1,271 posts tagged “python”
The Python programming language.
2025
TIL: Subtests in pytest 9.0.0+. I spotted an interesting new feature in the release notes for pytest 9.0.0: subtests.
I'm a big user of the pytest.mark.parametrize decorator - see Documentation unit tests from 2018 - so I thought it would be interesting to try out subtests and see if they're a useful alternative.
Short version: this parameterized test:
@pytest.mark.parametrize("setting", app.SETTINGS) def test_settings_are_documented(settings_headings, setting): assert setting.name in settings_headings
Becomes this using subtests instead:
def test_settings_are_documented(settings_headings, subtests): for setting in app.SETTINGS: with subtests.test(setting=setting.name): assert setting.name in settings_headings
Why is this better? Two reasons:
- It appears to run a bit faster
- Subtests can be created programatically after running some setup code first
I had Claude Code port several tests to the new pattern. I like it.
Django 6.0 released. Django 6.0 includes a flurry of neat features, but the two that most caught my eye are background workers and template partials.
Background workers started out as DEP (Django Enhancement Proposal) 14, proposed and shepherded by Jake Howard. Jake prototyped the feature in django-tasks and wrote this extensive background on the feature when it landed in core just in time for the 6.0 feature freeze back in September.
Kevin Wetzels published a useful first look at Django's background tasks based on the earlier RC, including notes on building a custom database-backed worker implementation.
Template Partials were implemented as a Google Summer of Code project by Farhan Ali Raza. I really like the design of this. Here's an example from the documentation showing the neat inline attribute which lets you both use and define a partial at the same time:
{# Define and render immediately. #}
{% partialdef user-info inline %}
<div id="user-info-{{ user.username }}">
<h3>{{ user.name }}</h3>
<p>{{ user.bio }}</p>
</div>
{% endpartialdef %}
{# Other page content here. #}
{# Reuse later elsewhere in the template. #}
<section class="featured-authors">
<h2>Featured Authors</h2>
{% for user in featured %}
{% partial user-info %}
{% endfor %}
</section>You can also render just a named partial from a template directly in Python code like this:
return render(request, "authors.html#user-info", {"user": user})
I'm looking forward to trying this out in combination with HTMX.
I asked Claude Code to dig around in my blog's source code looking for places that could benefit from a template partial. Here's the resulting commit that uses them to de-duplicate the display of dates and tags from pages that list multiple types of content, such as my tag pages.
TIL: Dependency groups and uv run.
I wrote up the new pattern I'm using for my various Python project repos to make them as easy to hack on with uv as possible. The trick is to use a PEP 735 dependency group called dev, declared in pyproject.toml like this:
[dependency-groups]
dev = ["pytest"]
With that in place, running uv run pytest will automatically install that development dependency into a new virtual environment and use it to run your tests.
This means you can get started hacking on one of my projects (here datasette-extract) with just these steps:
git clone https://github.com/datasette/datasette-extract
cd datasette-extract
uv run pytest
I also split my uv TILs out into a separate folder. This meant I had to setup redirects for the old paths, so I had Claude Code help build me a new plugin called datasette-redirects and then apply it to my TIL site, including updating the build script to correctly track the creation date of files that had since been renamed.
llm-anthropic 0.22.
New release of my llm-anthropic plugin:
- Support for Claude's new structured outputs feature for Sonnet 4.5 and Opus 4.1. #54
- Support for the web search tool using
-o web_search 1- thanks Nick Powell and Ian Langworth. #30
The plugin previously powered LLM schemas using this tool-call based workaround. That code is still used for Anthropic's older models.
I also figured out uv recipes for running the plugin's test suite in an isolated environment, which are now baked into the new Justfile.
parakeet-mlx. Neat MLX project by Senstella bringing NVIDIA's Parakeet ASR (Automatic Speech Recognition, like Whisper) model to to Apple's MLX framework.
It's packaged as a Python CLI tool, so you can run it like this:
uvx parakeet-mlx default_tc.mp3
The first time I ran this it downloaded a 2.5GB model file.
Once that was fetched it took 53 seconds to transcribe a 65MB 1hr 1m 28s podcast episode (this one) and produced this default_tc.srt file with a timestamped transcript of the audio I fed into it. The quality appears to be very high.
