
[...] The disappointing releases of both GPT-4.5 and Llama 4 have shown that if you don't train a model to reason with reinforcement learning, increasing its size no longer provides benefits.
Reinforcement learning is limited only to domains where a reward can be assigned to the generation result. Until recently, these domains were math, logic, and code. Recently, these domains have also included factual question answering, where, to find an answer, the model must learn to execute several searches. This is how these "deep search" models have likely been trained.
If your business idea isn't in these domains, now is the time to start building your business-specific dataset. The potential increase in generalist models' skills will no longer be a threat.
Initial impressions of Llama 4
Dropping a model release as significant as Llama 4 on a weekend is plain unfair! So far the best place to learn about the new model family is this post on the Meta AI blog. They’ve released two new models today: Llama 4 Maverick is a 400B model (128 experts, 17B active parameters), text and image input with a 1 million token context length. Llama 4 Scout is 109B total parameters (16 experts, 17B active), also multi-modal and with a claimed 10 million token context length—an industry first.
[... 1,468 words]The Llama series have been re-designed to use state of the art mixture-of-experts (MoE) architecture and natively trained with multimodality. We’re dropping Llama 4 Scout & Llama 4 Maverick, and previewing Llama 4 Behemoth.
📌 Llama 4 Scout is highest performing small model with 17B activated parameters with 16 experts. It’s crazy fast, natively multimodal, and very smart. It achieves an industry leading 10M+ token context window and can also run on a single GPU!
📌 Llama 4 Maverick is the best multimodal model in its class, beating GPT-4o and Gemini 2.0 Flash across a broad range of widely reported benchmarks, while achieving comparable results to the new DeepSeek v3 on reasoning and coding – at less than half the active parameters. It offers a best-in-class performance to cost ratio with an experimental chat version scoring ELO of 1417 on LMArena. It can also run on a single host!
📌 Previewing Llama 4 Behemoth, our most powerful model yet and among the world’s smartest LLMs. Llama 4 Behemoth outperforms GPT4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on several STEM benchmarks. Llama 4 Behemoth is still training, and we’re excited to share more details about it even while it’s still in flight.
— Ahmed Al-Dahle, VP and Head of GenAI at Meta
llm-ollama 0.9.0.
This release of the llm-ollama plugin adds support for schemas, thanks to a PR by Adam Compton.
Ollama provides very robust support for this pattern thanks to their structured outputs feature, which works across all of the models that they support by intercepting the logic that outputs the next token and restricting it to only tokens that would be valid in the context of the provided schema.
With Ollama and llm-ollama installed you can run even run structured schemas against vision prompts for local models. Here's one against Ollama's llama3.2-vision:
llm -m llama3.2-vision:latest \
'describe images' \
--schema 'species,description,count int' \
-a https://static.simonwillison.net/static/2025/two-pelicans.jpg
I got back this:
{
"species": "Pelicans",
"description": "The image features a striking brown pelican with its distinctive orange beak, characterized by its large size and impressive wingspan.",
"count": 1
}
(Actually a bit disappointing, as there are two pelicans and their beaks are brown.)
{kind=link}
Llama 4 is making great progress in training. Llama 4 mini is done with pre-training and our reasoning models and larger model are looking good too. Our goal with Llama 3 was to make open source competitive with closed models, and our goal for Llama 4 is to lead. Llama 4 will be natively multimodal -- it's an omni-model -- and it will have agentic capabilities, so it's going to be novel and it's going to unlock a lot of new use cases.
— Mark Zuckerberg, on Meta's quarterly earnings report
2024
Open WebUI. I tried out this open source (MIT licensed, JavaScript and Python) localhost UI for accessing LLMs today for the first time. It's very nicely done.
I ran it with uvx like this:
uvx --python 3.11 open-webui serve
On first launch it installed a bunch of dependencies and then downloaded 903MB to ~/.cache/huggingface/hub/models--sentence-transformers--all-MiniLM-L6-v2 - a copy of the all-MiniLM-L6-v2 embedding model, presumably for its RAG feature.
It then presented me with a working Llama 3.2:3b chat interface, which surprised me because I hadn't spotted it downloading that model. It turns out that was because I have Ollama running on my laptop already (with several models, including Llama 3.2:3b, already installed) - and Open WebUI automatically detected Ollama and gave me access to a list of available models.