Video + notes on upgrading a Datasette plugin for the latest 1.0 alpha, with help from uv and OpenAI Codex CLI
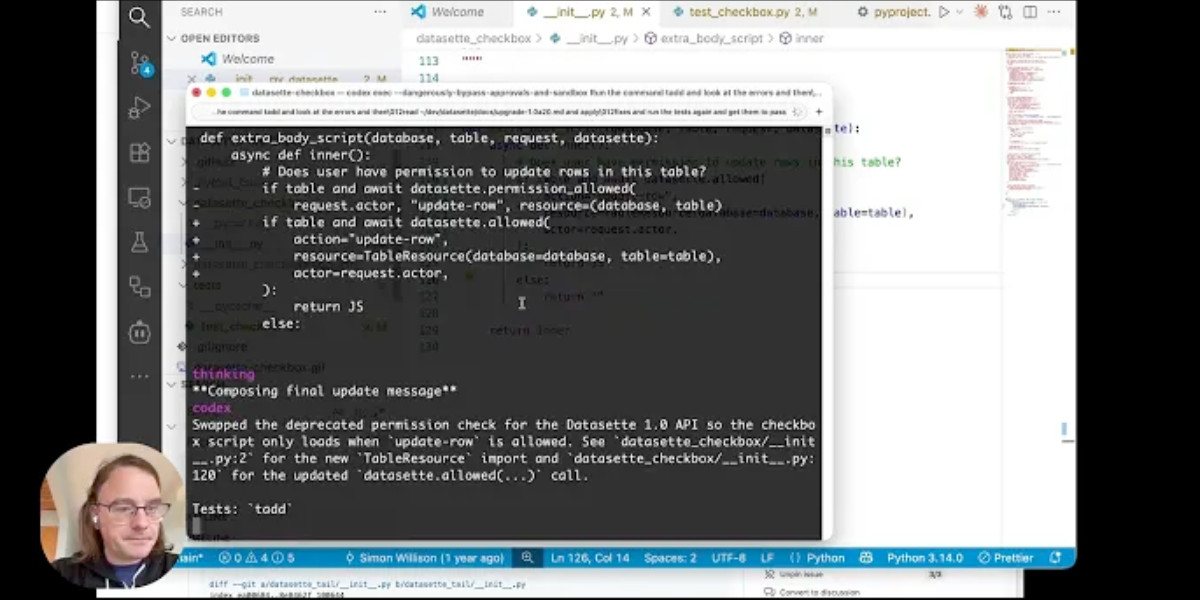
I’m upgrading various plugins for compatibility with the new Datasette 1.0a20 alpha release and I decided to record a video of the process. This post accompanies that video with detailed additional notes.
[... 1,094 words]A new SQL-powered permissions system in Datasette 1.0a20
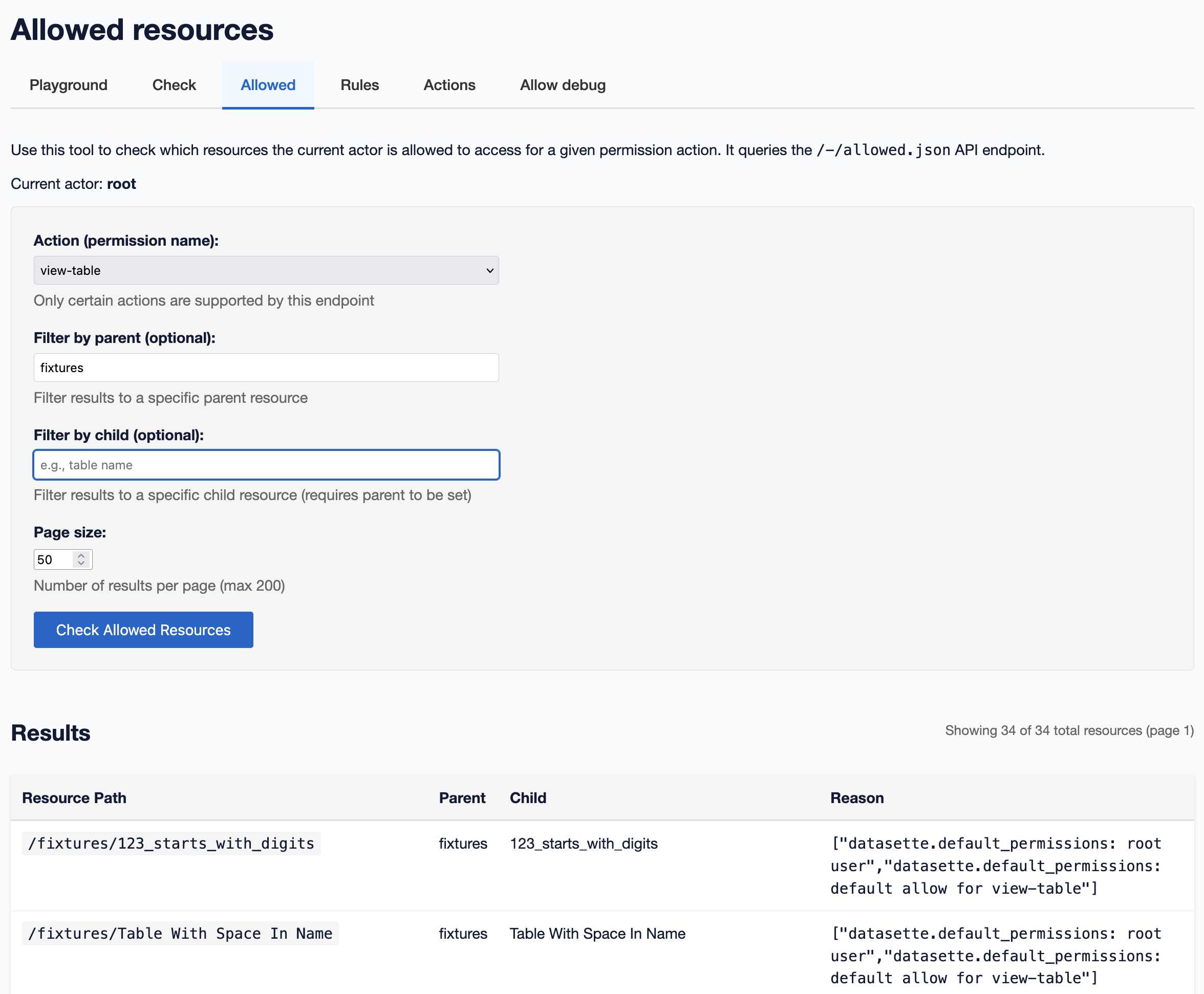
Datasette 1.0a20 is out with the biggest breaking API change on the road to 1.0, improving how Datasette’s permissions system works by migrating permission logic to SQL running in SQLite. This release involved 163 commits, with 10,660 additions and 1,825 deletions, most of which was written with the help of Claude Code.
[... 2,750 words]Dear PEP 810 authors. The Steering Council is happy to unanimously accept "PEP 810, Explicit lazy imports". Congratulations! We appreciate the way you were able to build on and improve the previously discussed (and rejected) attempt at lazy imports as proposed in PEP 690.
— Barry Warsaw, on behalf of the Python Steering Council
PyCon US 2026 call for proposals is now open (via) PyCon US is coming to the US west coast! 2026 and 2027 will both be held in Long Beach, California - the 2026 conference is set for May 13th-19th next year.
The call for proposals just opened. Since we'll be in LA County I'd love to see talks about Python in the entertainment industry - if you know someone who could present on that topic please make sure they know about the CFP!
The deadline for submissions is December 19th 2025. There are two new tracks this year:
PyCon US is introducing two dedicated Talk tracks to the schedule this year, "The Future of AI with Python" and "Trailblazing Python Security". For more information and how to submit your proposal, visit this page.
Now is also a great time to consider sponsoring PyCon - here's the sponsorship prospectus.
Marimo is Joining CoreWeave (via) I don't usually cover startup acquisitions here, but this one feels relevant to several of my interests.
Marimo (previously) provide an open source (Apache 2 licensed) notebook tool for Python, with first-class support for an additional WebAssembly build plus an optional hosted service. It's effectively a reimagining of Jupyter notebooks as a reactive system, where cells automatically update based on changes to other cells - similar to how Observable JavaScript notebooks work.
The first public Marimo release was in January 2024 and the tool has "been in development since 2022" (source).
CoreWeave are a big player in the AI data center space. They started out as an Ethereum mining company in 2017, then pivoted to cloud computing infrastructure for AI companies after the 2018 cryptocurrency crash. They IPOd in March 2025 and today they operate more than 30 data centers worldwide and have announced a number of eye-wateringly sized deals with companies such as Cohere and OpenAI. I found their Wikipedia page very helpful.
They've also been on an acquisition spree this year, including:
- Weights & Biases in March 2025 (deal closed in May), the AI training observability platform.
- OpenPipe in September 2025 - a reinforcement learning platform, authors of the Agent Reinforcement Trainer Apache 2 licensed open source RL framework.
- Monolith AI in October 2025, a UK-based AI model SaaS platform focused on AI for engineering and industrial manufacturing.
- And now Marimo.
Marimo's own announcement emphasizes continued investment in that tool:
Marimo is joining CoreWeave. We’re continuing to build the open-source marimo notebook, while also leveling up molab with serious compute. Our long-term mission remains the same: to build the world’s best open-source programming environment for working with data.
marimo is, and always will be, free, open-source, and permissively licensed.
Give CoreWeave's buying spree only really started this year it's impossible to say how well these acquisitions are likely to play out - they haven't yet established a track record.
The PSF has withdrawn a $1.5 million proposal to US government grant program. The Python Software Foundation was recently "recommended for funding" (NSF terminology) for a $1.5m grant from the US government National Science Foundation to help improve the security of the Python software ecosystem, after an grant application process lead by Seth Larson and Loren Crary.
The PSF's annual budget is less than $6m so this is a meaningful amount of money for the organization!