I found a "knowledge" section and added all of the Datasette documentation (by dropping in the .rst files from the docs) - and now I can type # in chat to search for a file, add that to the context and then ask questions about it directly.
I selected the spatialite.rst.txt file, prompted it with "How do I use SpatiaLite with Datasette" and got back this:
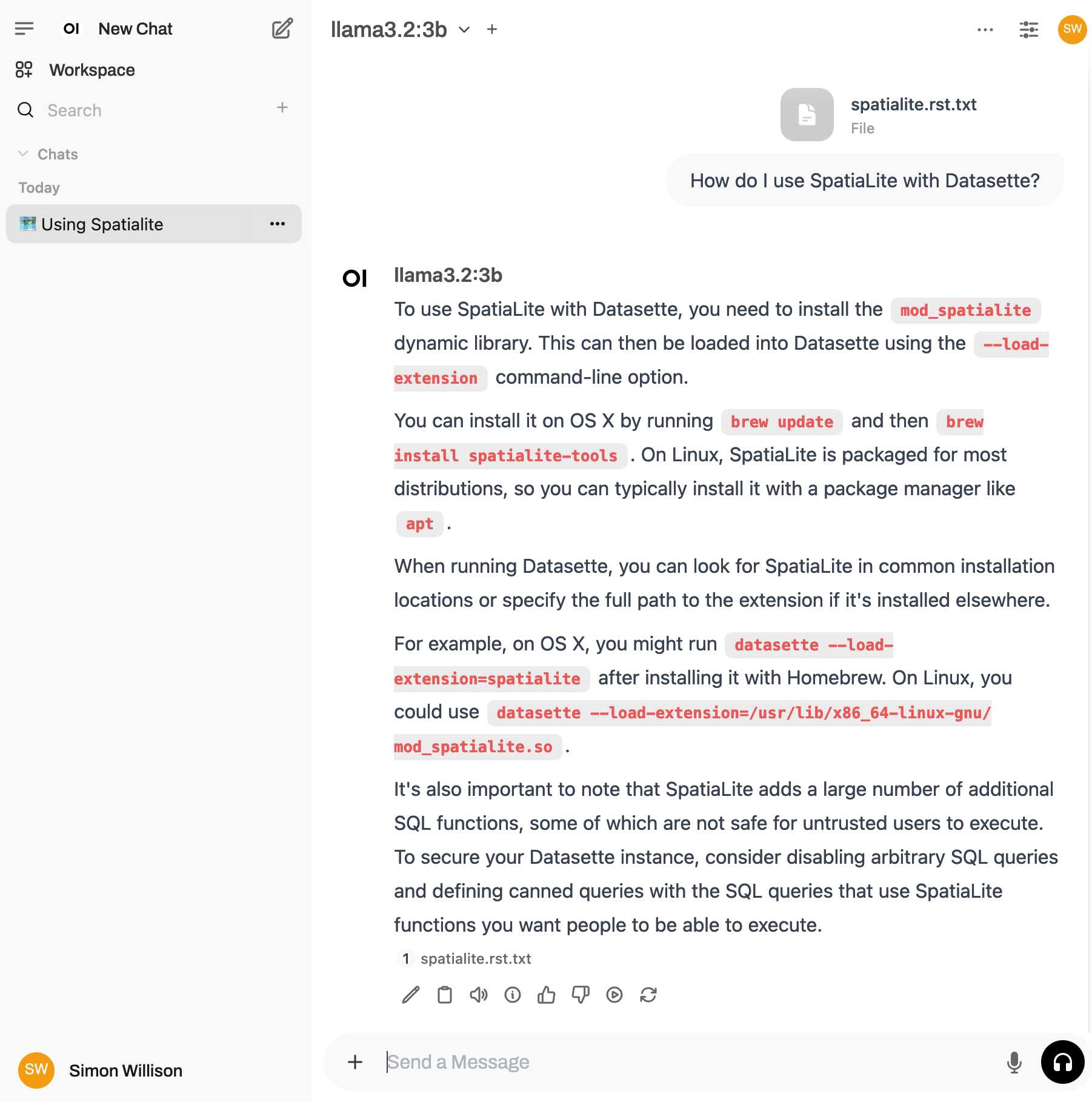
That's honestly a very solid answer, especially considering the Llama 3.2 3B model from Ollama is just a 1.9GB file! It's impressive how well that model can handle basic Q&A and summarization against text provided to it - it somehow has a 128,000 token context size.