We were forced to withdraw our application and turn down the funding, thanks to new language that was added to the agreement requiring us to affirm that we "do not, and will not during the term of this financial assistance award, operate any programs that advance or promote DEI, or discriminatory equity ideology in violation of Federal anti-discrimination laws."
Our legal advisors confirmed that this would not just apply to security work covered by the grant - this would apply to all of the PSF's activities.
This was not an option for us. Here's the mission of the PSF:
The mission of the Python Software Foundation is to promote, protect, and advance the Python programming language, and to support and facilitate the growth of a diverse and international community of Python programmers.
If we accepted and spent the money despite this term, there was a very real risk that the money could be clawed back later. That represents an existential risk for the foundation since we would have already spent the money!
I was one of the board members who voted to reject this funding - a unanimous but tough decision. I’m proud to serve on a board that can make difficult decisions like this.
If you'd like to sponsor the PSF you can find out more on our site. I'd love to see a few more of the large AI labs show up on our top-tier visionary sponsors list.
Getting DeepSeek-OCR working on an NVIDIA Spark via brute force using Claude Code

DeepSeek released a new model yesterday: DeepSeek-OCR, a 6.6GB model fine-tuned specifically for OCR. They released it as model weights that run using PyTorch and CUDA. I got it running on the NVIDIA Spark by having Claude Code effectively brute force the challenge of getting it working on that particular hardware.
[... 1,971 words]nanochat (via) Really interesting new project from Andrej Karpathy, described at length in this discussion post.
It provides a full ChatGPT-style LLM, including training, inference and a web Ui, that can be trained for as little as $100:
This repo is a full-stack implementation of an LLM like ChatGPT in a single, clean, minimal, hackable, dependency-lite codebase.
It's around 8,000 lines of code, mostly Python (using PyTorch) plus a little bit of Rust for training the tokenizer.
Andrej suggests renting a 8XH100 NVIDA node for around $24/ hour to train the model. 4 hours (~$100) is enough to get a model that can hold a conversation - almost coherent example here. Run it for 12 hours and you get something that slightly outperforms GPT-2. I'm looking forward to hearing results from longer training runs!
The resulting model is ~561M parameters, so it should run on almost anything. I've run a 4B model on my iPhone, 561M should easily fit on even an inexpensive Raspberry Pi.
The model defaults to training on ~24GB from karpathy/fineweb-edu-100b-shuffle derived from FineWeb-Edu, and then midtrains on 568K examples from SmolTalk (460K), MMLU auxiliary train (100K), and GSM8K (8K), followed by supervised finetuning on 21.4K examples from ARC-Easy (2.3K), ARC-Challenge (1.1K), GSM8K (8K), and SmolTalk (10K).
Here's the code for the web server, which is fronted by this pleasantly succinct vanilla JavaScript HTML+JavaScript frontend.
Update: Sam Dobson pushed a build of the model to sdobson/nanochat on Hugging Face. It's designed to run on CUDA but I pointed Claude Code at a checkout and had it hack around until it figured out how to run it on CPU on macOS, which eventually resulted in this script which I've published as a Gist. You should be able to try out the model using uv like this:
cd /tmp
git clone https://huggingface.co/sdobson/nanochat
uv run https://gist.githubusercontent.com/simonw/912623bf00d6c13cc0211508969a100a/raw/80f79c6a6f1e1b5d4485368ef3ddafa5ce853131/generate_cpu.py \
--model-dir /tmp/nanochat \
--prompt "Tell me about dogs."
I got this (truncated because it ran out of tokens):
I'm delighted to share my passion for dogs with you. As a veterinary doctor, I've had the privilege of helping many pet owners care for their furry friends. There's something special about training, about being a part of their lives, and about seeing their faces light up when they see their favorite treats or toys.
I've had the chance to work with over 1,000 dogs, and I must say, it's a rewarding experience. The bond between owner and pet
simonw/claude-skills. One of the tips I picked up from Jesse Vincent's Claude Code Superpowers post (previously) was this:
Skills are what give your agents Superpowers.
The first time they really popped up on my radar was a few weeks ago when Anthropic rolled out improved Office document creation. When the feature rolled out, I went poking around a bit -- I asked Claude to tell me all about its new skills. And it was only too happy to dish.
In that transcript Jesse asks how the skill system works and Claude replies:
Looking at the skills system, here's how it works:
Current Skills (in
/mnt/skills/public/):
- docx - Word document handling
- pdf - PDF processing and form filling
- pptx - PowerPoint presentations
- xlsx - Excel spreadsheets
This looks like it's part of Claude's brand new Code Interpreter feature! I wrote about that extensively last month, but I missed that there was a /mnt/skills/public/ folder full of fascinating implementation details.