Open WebUI has a lot of other tricks up its sleeve: it can talk to API models such as OpenAI directly, has optional integrations with web search and custom tools and logs every interaction to a SQLite database. It also comes with extensive documentation.
DeepSeek_V3.pdf (via) The DeepSeek v3 paper (and model card) are out, after yesterday's mysterious release of the undocumented model weights.
Plenty of interesting details in here. The model pre-trained on 14.8 trillion "high-quality and diverse tokens" (not otherwise documented).
Following this, we conduct post-training, including Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) on the base model of DeepSeek-V3, to align it with human preferences and further unlock its potential. During the post-training stage, we distill the reasoning capability from the DeepSeek-R1 series of models, and meanwhile carefully maintain the balance between model accuracy and generation length.
By far the most interesting detail though is how much the training cost. DeepSeek v3 trained on 2,788,000 H800 GPU hours at an estimated cost of $5,576,000. For comparison, Meta AI's Llama 3.1 405B (smaller than DeepSeek v3's 685B parameters) trained on 11x that - 30,840,000 GPU hours, also on 15 trillion tokens.
DeepSeek v3 benchmarks comparably to Claude 3.5 Sonnet, indicating that it's now possible to train a frontier-class model (at least for the 2024 version of the frontier) for less than $6 million!
For reference, this level of capability is supposed to require clusters of closer to 16K GPUs, the ones being brought up today are more around 100K GPUs. E.g. Llama 3 405B used 30.8M GPU-hours, while DeepSeek-V3 looks to be a stronger model at only 2.8M GPU-hours (~11X less compute). If the model also passes vibe checks (e.g. LLM arena rankings are ongoing, my few quick tests went well so far) it will be a highly impressive display of research and engineering under resource constraints.
DeepSeek also announced their API pricing. From February 8th onwards:
Input: $0.27/million tokens ($0.07/million tokens with cache hits)
Output: $1.10/million tokens
Claude 3.5 Sonnet is currently $3/million for input and $15/million for output, so if the models are indeed of equivalent quality this is a dramatic new twist in the ongoing LLM pricing wars.
I can now run a GPT-4 class model on my laptop

Meta’s new Llama 3.3 70B is a genuinely GPT-4 class Large Language Model that runs on my laptop.
[... 2,905 words]Meta AI release Llama 3.3. This new Llama-3.3-70B-Instruct model from Meta AI makes some bold claims:
This model delivers similar performance to Llama 3.1 405B with cost effective inference that’s feasible to run locally on common developer workstations.
I have 64GB of RAM in my M2 MacBook Pro, so I'm looking forward to trying a slightly quantized GGUF of this model to see if I can run it while still leaving some memory free for other applications.
Update: Ollama have a 43GB GGUF available now. And here's an MLX 8bit version and other MLX quantizations.
Llama 3.3 has 70B parameters, a 128,000 token context length and was trained to support English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
The model card says that the training data was "A new mix of publicly available online data" - 15 trillion tokens with a December 2023 cut-off.
They used "39.3M GPU hours of computation on H100-80GB (TDP of 700W) type hardware" which they calculate as 11,390 tons CO2eq. I believe that's equivalent to around 20 fully loaded passenger flights from New York to London (at ~550 tons per flight).
Update 19th January 2025: On further consideration I no longer trust my estimate here: it's surprisingly hard to track down reliable numbers but I think the total CO2 used by those flights may be more in the order of 200-400 tons, so my estimate for Llama 3.3 70B should have been more in the order of between 28 and 56 flights. Don't trust those numbers either though!
Ollama: Llama 3.2 Vision. Ollama released version 0.4 last week with support for Meta's first Llama vision model, Llama 3.2.
If you have Ollama installed you can fetch the 11B model (7.9 GB) like this:
ollama pull llama3.2-vision
Or the larger 90B model (55GB download, likely needs ~88GB of RAM) like this:
ollama pull llama3.2-vision:90b
I was delighted to learn that Sukhbinder Singh had already contributed support for LLM attachments to Sergey Alexandrov's llm-ollama plugin, which means the following works once you've pulled the models:
llm install --upgrade llm-ollama
llm -m llama3.2-vision:latest 'describe' \
-a https://static.simonwillison.net/static/2024/pelican.jpg
This image features a brown pelican standing on rocks, facing the camera and positioned to the left of center. The bird's long beak is a light brown color with a darker tip, while its white neck is adorned with gray feathers that continue down to its body. Its legs are also gray.
In the background, out-of-focus boats and water are visible, providing context for the pelican's environment.

That's not a bad description of this image, especially for a 7.9GB model that runs happily on my MacBook Pro.
Nous Hermes 3. The Nous Hermes family of fine-tuned models have a solid reputation. Their most recent release came out in August, based on Meta's Llama 3.1:
Our training data aggressively encourages the model to follow the system and instruction prompts exactly and in an adaptive manner. Hermes 3 was created by fine-tuning Llama 3.1 8B, 70B and 405B, and training on a dataset of primarily synthetically generated responses. The model boasts comparable and superior performance to Llama 3.1 while unlocking deeper capabilities in reasoning and creativity.
The model weights are on Hugging Face, including GGUF versions of the 70B and 8B models. Here's how to try the 8B model (a 4.58GB download) using the llm-gguf plugin:
llm install llm-gguf
llm gguf download-model 'https://huggingface.co/NousResearch/Hermes-3-Llama-3.1-8B-GGUF/resolve/main/Hermes-3-Llama-3.1-8B.Q4_K_M.gguf' -a Hermes-3-Llama-3.1-8B
llm -m Hermes-3-Llama-3.1-8B 'hello in spanish'
Nous Research partnered with Lambda Labs to provide inference APIs. It turns out Lambda host quite a few models now, currently providing free inference to users with an API key.
I just released the first alpha of a llm-lambda-labs plugin. You can use that to try the larger 405b model (very hard to run on a consumer device) like this:
llm install llm-lambda-labs
llm keys set lambdalabs
# Paste key here
llm -m lambdalabs/hermes3-405b 'short poem about a pelican with a twist'
Here's the source code for the new plugin, which I based on llm-mistral. The plugin uses httpx-sse to consume the stream of tokens from the API.
Cerebras Coder (via) Val Town founder Steve Krouse has been building demos on top of the Cerebras API that runs Llama3.1-70b at 2,000 tokens/second.
Having a capable LLM with that kind of performance turns out to be really interesting. Cerebras Coder is a demo that implements Claude Artifact-style on-demand JavaScript apps, and having it run at that speed means changes you request are visible within less than a second:
Steve's implementation (created with the help of Townie, the Val Town code assistant) demonstrates the simplest possible version of an iframe sandbox:
<iframe
srcDoc={code}
sandbox="allow-scripts allow-modals allow-forms allow-popups allow-same-origin allow-top-navigation allow-downloads allow-presentation allow-pointer-lock"
/>
Where code is populated by a setCode(...) call inside a React component.
The most interesting applications of LLMs continue to be where they operate in a tight loop with a human - this can make those review loops potentially much faster and more productive.
Pelicans on a bicycle. I decided to roll out my own LLM benchmark: how well can different models render an SVG of a pelican riding a bicycle?
I chose that because a) I like pelicans and b) I'm pretty sure there aren't any pelican on a bicycle SVG files floating around (yet) that might have already been sucked into the training data.
My prompt:
Generate an SVG of a pelican riding a bicycle
I've run it through 16 models so far - from OpenAI, Anthropic, Google Gemini and Meta (Llama running on Cerebras), all using my LLM CLI utility. Here's my (Claude assisted) Bash script: generate-svgs.sh
Here's Claude 3.5 Sonnet (2024-06-20) and Claude 3.5 Sonnet (2024-10-22):


Gemini 1.5 Flash 001 and Gemini 1.5 Flash 002:


GPT-4o mini and GPT-4o:


o1-mini and o1-preview:


Cerebras Llama 3.1 70B and Llama 3.1 8B:


And a special mention for Gemini 1.5 Flash 8B:

The rest of them are linked from the README.