So I fired up a fresh Claude instance (fun fact: Code Interpreter also works in the Claude iOS app now, which it didn't when they first launched) and prompted:
Create a zip file of everything in your /mnt/skills folder
This worked, and gave me a .zip to download. You can run the prompt yourself here, though you'll need to enable the new feature first.
I've pushed the contents of that zip to my new simonw/claude-skills GitHub repo.
So now you can see the prompts Anthropic wrote to enable the creation and manipulation of the following files in their Claude consumer applications:
In each case the prompts spell out detailed instructions for manipulating those file types using Python, using libraries that come pre-installed on Claude's containers.
Skills are more than just prompts though: the repository also includes dozens of pre-written Python scripts for performing common operations.
pdf/scripts/fill_fillable_fields.py for example is a custom CLI tool that uses pypdf to find and then fill in a bunch of PDF form fields, specified as JSON, then render out the resulting combined PDF.
This is a really sophisticated set of tools for document manipulation, and I love that Anthropic have made those visible - presumably deliberately - to users of Claude who know how to ask for them.
TIL: Testing different Python versions with uv with-editable and uv-test.
While tinkering with upgrading various projects to handle Python 3.14 I finally figured out a universal uv recipe for running the tests for the current project in any specified version of Python:
uv run --python 3.14 --isolated --with-editable '.[test]' pytest
This should work in any directory with a pyproject.toml (or even a setup.py) that defines a test set of extra dependencies and uses pytest.
The --with-editable '.[test]' bit ensures that changes you make to that directory will be picked up by future test runs. The --isolated flag ensures no other environments will affect your test run.
I like this pattern so much I built a little shell script that uses it, shown here. Now I can change to any Python project directory and run:
uv-test
Or for a different Python version:
uv-test -p 3.11
I can pass additional pytest options too:
uv-test -p 3.11 -k permissions
Claude can write complete Datasette plugins now
This isn’t necessarily surprising, but it’s worth noting anyway. Claude Sonnet 4.5 is capable of building a full Datasette plugin now.
[... 1,296 words]Python 3.14 Is Here. How Fast Is It?
(via)
Miguel Grinberg uses some basic benchmarks (like fib(40)) to test the new Python 3.14 on Linux and macOS and finds some substantial speedups over Python 3.13 - around 27% faster.
The optional JIT didn't make a meaningful difference to his benchmarks. On a threaded benchmark he got 3.09x speedup with 4 threads using the free threading build - for Python 3.13 the free threading build only provided a 2.2x improvement.
Python 3.14. This year's major Python version, Python 3.14, just made its first stable release!
As usual the what's new in Python 3.14 document is the best place to get familiar with the new release:
The biggest changes include template string literals, deferred evaluation of annotations, and support for subinterpreters in the standard library.
The library changes include significantly improved capabilities for introspection in asyncio, support for Zstandard via a new compression.zstd module, syntax highlighting in the REPL, as well as the usual deprecations and removals, and improvements in user-friendliness and correctness.
Subinterpreters look particularly interesting as a way to use multiple CPU cores to run Python code despite the continued existence of the GIL. If you're feeling brave and your dependencies cooperate you can also use the free-threaded build of Python 3.14 - now officially supported - to skip the GIL entirely.
A new major Python release means an older release hits the end of its support lifecycle - in this case that's Python 3.9. If you maintain open source libraries that target every supported Python versions (as I do) this means features introduced in Python 3.10 can now be depended on! What's new in Python 3.10 lists those - I'm most excited by structured pattern matching (the match/case statement) and the union type operator, allowing int | float | None as a type annotation in place of Optional[Union[int, float]].
If you use uv you can grab a copy of 3.14 using:
uv self update
uv python upgrade 3.14
uvx python@3.14
Or for free-threaded Python 3.1;:
uvx python@3.14t
The uv team wrote about their Python 3.14 highlights in their announcement of Python 3.14's availability via uv.
The GitHub Actions setup-python action includes Python 3.14 now too, so the following YAML snippet in will run tests on all currently supported versions:
strategy:
matrix:
python-version: ["3.10", "3.11", "3.12", "3.13", "3.14"]
steps:
- uses: actions/setup-python@v6
with:
python-version: ${{ matrix.python-version }}
Full example here for one of my many Datasette plugin repos.
gpt-image-1-mini.
OpenAI released a new image model today: gpt-image-1-mini, which they describe as "A smaller image generation model that’s 80% less expensive than the large model."
They released it very quietly - I didn't hear about this in the DevDay keynote but I later spotted it on the DevDay 2025 announcements page.
It wasn't instantly obvious to me how to use this via their API. I ended up vibe coding a Python CLI tool for it so I could try it out.