Running Llama 3.2 Vision and Phi-3.5 Vision on a Mac with mistral.rs
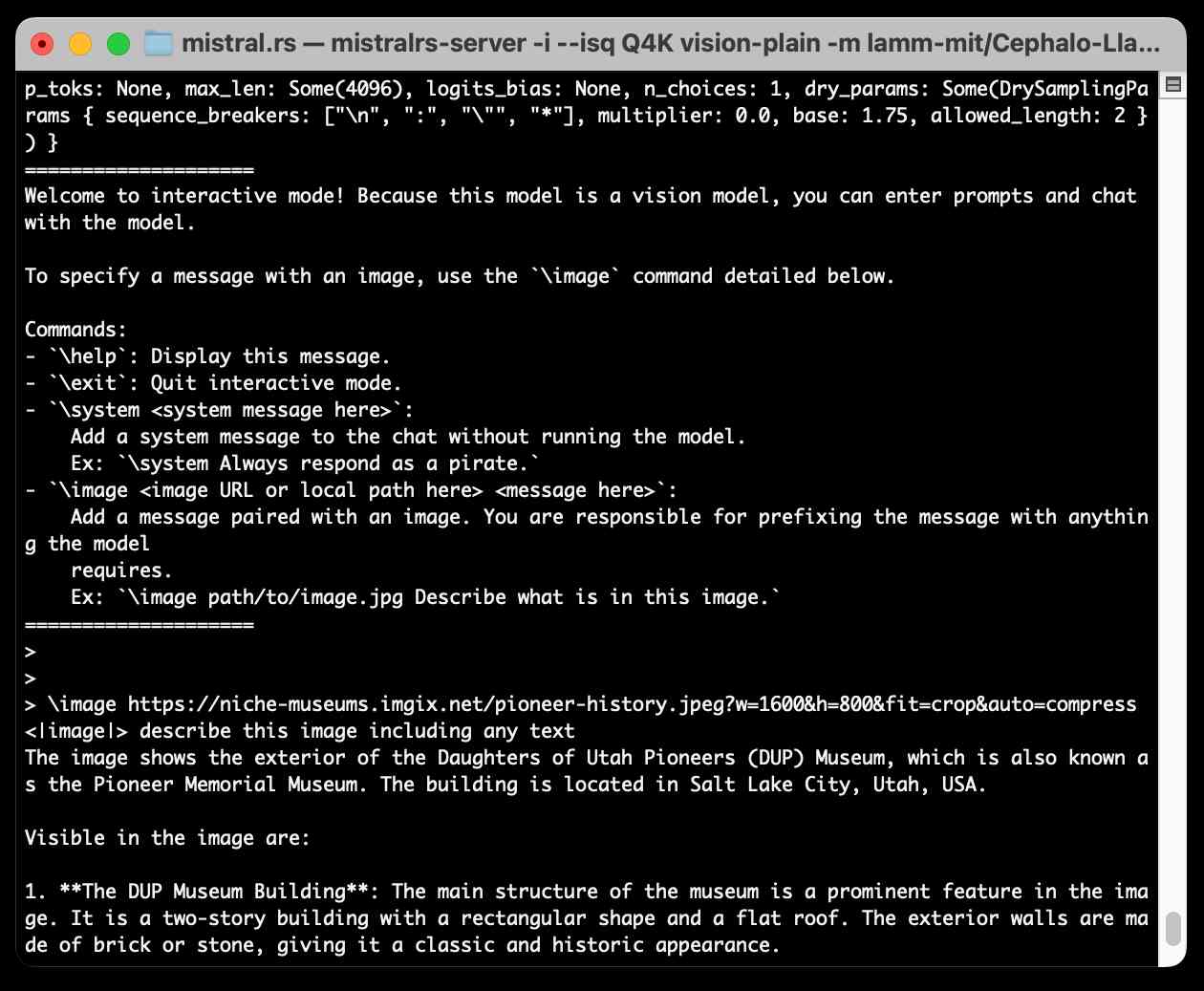
mistral.rs is an LLM inference library written in Rust by Eric Buehler. Today I figured out how to use it to run the Llama 3.2 Vision and Phi-3.5 Vision models on my Mac.