I dumped the plain text diff version of the commit to the OpenAI Python library titled feat(api): dev day 2025 launches into ChatGPT GPT-5 Thinking and worked with it to figure out how to use the new image model and build a script for it. Here's the transcript and the the openai_image.py script it wrote.
I had it add inline script dependencies, so you can run it with uv like this:
export OPENAI_API_KEY="$(llm keys get openai)"
uv run https://tools.simonwillison.net/python/openai_image.py "A pelican riding a bicycle"
It picked this illustration style without me specifying it:

(This is a very different test from my normal "Generate an SVG of a pelican riding a bicycle" since it's using a dedicated image generator, not having a text-based model try to generate SVG code.)
My tool accepts a prompt, and optionally a filename (if you don't provide one it saves to a filename like /tmp/image-621b29.png).
It also accepts options for model and dimensions and output quality - the --help output lists those, you can see that here.
OpenAI's pricing is a little confusing. The model page claims low quality images should cost around half a cent and medium quality around a cent and a half. It also lists an image token price of $8/million tokens. It turns out there's a default "high" quality setting - most of the images I've generated have reported between 4,000 and 6,000 output tokens, which costs between 3.2 and 4.8 cents.
One last demo, this time using --quality low:
uv run https://tools.simonwillison.net/python/openai_image.py \
'racoon eating cheese wearing a top hat, realistic photo' \
/tmp/racoon-hat-photo.jpg \
--size 1024x1024 \
--output-format jpeg \
--quality low
This saved the following:

And reported this to standard error:
{
"background": "opaque",
"created": 1759790912,
"generation_time_in_s": 20.87331541599997,
"output_format": "jpeg",
"quality": "low",
"size": "1024x1024",
"usage": {
"input_tokens": 17,
"input_tokens_details": {
"image_tokens": 0,
"text_tokens": 17
},
"output_tokens": 272,
"total_tokens": 289
}
}
This took 21s, but I'm on an unreliable conference WiFi connection so I don't trust that measurement very much.
272 output tokens = 0.2 cents so this is much closer to the expected pricing from the model page.
[2 points] Learn basic NumPy operations with an AI tutor! Use an AI chatbot (e.g., ChatGPT, Claude, Gemini, or Stanford AI Playground) to teach yourself how to do basic vector and matrix operations in NumPy (import numpy as np). AI tutors have become exceptionally good at creating interactive tutorials, and this year in CS221, we're testing how they can help you learn fundamentals more interactively than traditional static exercises.
— Stanford CS221 Autumn 2025, Problem 1: Linear Algebra
Anthropic: A postmortem of three recent issues. Anthropic had a very bad month in terms of model reliability:
Between August and early September, three infrastructure bugs intermittently degraded Claude's response quality. We've now resolved these issues and want to explain what happened. [...]
To state it plainly: We never reduce model quality due to demand, time of day, or server load. The problems our users reported were due to infrastructure bugs alone. [...]
We don't typically share this level of technical detail about our infrastructure, but the scope and complexity of these issues justified a more comprehensive explanation.
I'm really glad Anthropic are publishing this in so much detail. Their reputation for serving their models reliably has taken a notable hit.
I hadn't appreciated the additional complexity caused by their mixture of different serving platforms:
We deploy Claude across multiple hardware platforms, namely AWS Trainium, NVIDIA GPUs, and Google TPUs. [...] Each hardware platform has different characteristics and requires specific optimizations.
It sounds like the problems came down to three separate bugs which unfortunately came along very close to each other.
Anthropic also note that their privacy practices made investigating the issues particularly difficult:
The evaluations we ran simply didn't capture the degradation users were reporting, in part because Claude often recovers well from isolated mistakes. Our own privacy practices also created challenges in investigating reports. Our internal privacy and security controls limit how and when engineers can access user interactions with Claude, in particular when those interactions are not reported to us as feedback. This protects user privacy but prevents engineers from examining the problematic interactions needed to identify or reproduce bugs.
The code examples they provide to illustrate a TPU-specific bug show that they use Python and JAX as part of their serving layer.
Announcing the 2025 PSF Board Election Results! I'm happy to share that I've been re-elected for second term on the board of directors of the Python Software Foundation.
Jannis Leidel was also re-elected and Abigail Dogbe and Sheena O’Connell will be joining the board for the first time.
In Python 3.14, I have implemented several changes to fix thread safety of
asyncioand enable it to scale effectively on the free-threaded build of CPython. It is now implemented using lock-free data structures and per-thread state, allowing for highly efficient task management and execution across multiple threads. In the general case of multiple event loops running in parallel, there is no lock contention and performance scales linearly with the number of threads. [...]For a deeper dive into the implementation, check out the internal docs for asyncio.