[... 1,231 words]llama-3.2-webgpu (via) Llama 3.2 1B is a really interesting models, given its 128,000 token input and its tiny size (barely more than a GB).
This page loads a 1.24GB q4f16 ONNX build of the Llama-3.2-1B-Instruct model and runs it with a React-powered chat interface directly in the browser, using Transformers.js and WebGPU. Source code for the demo is here.
It worked for me just now in Chrome; in Firefox and Safari I got a “WebGPU is not supported by this browser” error message.
Llama 3.2. In further evidence that AI labs are terrible at naming things, Llama 3.2 is a huge upgrade to the Llama 3 series - they've released their first multi-modal vision models!
Today, we’re releasing Llama 3.2, which includes small and medium-sized vision LLMs (11B and 90B), and lightweight, text-only models (1B and 3B) that fit onto edge and mobile devices, including pre-trained and instruction-tuned versions.
The 1B and 3B text-only models are exciting too, with a 128,000 token context length and optimized for edge devices (Qualcomm and MediaTek hardware get called out specifically).
Meta partnered directly with Ollama to help with distribution, here's the Ollama blog post. They only support the two smaller text-only models at the moment - this command will get the 3B model (2GB):
ollama run llama3.2
And for the 1B model (a 1.3GB download):
ollama run llama3.2:1b
I had to first upgrade my Ollama by clicking on the icon in my macOS task tray and selecting "Restart to update".
The two vision models are coming to Ollama "very soon".
Once you have fetched the Ollama model you can access it from my LLM command-line tool like this:
pipx install llm
llm install llm-ollama
llm chat -m llama3.2:1b
I tried running my djp codebase through that tiny 1B model just now and got a surprisingly good result - by no means comprehensive, but way better than I would ever expect from a model of that size:
files-to-prompt **/*.py -c | llm -m llama3.2:1b --system 'describe this code'
Here's a portion of the output:
The first section defines several test functions using the
@djp.hookimpldecorator from the djp library. These hook implementations allow you to intercept and manipulate Django's behavior.
test_middleware_order: This function checks that the middleware order is correct by comparing theMIDDLEWAREsetting with a predefined list.test_middleware: This function tests various aspects of middleware:- It retrieves the response from the URL
/from-plugin/using theClientobject, which simulates a request to this view.- It checks that certain values are present in the response:
X-DJP-Middleware-AfterX-DJP-MiddlewareX-DJP-Middleware-Before[...]
I found the GGUF file that had been downloaded by Ollama in my ~/.ollama/models/blobs directory. The following command let me run that model directly in LLM using the llm-gguf plugin:
llm install llm-gguf
llm gguf register-model ~/.ollama/models/blobs/sha256-74701a8c35f6c8d9a4b91f3f3497643001d63e0c7a84e085bed452548fa88d45 -a llama321b
llm chat -m llama321b
Meta themselves claim impressive performance against other existing models:
Our evaluation suggests that the Llama 3.2 vision models are competitive with leading foundation models, Claude 3 Haiku and GPT4o-mini on image recognition and a range of visual understanding tasks. The 3B model outperforms the Gemma 2 2.6B and Phi 3.5-mini models on tasks such as following instructions, summarization, prompt rewriting, and tool-use, while the 1B is competitive with Gemma.
Here's the Llama 3.2 collection on Hugging Face. You need to accept the new Llama 3.2 Community License Agreement there in order to download those models.
You can try the four new models out via the Chatbot Arena - navigate to "Direct Chat" there and select them from the dropdown menu. You can upload images directly to the chat there to try out the vision features.