— Kumar Aditya, Scaling asyncio on Free-Threaded Python
I Replaced Animal Crossing’s Dialogue with a Live LLM by Hacking GameCube Memory (via) Brilliant retro-gaming project by Josh Fonseca, who figured out how to run 2002 Game Cube Animal Crossing in the Dolphin Emulator such that dialog with the characters was instead generated by an LLM.
The key trick was running Python code that scanned the Game Cube memory every 10th of a second looking for instances of dialogue, then updated the memory in-place to inject new dialog.
The source code is in vuciv/animal-crossing-llm-mod on GitHub. I dumped it (via gitingest, ~40,000 tokens) into Claude Opus 4.1 and asked the following:
This interacts with Animal Crossing on the Game Cube. It uses an LLM to replace dialog in the game, but since an LLM takes a few seconds to run how does it spot when it should run a prompt and then pause the game while the prompt is running?
Claude pointed me to the watch_dialogue() function which implements the polling loop.
When it catches the dialogue screen opening it writes out this message instead:
loading_text = ".<Pause [0A]>.<Pause [0A]>.<Pause [0A]><Press A><Clear Text>"
Those <Pause [0A]> tokens cause the came to pause for a few moments before giving the user the option to <Press A> to continue. This gives time for the LLM prompt to execute and return new text which can then be written to the correct memory area for display.
Hacker News commenters spotted some fun prompts in the source code, including this prompt to set the scene:
You are a resident of a town run by Tom Nook. You are beginning to realize your mortgage is exploitative and the economy is unfair. Discuss this with the player and other villagers when appropriate.
And this sequence of prompts that slowly raise the agitation of the villagers about their economic situation over time.
The system actually uses two separate prompts - one to generate responses from characters and another which takes those responses and decorates them with Animal Crossing specific control codes to add pauses, character animations and other neat effects.
My review of Claude’s new Code Interpreter, released under a very confusing name
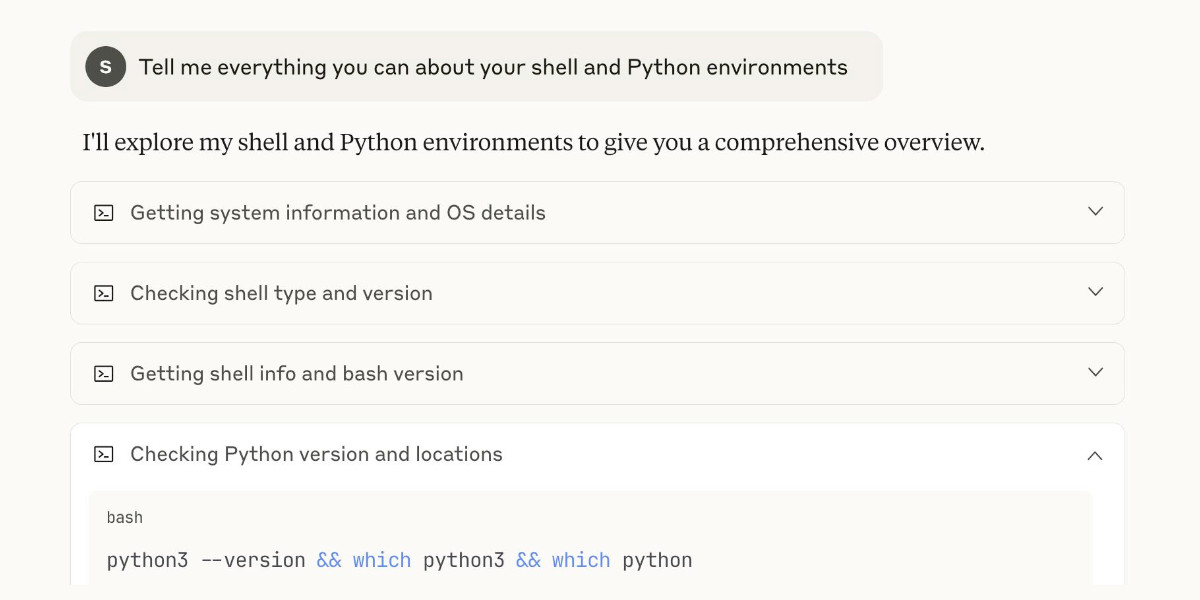
Today on the Anthropic blog: Claude can now create and edit files:
[... 2,771 words]The 2025 PSF Board Election is Open! The Python Software Foundation's annual board member election is taking place right now, with votes (from previously affirmed voting members) accepted from September 2nd, 2:00 pm UTC through Tuesday, September 16th, 2:00 pm UTC.
I've served on the board since 2022 and I'm running for a second term. Here's the opening section of my nomination statement.
Hi, I'm Simon Willison. I've been a board member of the Python Software Foundation since 2022 and I'm running for re-election in 2025.
Last year I wrote a detailed article about Things I’ve learned serving on the board of the Python Software Foundation. I hope to continue learning and sharing what I've learned for a second three-year term.