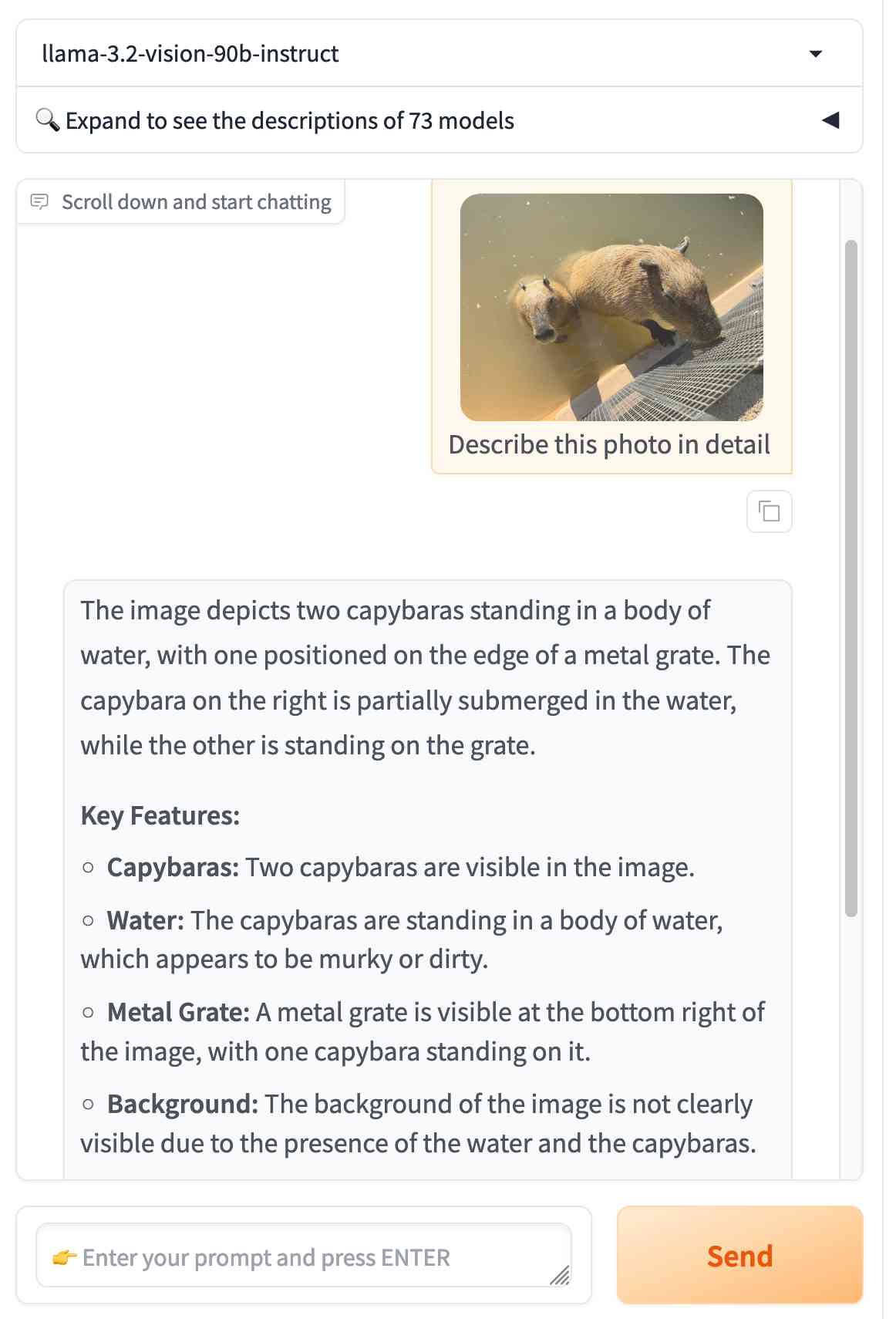
Cerebras Inference: AI at Instant Speed (via) New hosted API for Llama running at absurdly high speeds: "1,800 tokens per second for Llama3.1 8B and 450 tokens per second for Llama3.1 70B".
How are they running so fast? Custom hardware. Their WSE-3 is 57x physically larger than an NVIDIA H100, and has 4 trillion transistors, 900,000 cores and 44GB of memory all on one enormous chip.
Their live chat demo just returned me a response at 1,833 tokens/second. Their API currently has a waitlist.
One interesting observation is the impact of environmental factors on training performance at scale. For Llama 3 405B , we noted a diurnal 1-2% throughput variation based on time-of-day. This fluctuation is the result of higher mid-day temperatures impacting GPU dynamic voltage and frequency scaling.
During training, tens of thousands of GPUs may increase or decrease power consumption at the same time, for example, due to all GPUs waiting for checkpointing or collective communications to finish, or the startup or shutdown of the entire training job. When this happens, it can result in instant fluctuations of power consumption across the data center on the order of tens of megawatts, stretching the limits of the power grid. This is an ongoing challenge for us as we scale training for future, even larger Llama models.
llm-gguf. I just released a new alpha plugin for LLM which adds support for running models from Meta's new Llama 3.1 family that have been packaged as GGUF files - it should work for other GGUF chat models too.
If you've already installed LLM the following set of commands should get you setup with Llama 3.1 8B:
llm install llm-gguf
llm gguf download-model \
https://huggingface.co/lmstudio-community/Meta-Llama-3.1-8B-Instruct-GGUF/resolve/main/Meta-Llama-3.1-8B-Instruct-Q4_K_M.gguf \
--alias llama-3.1-8b-instruct --alias l31i
This will download a 4.92GB GGUF from lmstudio-community/Meta-Llama-3.1-8B-Instruct-GGUF on Hugging Face and save it (at least on macOS) to your ~/Library/Application Support/io.datasette.llm/gguf/models folder.
Once installed like that, you can run prompts through the model like so:
llm -m l31i "five great names for a pet lemur"
Or use the llm chat command to keep the model resident in memory and run an interactive chat session with it:
llm chat -m l31i
I decided to ship a new alpha plugin rather than update my existing llm-llama-cpp plugin because that older plugin has some design decisions baked in from the Llama 2 release which no longer make sense, and having a fresh plugin gave me a fresh slate to adopt the latest features from the excellent underlying llama-cpp-python library by Andrei Betlen.
I believe the Llama 3.1 release will be an inflection point in the industry where most developers begin to primarily use open source, and I expect that approach to only grow from here.
Introducing Llama 3.1: Our most capable models to date. We've been waiting for the largest release of the Llama 3 model for a few months, and now we're getting a whole new model family instead.
Meta are calling Llama 3.1 405B "the first frontier-level open source AI model" and it really is benchmarking in that GPT-4+ class, competitive with both GPT-4o and Claude 3.5 Sonnet.
I'm equally excited by the new 8B and 70B 3.1 models - both of which now support a 128,000 token context and benchmark significantly higher than their Llama 3 equivalents. Same-sized models getting more powerful and capable a very reassuring trend. I expect the 8B model (or variants of it) to run comfortably on an array of consumer hardware, and I've run a 70B model on a 64GB M2 in the past.
The 405B model can at least be run on a single server-class node:
To support large-scale production inference for a model at the scale of the 405B, we quantized our models from 16-bit (BF16) to 8-bit (FP8) numerics, effectively lowering the compute requirements needed and allowing the model to run within a single server node.
Meta also made a significant change to the license:
We’ve also updated our license to allow developers to use the outputs from Llama models — including 405B — to improve other models for the first time.
We’re excited about how this will enable new advancements in the field through synthetic data generation and model distillation workflows, capabilities that have never been achieved at this scale in open source.
I'm really pleased to see this. Using models to help improve other models has been a crucial technique in LLM research for over a year now, especially for fine-tuned community models release on Hugging Face. Researchers have mostly been ignoring this restriction, so it's reassuring to see the uncertainty around that finally cleared up.
Lots more details about the new models in the paper The Llama 3 Herd of Models including this somewhat opaque note about the 15 trillion token training data:
Our final data mix contains roughly 50% of tokens corresponding to general knowledge, 25% of mathematical and reasoning tokens, 17% code tokens, and 8% multilingual tokens.
Update: I got the Llama 3.1 8B Instruct model working with my LLM tool via a new plugin, llm-gguf.
Ultravox (via) Ultravox is "a multimodal Speech LLM built around a pretrained Whisper and Llama 3 backbone". It's effectively an openly licensed version of half of the GPT-4o model OpenAI demoed (but did not fully release) a few weeks ago: Ultravox is multimodal for audio input, but still relies on a separate text-to-speech engine for audio output.
You can try it out directly in your browser through this page on AI.TOWN - hit the "Call" button to start an in-browser voice conversation with the model.
I found the demo extremely impressive - really low latency and it was fun and engaging to talk to. Try saying "pretend to be a wise and sarcastic old fox" to kick it into a different personality.
The GitHub repo includes code for both training and inference, and the full model is available from Hugging Face - about 30GB of .safetensors files.
Ultravox says it's licensed under MIT, but I would expect it to also have to inherit aspects of the Llama 3 license since it uses that as a base model.