One of my goals for a second term is to help deepen the relationship between the AI research world and the Python Software Foundation. There is an enormous amount of value being created in the AI space using Python and I would like to see more of that value flow back into the rest of the Python ecosystem.
I see the Python Package Index (PyPI) as one of the most impactful projects of the Python Software Foundation and plan to continue to advocate for further investment in the PyPI team and infrastructure.
As a California resident I'm excited to see PyCon return to the West Coast, and I'm looking forward to getting involved in helping make PyCon 2026 and 2027 in Long Beach, California as successful as possible.
I'm delighted to have been endorsed this year by Al Sweigart, Loren Crary and Christopher Neugebauer. If you are a voting member I hope I have earned your vote this year.
You can watch video introductions from several of the other nominees in this six minute YouTube video and this playlist.
Recreating the Apollo AI adoption rate chart with GPT-5, Python and Pyodide
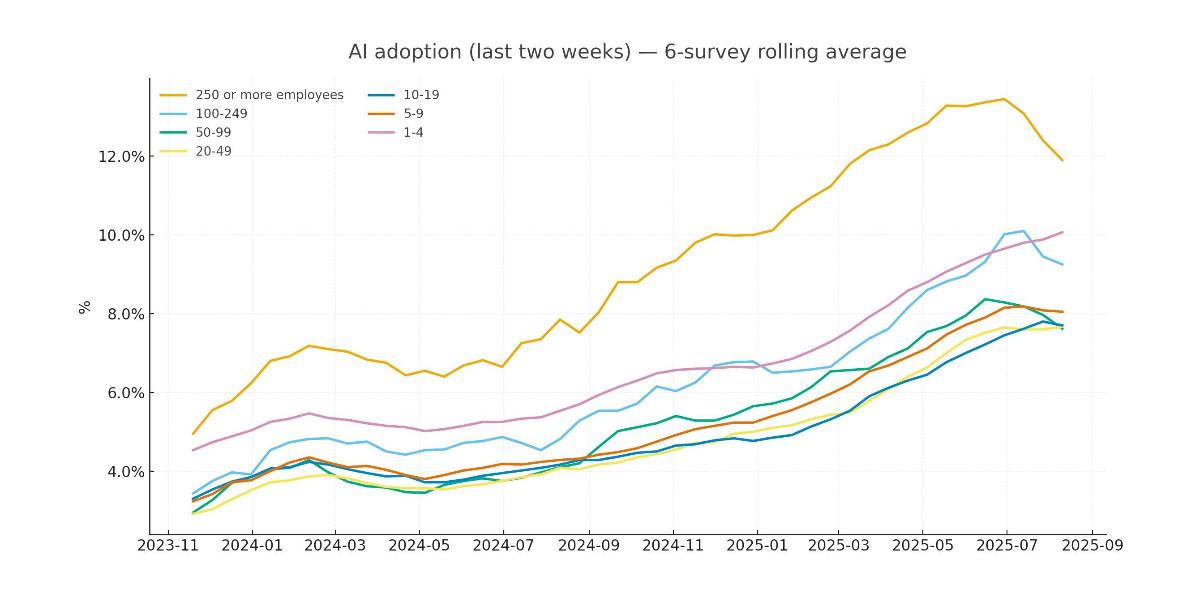
Apollo Global Management’s “Chief Economist” Dr. Torsten Sløk released this interesting chart which appears to show a slowdown in AI adoption rates among large (>250 employees) companies:
[... 2,673 words]Rich Pixels. Neat Python library by Darren Burns adding pixel image support to the Rich terminal library, using tricks to render an image using full or half-height colored blocks.
Here's the key trick - it renders Unicode ▄ (U+2584, "lower half block") characters after setting a foreground and background color for the two pixels it needs to display.
I got GPT-5 to vibe code up a show_image.py terminal command which resizes the provided image to fit the width and height of the current terminal and displays it using Rich Pixels. That script is here, you can run it with uv like this:
uv run https://tools.simonwillison.net/python/show_image.py \
image.jpg
Here's what I got when I ran it against my V&A East Storehouse photo from this post:
![]()
Talk Python: Celebrating Django’s 20th Birthday With Its Creators. I recorded this podcast episode recently to celebrate Django's 20th birthday with Adrian Holovaty, Will Vincent, Jeff Triplet, and Thibaud Colas.
We didn’t know that it was a web framework. We thought it was a tool for building local newspaper websites. [...]
Django’s original tagline was ‘Web development on journalism deadlines’. That’s always been my favorite description of the project.
Python: The Documentary. New documentary about the origins of the Python programming language - 84 minutes long, built around extensive interviews with Guido van Rossum and others who were there at the start and during the subsequent journey.